DKL-KAN: Scalable Deep Kernel Learning using Kolmogorov-Arnold Networks

0

Sign in to get full access
Overview
- The paper introduces a scalable deep learning framework called DKL-KAN (Deep Kernel Learning using Kolmogorov-Arnold Networks).
- DKL-KAN combines deep kernel learning with Kolmogorov-Arnold networks, a type of universal function approximator.
- The goal is to develop a flexible and efficient approach for learning expressive kernel functions for a variety of machine learning tasks.
Plain English Explanation
The paper presents a new machine learning framework called DKL-KAN, which stands for "Deep Kernel Learning using Kolmogorov-Arnold Networks." This framework combines two powerful concepts: deep kernel learning and Kolmogorov-Arnold networks.
Deep kernel learning is a technique that allows machine learning models to learn the best kernel function for a given problem, rather than relying on a pre-defined kernel. This can lead to more expressive and powerful models.
Kolmogorov-Arnold networks are a type of universal function approximator, which means they can represent any continuous function with arbitrary precision. By incorporating Kolmogorov-Arnold networks into the deep kernel learning framework, the researchers aim to create a highly flexible and scalable approach for learning complex kernel functions.
The key idea behind DKL-KAN is to leverage the strengths of both deep kernel learning and Kolmogorov-Arnold networks to develop a machine learning system that can tackle a wide range of problems effectively. The researchers demonstrate the capabilities of DKL-KAN through various experiments and comparisons to other methods.
Technical Explanation
The paper introduces the DKL-KAN framework, which combines deep kernel learning with Kolmogorov-Arnold networks. Deep kernel learning is a technique that allows the kernel function in a kernel-based machine learning model to be learned from data, rather than using a pre-defined kernel.
Kolmogorov-Arnold networks are a type of universal function approximator that can represent any continuous function with arbitrary precision. By incorporating Kolmogorov-Arnold networks into the deep kernel learning framework, the researchers aim to create a highly flexible and scalable approach for learning expressive kernel functions.
The DKL-KAN architecture consists of two main components:
- A deep neural network that learns the feature representation of the input data.
- A Kolmogorov-Arnold network that learns the kernel function based on the learned features.
The authors evaluate DKL-KAN on a variety of machine learning tasks, including regression, classification, and structured prediction. They compare the performance of DKL-KAN to other kernel-based methods, as well as deep learning approaches. The results demonstrate the effectiveness and scalability of the DKL-KAN framework.
Critical Analysis
The paper presents a well-designed and comprehensive evaluation of the DKL-KAN framework, exploring its performance across multiple machine learning tasks and comparing it to various state-of-the-art methods. The authors acknowledge some potential limitations, such as the computational complexity of training the Kolmogorov-Arnold network component.
One area that could be further explored is the interpretability of the learned kernel functions. While the Kolmogorov-Arnold network provides a flexible and expressive representation, it may be challenging to understand the underlying structure and mechanisms of the learned kernel. Investigating ways to improve the interpretability of the DKL-KAN framework could be a valuable direction for future research.
Additionally, the paper does not delve into the potential ethical implications or societal impact of the DKL-KAN framework. As with any powerful machine learning tool, it is essential to consider how it might be used and the potential for unintended consequences. Addressing these concerns could strengthen the overall contribution of the research.
Conclusion
The DKL-KAN framework presented in this paper represents a significant advancement in the field of kernel-based machine learning. By combining deep kernel learning with the expressive power of Kolmogorov-Arnold networks, the researchers have developed a scalable and flexible approach that can learn highly complex kernel functions for a variety of tasks.
The empirical results demonstrate the effectiveness of DKL-KAN, suggesting that it could be a valuable tool for researchers and practitioners working on a wide range of machine learning problems. The potential implications of this work extend beyond the technical domain, as the ability to learn powerful kernel functions can have far-reaching applications in fields such as medicine, finance, and scientific discovery.
While the paper identifies some areas for further exploration, the DKL-KAN framework represents a significant step forward in the quest for more expressive and efficient machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DKL-KAN: Scalable Deep Kernel Learning using Kolmogorov-Arnold Networks
Shrenik Zinage, Sudeepta Mondal, Soumalya Sarkar
The need for scalable and expressive models in machine learning is paramount, particularly in applications requiring both structural depth and flexibility. Traditional deep learning methods, such as multilayer perceptrons (MLP), offer depth but lack ability to integrate structural characteristics of deep learning architectures with non-parametric flexibility of kernel methods. To address this, deep kernel learning (DKL) was introduced, where inputs to a base kernel are transformed using a deep learning architecture. These kernels can replace standard kernels, allowing both expressive power and scalability. The advent of Kolmogorov-Arnold Networks (KAN) has generated considerable attention and discussion among researchers in scientific domain. In this paper, we introduce a scalable deep kernel using KAN (DKL-KAN) as an effective alternative to DKL using MLP (DKL-MLP). Our approach involves simultaneously optimizing these kernel attributes using marginal likelihood within a Gaussian process framework. We analyze two variants of DKL-KAN for a fair comparison with DKL-MLP: one with same number of neurons and layers as DKL-MLP, and another with approximately same number of trainable parameters. To handle large datasets, we use kernel interpolation for scalable structured Gaussian processes (KISS-GP) for low-dimensional inputs and KISS-GP with product kernels for high-dimensional inputs. The efficacy of DKL-KAN is evaluated in terms of computational training time and test prediction accuracy across a wide range of applications. Additionally, the effectiveness of DKL-KAN is also examined in modeling discontinuities and accurately estimating prediction uncertainty. The results indicate that DKL-KAN outperforms DKL-MLP on datasets with a low number of observations. Conversely, DKL-MLP exhibits better scalability and higher test prediction accuracy on datasets with large number of observations.
Read more8/1/2024

0
Kolmogorov-Arnold Networks (KAN) for Time Series Classification and Robust Analysis
Chang Dong, Liangwei Zheng, Weitong Chen
Kolmogorov-Arnold Networks (KAN) has recently attracted significant attention as a promising alternative to traditional Multi-Layer Perceptrons (MLP). Despite their theoretical appeal, KAN require validation on large-scale benchmark datasets. Time series data, which has become increasingly prevalent in recent years, especially univariate time series are naturally suited for validating KAN. Therefore, we conducted a fair comparison among KAN, MLP, and mixed structures. The results indicate that KAN can achieve performance comparable to, or even slightly better than, MLP across 128 time series datasets. We also performed an ablation study on KAN, revealing that the output is primarily determined by the base component instead of b-spline function. Furthermore, we assessed the robustness of these models and found that KAN and the hybrid structure MLP_KAN exhibit significant robustness advantages, attributed to their lower Lipschitz constants. This suggests that KAN and KAN layers hold strong potential to be robust models or to improve the adversarial robustness of other models.
Read more9/12/2024

0
DP-KAN: Differentially Private Kolmogorov-Arnold Networks
Nikita P. Kalinin, Simone Bombari, Hossein Zakerinia, Christoph H. Lampert
We study the Kolmogorov-Arnold Network (KAN), recently proposed as an alternative to the classical Multilayer Perceptron (MLP), in the application for differentially private model training. Using the DP-SGD algorithm, we demonstrate that KAN can be made private in a straightforward manner and evaluated its performance across several datasets. Our results indicate that the accuracy of KAN is not only comparable with MLP but also experiences similar deterioration due to privacy constraints, making it suitable for differentially private model training.
Read more7/18/2024
19
KAN: Kolmogorov-Arnold Networks
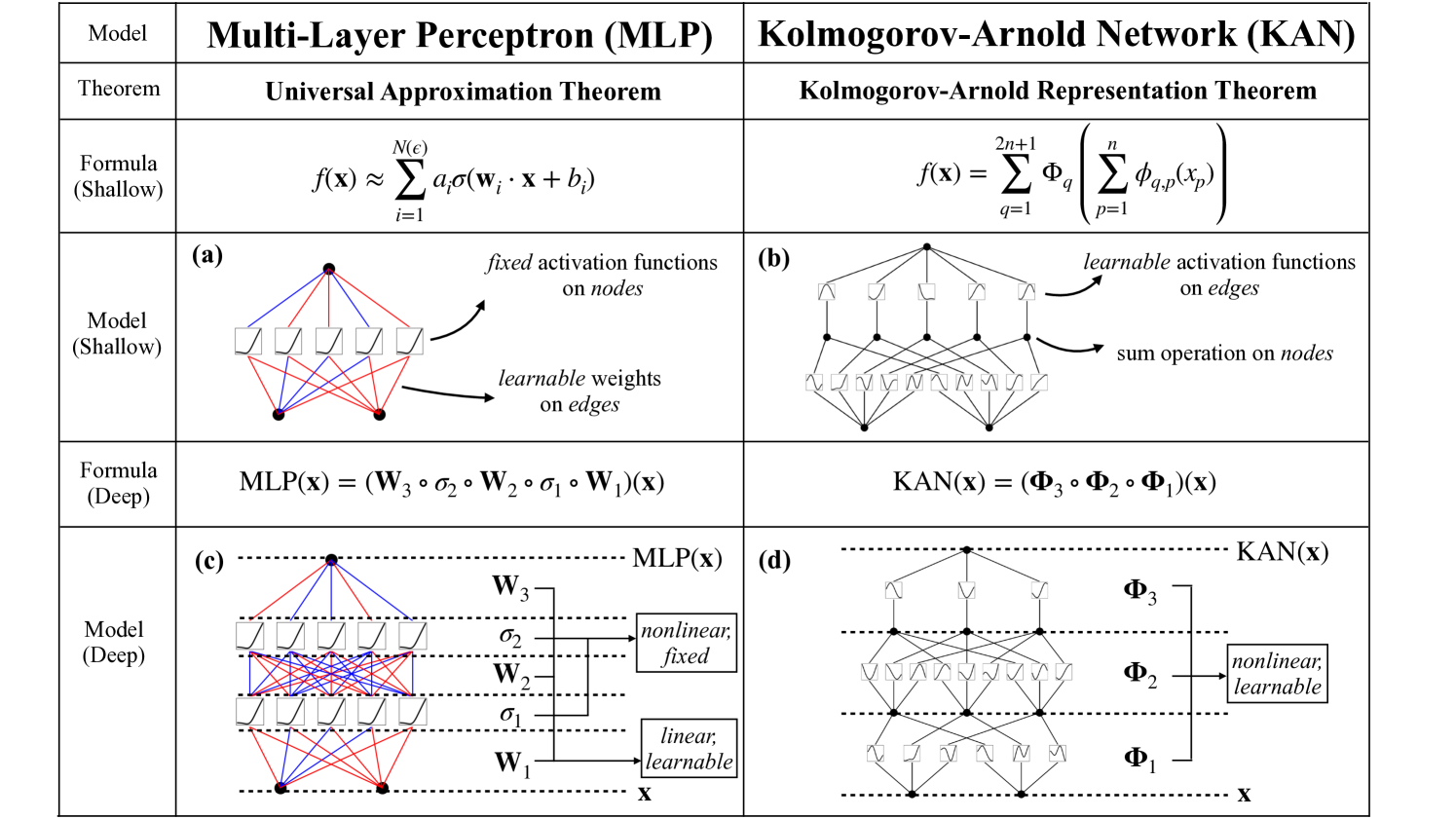
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljav{c}i'c, Thomas Y. Hou, Max Tegmark
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes (neurons), KANs have learnable activation functions on edges (weights). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Read more6/18/2024