Diving into Underwater: Segment Anything Model Guided Underwater Salient Instance Segmentation and A Large-scale Dataset

0
Sign in to get full access
Overview
- This paper presents a method for underwater salient instance segmentation using the Segment Anything Model (SAM) as a guidance model.
- The authors also introduce a large-scale dataset called SegUnderwaterSAM for training and evaluating underwater salient instance segmentation models.
Plain English Explanation
The paper focuses on the task of segmenting important or interesting objects in underwater images. This is a challenging problem because underwater environments can be murky, have complex lighting, and contain a wide variety of marine life and other objects.
To address this, the researchers used a powerful AI model called the Segment Anything Model (SAM) to help guide the segmentation process. SAM is a general-purpose segmentation model that can identify objects in images without needing to be specifically trained on that type of object. By using SAM as a starting point, the researchers were able to develop a more effective system for segmenting salient (important) objects in underwater scenes.
In addition, the researchers created a new dataset called SegUnderwaterSAM, which contains a large number of annotated underwater images. This dataset can be used to train and evaluate underwater segmentation models, helping to advance the state of the art in this area.
Overall, this work represents an important step forward in making it easier to automatically identify and extract meaningful objects from underwater imagery, which has applications in fields like marine biology, underwater exploration, and environmental monitoring.
Technical Explanation
The key technical elements of this paper are:
-
Segment Anything Model (SAM) Guidance: The researchers used the pre-trained Segment Anything Model as a starting point for their underwater salient instance segmentation system. SAM is a general-purpose segmentation model that can be applied to a wide variety of objects without needing to be specifically trained on them.
-
SegUnderwaterSAM Dataset: The authors introduced a new large-scale dataset called SegUnderwaterSAM, which contains over 30,000 annotated underwater images. This dataset can be used to train and evaluate underwater salient instance segmentation models.
-
Instance Segmentation Architecture: The researchers developed a specialized instance segmentation architecture that builds on top of SAM. This system uses SAM's outputs as a guide to help it identify and segment salient objects in the underwater scenes.
-
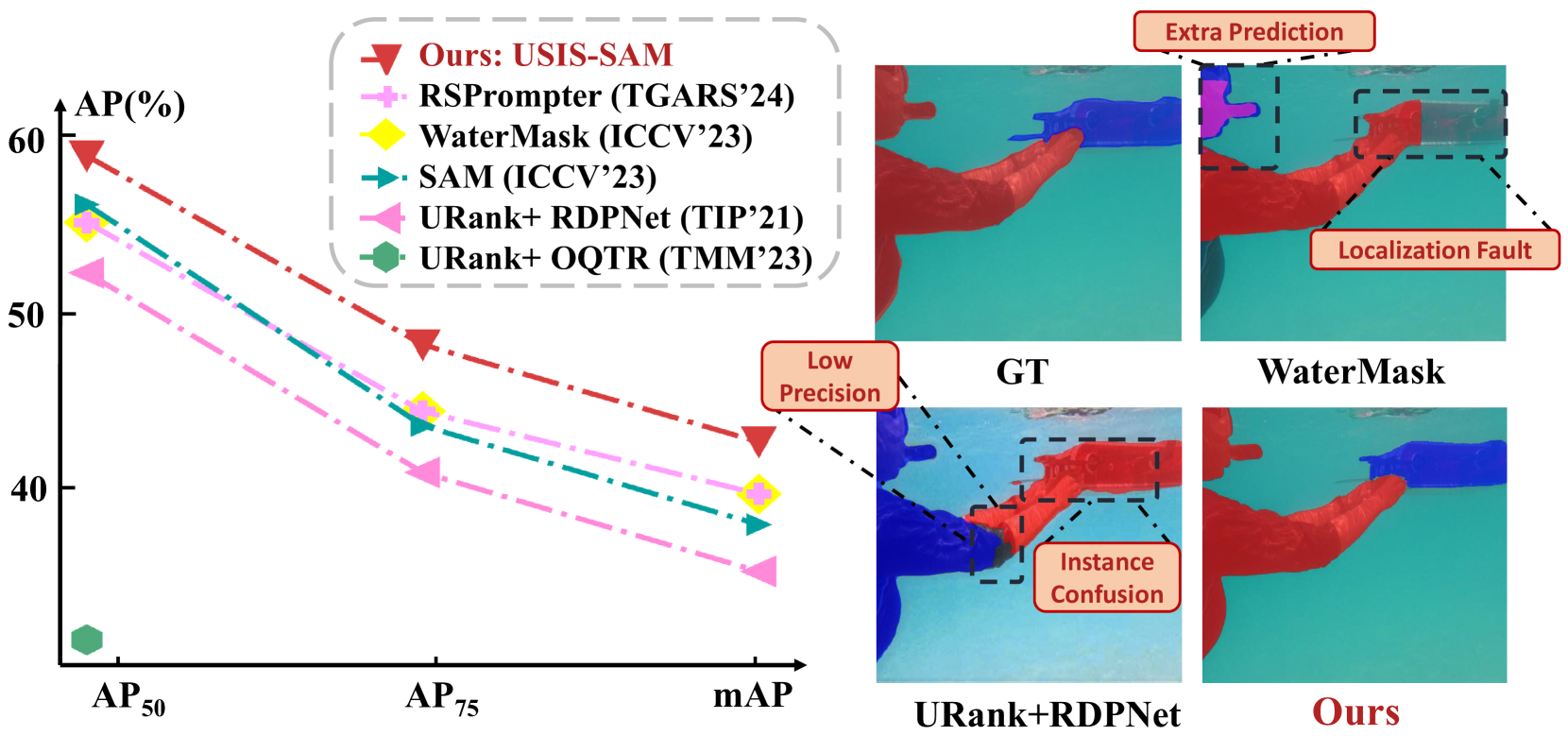
Evaluation: The paper presents extensive experiments evaluating the performance of the proposed system on the SegUnderwaterSAM dataset. The results show that the SAM-guided approach outperforms other state-of-the-art underwater instance segmentation methods.
Critical Analysis
The paper presents a comprehensive and well-designed approach for underwater salient instance segmentation. The use of the Segment Anything Model as a guidance system is a clever and effective strategy, as it allows the researchers to leverage a powerful general-purpose segmentation model without the need for extensive task-specific training.
However, the paper does acknowledge some limitations of the proposed system. For example, the authors note that their approach may struggle with small or occluded objects, and that further research is needed to improve performance in challenging underwater environments.
Additionally, while the SegUnderwaterSAM dataset is a valuable contribution, it would be interesting to see how the system performs on a wider variety of underwater scenes, including those from different geographical regions or with different types of marine life.
Overall, this paper represents an important advance in the field of underwater computer vision, and the SAM-guided approach could have significant implications for a wide range of underwater applications, from marine biology to underwater exploration and monitoring.
Conclusion
This paper presents a novel method for underwater salient instance segmentation that leverages the Segment Anything Model as a guidance system. By combining SAM's powerful general-purpose segmentation capabilities with a specialized instance segmentation architecture, the researchers were able to develop a highly effective system for identifying and extracting meaningful objects from underwater imagery.
The introduction of the SegUnderwaterSAM dataset is also a valuable contribution, as it provides a large-scale resource for training and evaluating underwater segmentation models. Overall, this work represents an important step forward in the field of underwater computer vision, with potential applications in areas like marine biology, underwater exploration, and environmental monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diving into Underwater: Segment Anything Model Guided Underwater Salient Instance Segmentation and A Large-scale Dataset
Shijie Lian, Ziyi Zhang, Hua Li, Wenjie Li, Laurence Tianruo Yang, Sam Kwong, Runmin Cong
With the breakthrough of large models, Segment Anything Model (SAM) and its extensions have been attempted to apply in diverse tasks of computer vision. Underwater salient instance segmentation is a foundational and vital step for various underwater vision tasks, which often suffer from low segmentation accuracy due to the complex underwater circumstances and the adaptive ability of models. Moreover, the lack of large-scale datasets with pixel-level salient instance annotations has impeded the development of machine learning techniques in this field. To address these issues, we construct the first large-scale underwater salient instance segmentation dataset (USIS10K), which contains 10,632 underwater images with pixel-level annotations in 7 categories from various underwater scenes. Then, we propose an Underwater Salient Instance Segmentation architecture based on Segment Anything Model (USIS-SAM) specifically for the underwater domain. We devise an Underwater Adaptive Visual Transformer (UA-ViT) encoder to incorporate underwater domain visual prompts into the segmentation network. We further design an out-of-the-box underwater Salient Feature Prompter Generator (SFPG) to automatically generate salient prompters instead of explicitly providing foreground points or boxes as prompts in SAM. Comprehensive experimental results show that our USIS-SAM method can achieve superior performance on USIS10K datasets compared to the state-of-the-art methods. Datasets and codes are released on https://github.com/LiamLian0727/USIS10K.
Read more6/11/2024

0
Evaluation of Segment Anything Model 2: The Role of SAM2 in the Underwater Environment
Shijie Lian, Hua Li
With breakthroughs in large-scale modeling, the Segment Anything Model (SAM) and its extensions have been attempted for applications in various underwater visualization tasks in marine sciences, and have had a significant impact on the academic community. Recently, Meta has further developed the Segment Anything Model 2 (SAM2), which significantly improves running speed and segmentation accuracy compared to its predecessor. This report aims to explore the potential of SAM2 in marine science by evaluating it on the underwater instance segmentation benchmark datasets UIIS and USIS10K. The experiments show that the performance of SAM2 is extremely dependent on the type of user-provided prompts. When using the ground truth bounding box as prompt, SAM2 performed excellently in the underwater instance segmentation domain. However, when running in automatic mode, SAM2's ability with point prompts to sense and segment underwater instances is significantly degraded. It is hoped that this paper will inspire researchers to further explore the SAM model family in the underwater domain. The results and evaluation codes in this paper are available at https://github.com/LiamLian0727/UnderwaterSAM2Eval.
Read more8/7/2024
0
MAS-SAM: Segment Any Marine Animal with Aggregated Features
Tianyu Yan, Zifu Wan, Xinhao Deng, Pingping Zhang, Yang Liu, Huchuan Lu
Recently, Segment Anything Model (SAM) shows exceptional performance in generating high-quality object masks and achieving zero-shot image segmentation. However, as a versatile vision model, SAM is primarily trained with large-scale natural light images. In underwater scenes, it exhibits substantial performance degradation due to the light scattering and absorption. Meanwhile, the simplicity of the SAM's decoder might lead to the loss of fine-grained object details. To address the above issues, we propose a novel feature learning framework named MAS-SAM for marine animal segmentation, which involves integrating effective adapters into the SAM's encoder and constructing a pyramidal decoder. More specifically, we first build a new SAM's encoder with effective adapters for underwater scenes. Then, we introduce a Hypermap Extraction Module (HEM) to generate multi-scale features for a comprehensive guidance. Finally, we propose a Progressive Prediction Decoder (PPD) to aggregate the multi-scale features and predict the final segmentation results. When grafting with the Fusion Attention Module (FAM), our method enables to extract richer marine information from global contextual cues to fine-grained local details. Extensive experiments on four public MAS datasets demonstrate that our MAS-SAM can obtain better results than other typical segmentation methods. The source code is available at https://github.com/Drchip61/MAS-SAM.
Read more5/10/2024

0
Adapting Segment Anything Model to Multi-modal Salient Object Detection with Semantic Feature Fusion Guidance
Kunpeng Wang, Danying Lin, Chenglong Li, Zhengzheng Tu, Bin Luo
Although most existing multi-modal salient object detection (SOD) methods demonstrate effectiveness through training models from scratch, the limited multi-modal data hinders these methods from reaching optimality. In this paper, we propose a novel framework to explore and exploit the powerful feature representation and zero-shot generalization ability of the pre-trained Segment Anything Model (SAM) for multi-modal SOD. Despite serving as a recent vision fundamental model, driving the class-agnostic SAM to comprehend and detect salient objects accurately is non-trivial, especially in challenging scenes. To this end, we develop underline{SAM} with seunderline{m}antic funderline{e}ature fuunderline{s}ion guidancunderline{e} (Sammese), which incorporates multi-modal saliency-specific knowledge into SAM to adapt SAM to multi-modal SOD tasks. However, it is difficult for SAM trained on single-modal data to directly mine the complementary benefits of multi-modal inputs and comprehensively utilize them to achieve accurate saliency prediction. To address these issues, we first design a multi-modal complementary fusion module to extract robust multi-modal semantic features by integrating information from visible and thermal or depth image pairs. Then, we feed the extracted multi-modal semantic features into both the SAM image encoder and mask decoder for fine-tuning and prompting, respectively. Specifically, in the image encoder, a multi-modal adapter is proposed to adapt the single-modal SAM to multi-modal information. In the mask decoder, a semantic-geometric prompt generation strategy is proposed to produce corresponding embeddings with various saliency cues. Extensive experiments on both RGB-D and RGB-T SOD benchmarks show the effectiveness of the proposed framework. The code will be available at url{https://github.com/Angknpng/Sammese}.
Read more9/4/2024