Do Large Language Models Pay Similar Attention Like Human Programmers When Generating Code?
2306.01220
0
0
💬
Abstract
Large Language Models (LLMs) have recently been widely used for code generation. Due to the complexity and opacity of LLMs, little is known about how these models generate code. We made the first attempt to bridge this knowledge gap by investigating whether LLMs attend to the same parts of a task description as human programmers during code generation. An analysis of six LLMs, including GPT-4, on two popular code generation benchmarks revealed a consistent misalignment between LLMs' and programmers' attention. We manually analyzed 211 incorrect code snippets and found five attention patterns that can be used to explain many code generation errors. Finally, a user study showed that model attention computed by a perturbation-based method is often favored by human programmers. Our findings highlight the need for human-aligned LLMs for better interpretability and programmer trust.
Create account to get full access
Overview
- Recent research has explored how large language models (LLMs) generate code, as these models have become widely used for this task.
- However, little is known about how LLMs approach code generation compared to human programmers.
- This paper investigates whether LLMs, including GPT-4, attend to the same parts of a task description as human programmers during code generation.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can generate human-like text, including computer code. Researchers were curious to understand how these LLMs approach the task of generating code, and how their approach might differ from the way human programmers write code.
The researchers analyzed six different LLMs, including the powerful GPT-4 model, on two popular code generation benchmarks. They found that the LLMs' attention - the parts of the task description they focused on - was often misaligned with the attention of human programmers. In other words, the LLMs were not focusing on the same important details that human coders would when generating code.
The researchers manually examined over 200 instances where the LLMs generated incorrect code, and identified five common patterns in how the models' attention differed from human programmers. They also conducted a user study, which showed that the attention patterns computed by a perturbation-based method (a technique for analyzing model behavior) were often preferred by human programmers.
These findings highlight the need for LLMs that are more aligned with human approaches to programming and problem-solving. This could lead to better interpretability of the models' code generation process and greater trust from human programmers.
Technical Explanation
The researchers conducted an analysis of six large language models, including the GPT-4 model, on two popular code generation benchmarks. They aimed to investigate whether these LLMs attend to the same parts of a task description as human programmers during the code generation process.
The analysis revealed a consistent misalignment between the LLMs' attention and the attention of human programmers. The researchers manually examined 211 incorrect code snippets generated by the LLMs and identified five common attention patterns that can explain many of the code generation errors.
The researchers also conducted a user study, which showed that the model attention computed by a perturbation-based method [1] was often favored by human programmers. This suggests that this technique for analyzing model behavior may be a promising approach for improving the interpretability and human-alignment of LLMs in the context of code generation.
The findings of this research highlight the need for human-aligned LLMs that can better mimic the problem-solving strategies and attention patterns of human programmers. This could lead to improved interpretability and greater trust from programmers who work with these models.
Critical Analysis
The researchers acknowledge several limitations in their study. For example, the code generation benchmarks used may not fully capture the complexity of real-world programming tasks, and the manual analysis of 211 code snippets, while substantial, may not be representative of all the LLMs' behaviors.
Additionally, the researchers note that their findings are specific to the code generation task and may not generalize to other areas where LLMs are applied. Further research is needed to explore the alignment between LLMs and human problem-solving strategies across a broader range of tasks.
One area for potential future research is to investigate how different model architectures and training approaches might impact the alignment between LLMs and human programmers. Exploring ways to directly optimize LLMs for human-like attention and problem-solving could also be a fruitful direction.
Conclusion
This research provides valuable insights into the differences between how large language models and human programmers approach the task of code generation. The findings highlight the need for LLMs that are more closely aligned with human problem-solving strategies and attention patterns in order to improve the interpretability and trust of these models among programmers.
By bridging the gap between the way LLMs and humans generate code, future research in this area has the potential to lead to more intuitive and reliable AI-powered programming tools that can enhance the productivity and creativity of human developers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
0
0
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
6/4/2024
💬
Evaluation of the Programming Skills of Large Language Models
Luc Bryan Heitz, Joun Chamas, Christopher Scherb
0
0
The advent of Large Language Models (LLM) has revolutionized the efficiency and speed with which tasks are completed, marking a significant leap in productivity through technological innovation. As these chatbots tackle increasingly complex tasks, the challenge of assessing the quality of their outputs has become paramount. This paper critically examines the output quality of two leading LLMs, OpenAI's ChatGPT and Google's Gemini AI, by comparing the quality of programming code generated in both their free versions. Through the lens of a real-world example coupled with a systematic dataset, we investigate the code quality produced by these LLMs. Given their notable proficiency in code generation, this aspect of chatbot capability presents a particularly compelling area for analysis. Furthermore, the complexity of programming code often escalates to levels where its verification becomes a formidable task, underscoring the importance of our study. This research aims to shed light on the efficacy and reliability of LLMs in generating high-quality programming code, an endeavor that has significant implications for the field of software development and beyond.
5/24/2024
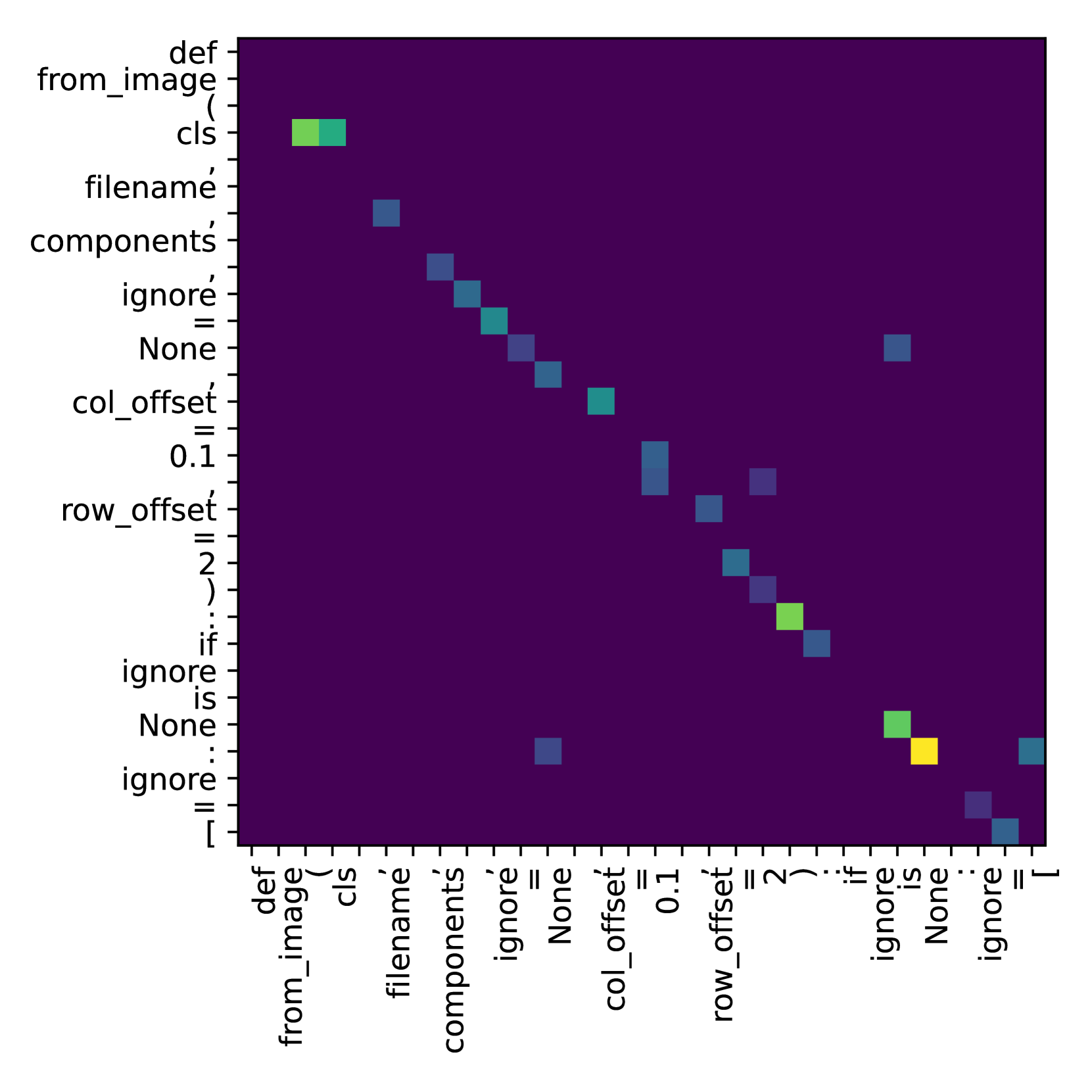
A Critical Study of What Code-LLMs (Do Not) Learn
Abhinav Anand, Shweta Verma, Krishna Narasimhan, Mira Mezini
0
0
Large Language Models trained on code corpora (code-LLMs) have demonstrated impressive performance in various coding assistance tasks. However, despite their increased size and training dataset, code-LLMs still have limitations such as suggesting codes with syntactic errors, variable misuse etc. Some studies argue that code-LLMs perform well on coding tasks because they use self-attention and hidden representations to encode relations among input tokens. However, previous works have not studied what code properties are not encoded by code-LLMs. In this paper, we conduct a fine-grained analysis of attention maps and hidden representations of code-LLMs. Our study indicates that code-LLMs only encode relations among specific subsets of input tokens. Specifically, by categorizing input tokens into syntactic tokens and identifiers, we found that models encode relations among syntactic tokens and among identifiers, but they fail to encode relations between syntactic tokens and identifiers. We also found that fine-tuned models encode these relations poorly compared to their pre-trained counterparts. Additionally, larger models with billions of parameters encode significantly less information about code than models with only a few hundred million parameters.
6/19/2024

Can Large Language Models abstract Medical Coded Language?
Simon A. Lee, Timothy Lindsey
0
0
Large Language Models (LLMs) have become a pivotal research area, potentially making beneficial contributions in fields like healthcare where they can streamline automated billing and decision support. However, the frequent use of specialized coded languages like ICD-10, which are regularly updated and deviate from natural language formats, presents potential challenges for LLMs in creating accurate and meaningful latent representations. This raises concerns among healthcare professionals about potential inaccuracies or ``hallucinations that could result in the direct impact of a patient. Therefore, this study evaluates whether large language models (LLMs) are aware of medical code ontologies and can accurately generate names from these codes. We assess the capabilities and limitations of both general and biomedical-specific generative models, such as GPT, LLaMA-2, and Meditron, focusing on their proficiency with domain-specific terminologies. While the results indicate that LLMs struggle with coded language, we offer insights on how to adapt these models to reason more effectively.
6/10/2024