A Critical Study of What Code-LLMs (Do Not) Learn
2406.11930
0
0
Abstract
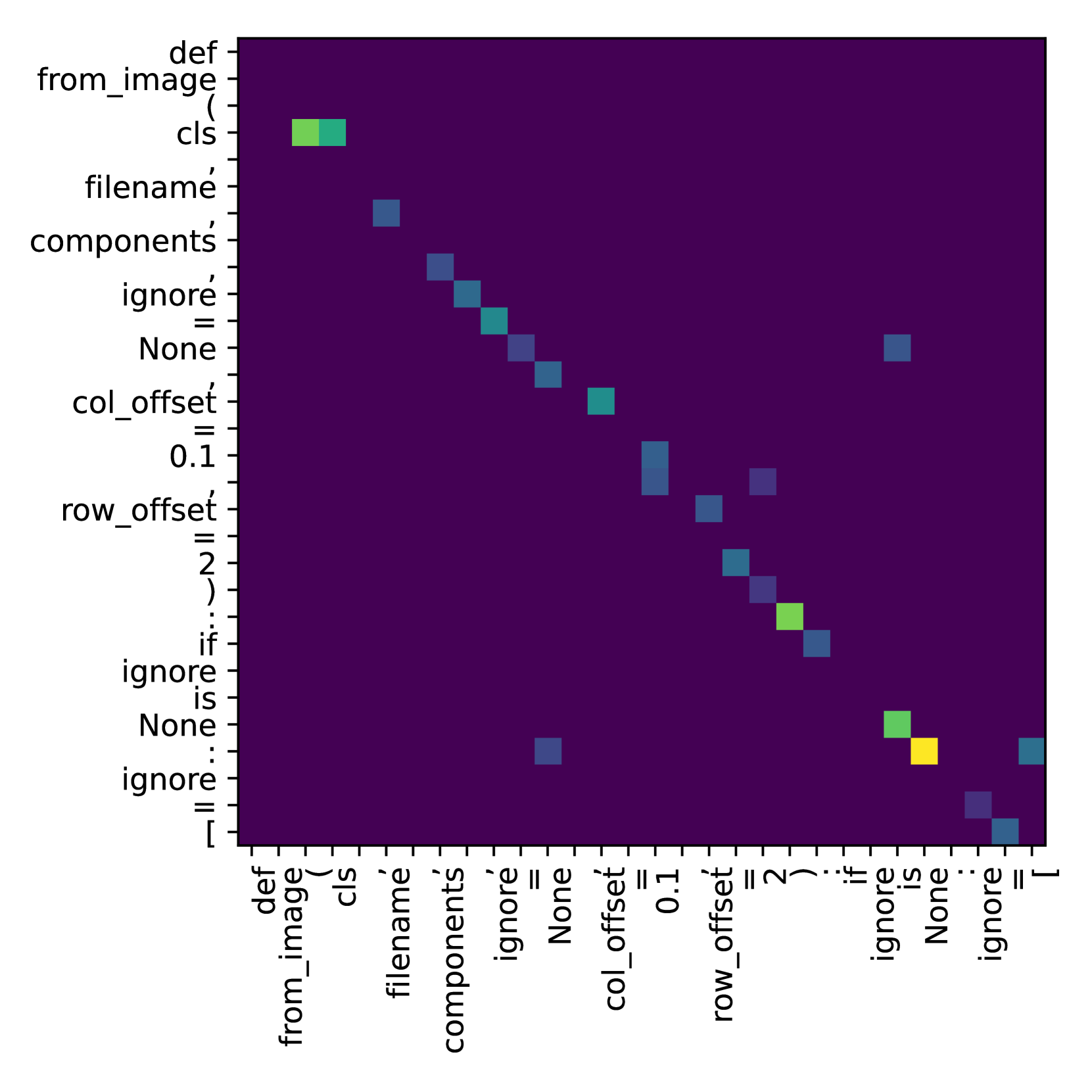
Large Language Models trained on code corpora (code-LLMs) have demonstrated impressive performance in various coding assistance tasks. However, despite their increased size and training dataset, code-LLMs still have limitations such as suggesting codes with syntactic errors, variable misuse etc. Some studies argue that code-LLMs perform well on coding tasks because they use self-attention and hidden representations to encode relations among input tokens. However, previous works have not studied what code properties are not encoded by code-LLMs. In this paper, we conduct a fine-grained analysis of attention maps and hidden representations of code-LLMs. Our study indicates that code-LLMs only encode relations among specific subsets of input tokens. Specifically, by categorizing input tokens into syntactic tokens and identifiers, we found that models encode relations among syntactic tokens and among identifiers, but they fail to encode relations between syntactic tokens and identifiers. We also found that fine-tuned models encode these relations poorly compared to their pre-trained counterparts. Additionally, larger models with billions of parameters encode significantly less information about code than models with only a few hundred million parameters.
Create account to get full access
Overview
• This research paper critically examines what code-based large language models (LLMs) actually learn and the limitations of their understanding.
• The paper investigates whether code-LLMs can grasp the higher-level semantics and abstractions of programming, or if they merely memorize and regurgitate surface-level patterns.
Plain English Explanation
• Large language models (LLMs) have become increasingly capable at generating and understanding natural language. Recently, researchers have applied similar techniques to train LLMs on programming languages, creating "code-LLMs" that can generate and reason about code.
• However, this paper suggests that code-LLMs may not actually learn the deeper, more abstract concepts of programming. Instead, they may simply memorize and reproduce surface-level patterns without true comprehension.
• The paper conducts experiments to test the limits of code-LLM understanding, such as assessing their ability to generalize to new programming tasks or understand high-level programming concepts. The results indicate that while code-LLMs can perform many code-related tasks, they may lack a deeper, contextual understanding of programming.
• This research is important because it challenges the assumption that code-LLMs are truly "learning" programming in the way humans do. If they are mainly memorizing patterns rather than grasping core concepts, it could limit their usefulness for tasks that require genuine programming expertise, such as code summarization or contextual learning.
Technical Explanation
• The paper conducts a series of experiments to probe the inner workings of code-LLMs and assess the extent of their programming knowledge.
• One experiment tests the models' ability to generalize to new programming tasks, rather than simply reciting memorized solutions. The results suggest that while code-LLMs can perform basic coding tasks, they struggle to apply their knowledge to novel problems that require deeper conceptual understanding.
• Another experiment examines whether code-LLMs can grasp high-level programming constructs, such as object-oriented design patterns or algorithmic complexity. The findings indicate that the models tend to focus on surface-level syntax and structure, without truly comprehending the underlying semantics.
• The paper also investigates the models' attention mechanisms, which reveal that they may not be paying attention to the same critical program elements that human programmers would. This further suggests a lack of deeper programming comprehension.
Critical Analysis
• The paper raises valid concerns about the limitations of current code-LLMs and the risks of over-relying on them for tasks that require genuine programming expertise.
• While the experiments provide valuable insights, the authors acknowledge that their findings may be specific to the particular models and datasets they tested. Evaluating a broader range of code-LLMs and tasks would strengthen the generalizability of the conclusions.
• Additionally, the paper does not explore potential ways to improve the conceptual understanding of code-LLMs, such as through targeted fine-tuning or the incorporation of more structured programming knowledge. Further research in this direction could help address the limitations identified in the study.
• Overall, the paper presents a thoughtful and nuanced critique of code-LLMs, encouraging readers to think critically about the capabilities and limitations of these models, rather than assuming they have truly mastered programming.
Conclusion
• This research paper provides a critical examination of what code-based large language models (code-LLMs) actually learn, challenging the assumption that they can genuinely understand programming concepts.
• The experiments suggest that while code-LLMs can perform many coding-related tasks, they may primarily rely on pattern matching and surface-level understanding, rather than deeper, contextual learning of programming.
• These findings have important implications for the use of code-LLMs in applications that require robust programming expertise, such as code generation, summarization, and contextual understanding. The paper emphasizes the need for continued research and development to address the limitations of current code-LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Do Large Language Models Pay Similar Attention Like Human Programmers When Generating Code?
Bonan Kou, Shengmai Chen, Zhijie Wang, Lei Ma, Tianyi Zhang
0
0
Large Language Models (LLMs) have recently been widely used for code generation. Due to the complexity and opacity of LLMs, little is known about how these models generate code. We made the first attempt to bridge this knowledge gap by investigating whether LLMs attend to the same parts of a task description as human programmers during code generation. An analysis of six LLMs, including GPT-4, on two popular code generation benchmarks revealed a consistent misalignment between LLMs' and programmers' attention. We manually analyzed 211 incorrect code snippets and found five attention patterns that can be used to explain many code generation errors. Finally, a user study showed that model attention computed by a perturbation-based method is often favored by human programmers. Our findings highlight the need for human-aligned LLMs for better interpretability and programmer trust.
5/24/2024

Can Large Language Models abstract Medical Coded Language?
Simon A. Lee, Timothy Lindsey
0
0
Large Language Models (LLMs) have become a pivotal research area, potentially making beneficial contributions in fields like healthcare where they can streamline automated billing and decision support. However, the frequent use of specialized coded languages like ICD-10, which are regularly updated and deviate from natural language formats, presents potential challenges for LLMs in creating accurate and meaningful latent representations. This raises concerns among healthcare professionals about potential inaccuracies or ``hallucinations that could result in the direct impact of a patient. Therefore, this study evaluates whether large language models (LLMs) are aware of medical code ontologies and can accurately generate names from these codes. We assess the capabilities and limitations of both general and biomedical-specific generative models, such as GPT, LLaMA-2, and Meditron, focusing on their proficiency with domain-specific terminologies. While the results indicate that LLMs struggle with coded language, we offer insights on how to adapt these models to reason more effectively.
6/10/2024

A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
0
0
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
6/4/2024
Analyzing the Performance of Large Language Models on Code Summarization
Rajarshi Haldar, Julia Hockenmaier
0
0
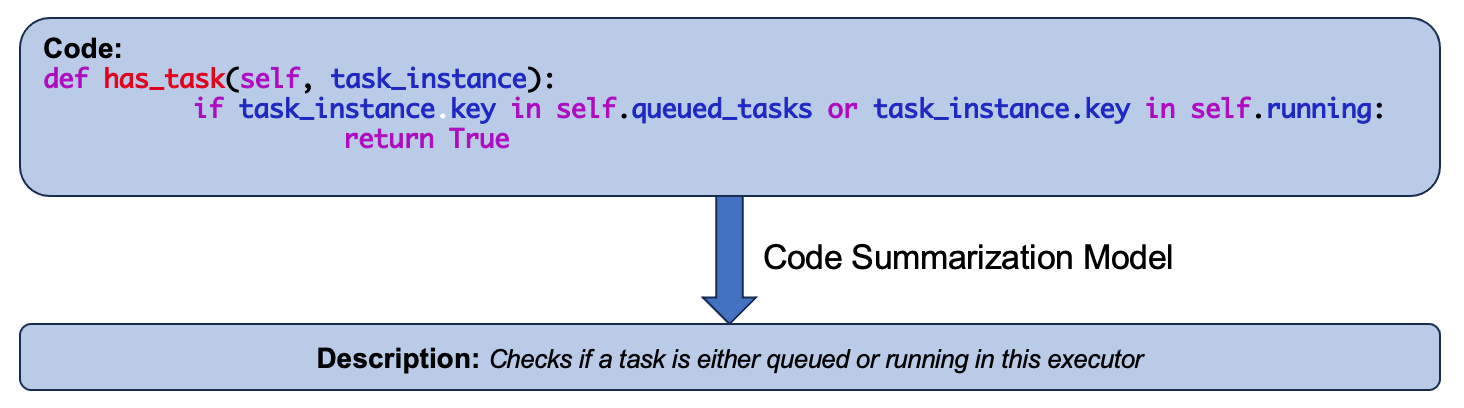
Large language models (LLMs) such as Llama 2 perform very well on tasks that involve both natural language and source code, particularly code summarization and code generation. We show that for the task of code summarization, the performance of these models on individual examples often depends on the amount of (subword) token overlap between the code and the corresponding reference natural language descriptions in the dataset. This token overlap arises because the reference descriptions in standard datasets (corresponding to docstrings in large code bases) are often highly similar to the names of the functions they describe. We also show that this token overlap occurs largely in the function names of the code and compare the relative performance of these models after removing function names versus removing code structure. We also show that using multiple evaluation metrics like BLEU and BERTScore gives us very little additional insight since these metrics are highly correlated with each other.
4/15/2024