$Delta$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
2406.01125
0
0

Abstract
Diffusion models are widely recognized for generating high-quality and diverse images, but their poor real-time performance has led to numerous acceleration works, primarily focusing on UNet-based structures. With the more successful results achieved by diffusion transformers (DiT), there is still a lack of exploration regarding the impact of DiT structure on generation, as well as the absence of an acceleration framework tailored to the DiT architecture. To tackle these challenges, we conduct an investigation into the correlation between DiT blocks and image generation. Our findings reveal that the front blocks of DiT are associated with the outline of the generated images, while the rear blocks are linked to the details. Based on this insight, we propose an overall training-free inference acceleration framework $Delta$-DiT: using a designed cache mechanism to accelerate the rear DiT blocks in the early sampling stages and the front DiT blocks in the later stages. Specifically, a DiT-specific cache mechanism called $Delta$-Cache is proposed, which considers the inputs of the previous sampling image and reduces the bias in the inference. Extensive experiments on PIXART-$alpha$ and DiT-XL demonstrate that the $Delta$-DiT can achieve a $1.6times$ speedup on the 20-step generation and even improves performance in most cases. In the scenario of 4-step consistent model generation and the more challenging $1.12times$ acceleration, our method significantly outperforms existing methods. Our code will be publicly available.
Create account to get full access
Overview
- This paper introduces Δ-DiT, a training-free acceleration method for diffusion transformer models.
- Δ-DiT aims to improve the efficiency of diffusion transformers without retraining the model.
- The method leverages the inherent structure of diffusion transformers to enable faster inference while maintaining high-quality results.
Plain English Explanation
Diffusion transformer models are a powerful type of machine learning model that can generate high-quality images, text, and other content. However, these models can be computationally expensive and slow to run, especially during the inference or "generation" stage.
The researchers who wrote this paper have developed a new technique called Δ-DiT that can speed up the inference process for diffusion transformers without requiring the model to be retrained. Δ-DiT works by taking advantage of the internal structure of diffusion transformer models to make certain calculations more efficient.
The key idea behind Δ-DiT is to leverage the hierarchical structure of diffusion transformers to avoid redundant computations during the diffusion process. By identifying and exploiting certain patterns in how the model processes information, Δ-DiT can generate high-quality outputs much faster than the original diffusion transformer.
This acceleration method is "training-free", meaning it can be applied to existing diffusion transformer models without the need to retrain them from scratch. This makes Δ-DiT a practical and versatile tool for improving the efficiency of these powerful generative models.
Technical Explanation
The core innovation of Δ-DiT is the use of a "delta" prediction scheme to accelerate the diffusion process. Diffusion transformer models work by gradually adding noise to an input image or text, then learning to reverse that process to generate new outputs.
Δ-DiT observes that the changes between consecutive diffusion steps are often small and predictable. By modeling these "delta" changes instead of the full output at each step, the researchers were able to reduce the computational cost of the diffusion process. This delta prediction scheme is integrated with the hierarchical structure of diffusion transformers to further optimize the inference speed.
The authors also introduce several other techniques, such as adaptive step sizes and learned step size prediction, to make the Δ-DiT acceleration method more robust and effective. Through extensive experiments, they demonstrate that Δ-DiT can achieve significant speedups (up to 2.5x) on a variety of diffusion transformer models and datasets, while maintaining high-quality generation results.
Critical Analysis
The Δ-DiT paper presents a compelling and well-designed acceleration method for diffusion transformer models. The core idea of exploiting the inherent structure of these models to enable more efficient inference is both clever and well-executed.
One potential limitation of Δ-DiT is that it may not be as effective on certain types of diffusion transformer architectures or datasets, particularly those where the changes between diffusion steps are less predictable. The authors acknowledge this and suggest that further research is needed to understand the broader applicability of their technique.
Additionally, while Δ-DiT achieves impressive speedups, there may be other avenues for improving the efficiency of diffusion transformers, such as post-training quantization or upsampling techniques. It would be interesting to see how Δ-DiT could be combined with or compared to these other acceleration methods.
Overall, the Δ-DiT paper makes a valuable contribution to the field of diffusion transformer optimization, and the authors have done an excellent job of designing and evaluating their technique. Researchers and practitioners working with these powerful generative models would likely find Δ-DiT to be a useful tool in their arsenal.
Conclusion
The Δ-DiT paper introduces a novel, training-free acceleration method for diffusion transformer models. By leveraging the inherent structure of these models, the researchers were able to develop a delta prediction scheme that can significantly speed up the inference process without sacrificing generation quality.
This work represents an important step forward in improving the efficiency and practical deployment of diffusion transformers, which have shown great potential in a wide range of generative tasks. The Δ-DiT technique could help make these models more accessible and usable in real-world applications, opening up new possibilities for high-quality, AI-generated content.
As the field of diffusion-based generative modeling continues to advance, techniques like Δ-DiT will likely play an increasingly important role in pushing the boundaries of what is possible with these powerful machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
TerDiT: Ternary Diffusion Models with Transformers
Xudong Lu, Aojun Zhou, Ziyi Lin, Qi Liu, Yuhui Xu, Renrui Zhang, Yafei Wen, Shuai Ren, Peng Gao, Junchi Yan, Hongsheng Li
0
0
Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
5/24/2024

DiTFastAttn: Attention Compression for Diffusion Transformer Models
Zhihang Yuan, Pu Lu, Hanling Zhang, Xuefei Ning, Linfeng Zhang, Tianchen Zhao, Shengen Yan, Guohao Dai, Yu Wang
0
0
Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to self-attention's quadratic complexity. We propose DiTFastAttn, a novel post-training compression method to alleviate DiT's computational bottleneck. We identify three key redundancies in the attention computation during DiT inference: 1. spatial redundancy, where many attention heads focus on local information; 2. temporal redundancy, with high similarity between neighboring steps' attention outputs; 3. conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. To tackle these redundancies, we propose three techniques: 1. Window Attention with Residual Caching to reduce spatial redundancy; 2. Temporal Similarity Reduction to exploit the similarity between steps; 3. Conditional Redundancy Elimination to skip redundant computations during conditional generation. To demonstrate the effectiveness of DiTFastAttn, we apply it to DiT, PixArt-Sigma for image generation tasks, and OpenSora for video generation tasks. Evaluation results show that for image generation, our method reduces up to 88% of the FLOPs and achieves up to 1.6x speedup at high resolution generation.
6/14/2024
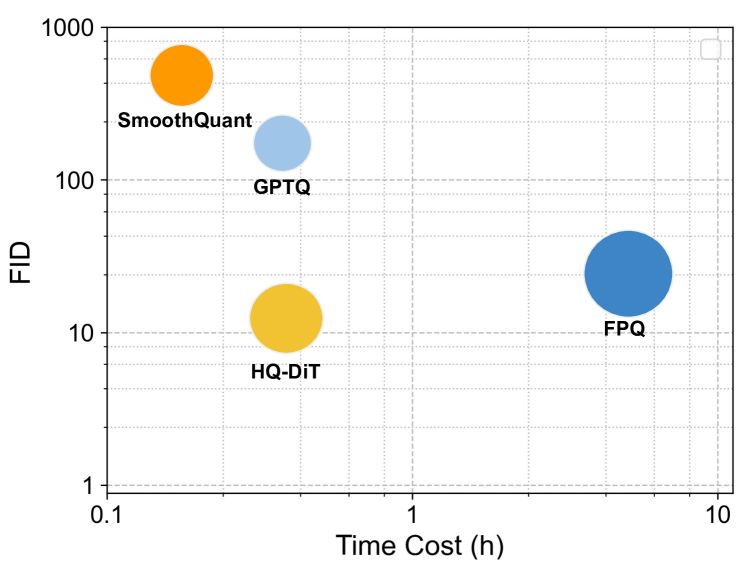
HQ-DiT: Efficient Diffusion Transformer with FP4 Hybrid Quantization
Wenxuan Liu, Sai Qian Zhang
0
0
Diffusion Transformers (DiTs) have recently gained substantial attention in both industrial and academic fields for their superior visual generation capabilities, outperforming traditional diffusion models that use U-Net. However,the enhanced performance of DiTs also comes with high parameter counts and implementation costs, seriously restricting their use on resource-limited devices such as mobile phones. To address these challenges, we introduce the Hybrid Floating-point Quantization for DiT(HQ-DiT), an efficient post-training quantization method that utilizes 4-bit floating-point (FP) precision on both weights and activations for DiT inference. Compared to fixed-point quantization (e.g., INT8), FP quantization, complemented by our proposed clipping range selection mechanism, naturally aligns with the data distribution within DiT, resulting in a minimal quantization error. Furthermore, HQ-DiT also implements a universal identity mathematical transform to mitigate the serious quantization error caused by the outliers. The experimental results demonstrate that DiT can achieve extremely low-precision quantization (i.e., 4 bits) with negligible impact on performance. Our approach marks the first instance where both weights and activations in DiTs are quantized to just 4 bits, with only a 0.12 increase in sFID on ImageNet.
6/3/2024
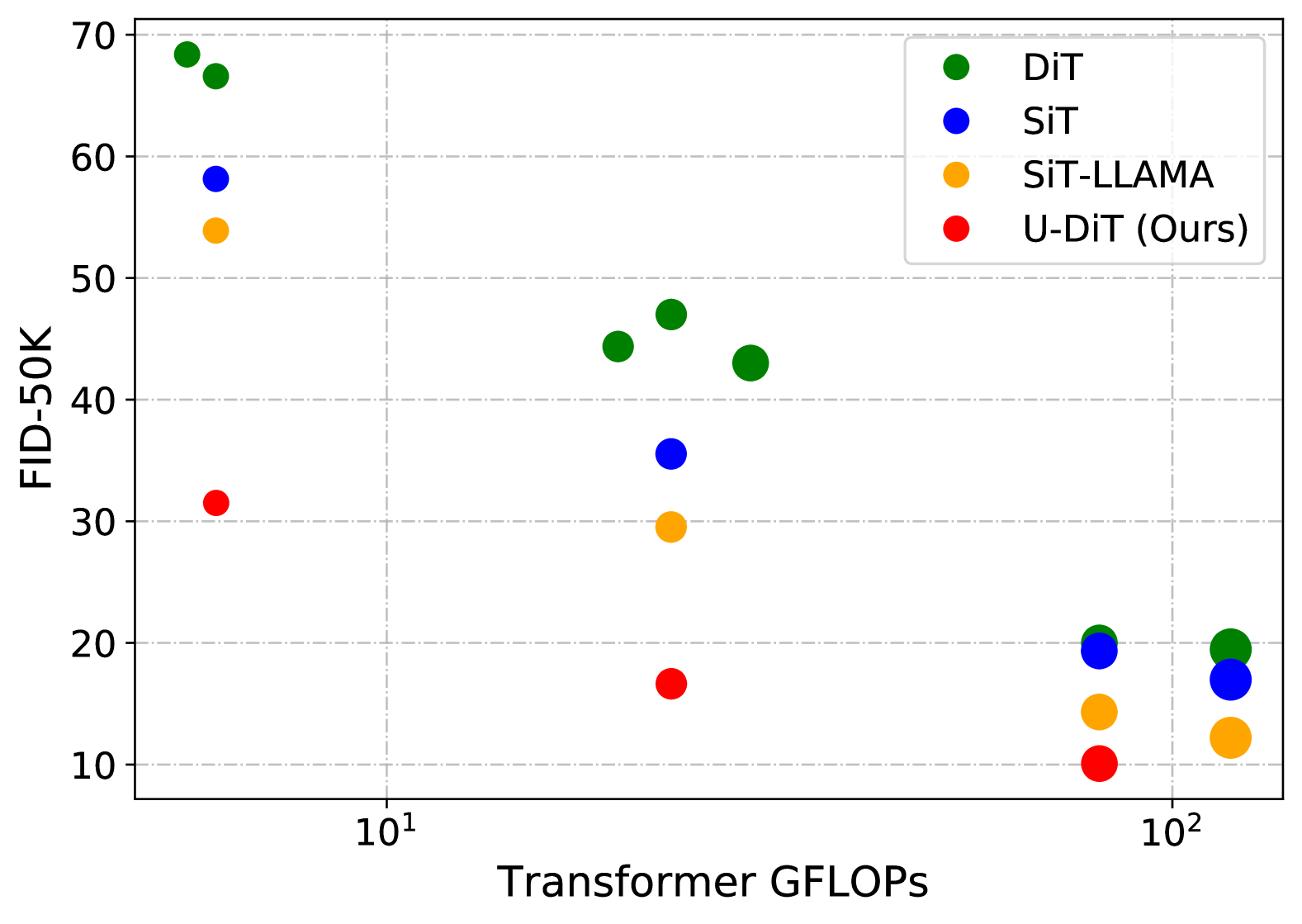
U-DiTs: Downsample Tokens in U-Shaped Diffusion Transformers
Yuchuan Tian, Zhijun Tu, Hanting Chen, Jie Hu, Chao Xu, Yunhe Wang
0
0
Diffusion Transformers (DiTs) introduce the transformer architecture to diffusion tasks for latent-space image generation. With an isotropic architecture that chains a series of transformer blocks, DiTs demonstrate competitive performance and good scalability; but meanwhile, the abandonment of U-Net by DiTs and their following improvements is worth rethinking. To this end, we conduct a simple toy experiment by comparing a U-Net architectured DiT with an isotropic one. It turns out that the U-Net architecture only gain a slight advantage amid the U-Net inductive bias, indicating potential redundancies within the U-Net-style DiT. Inspired by the discovery that U-Net backbone features are low-frequency-dominated, we perform token downsampling on the query-key-value tuple for self-attention that bring further improvements despite a considerable amount of reduction in computation. Based on self-attention with downsampled tokens, we propose a series of U-shaped DiTs (U-DiTs) in the paper and conduct extensive experiments to demonstrate the extraordinary performance of U-DiT models. The proposed U-DiT could outperform DiT-XL/2 with only 1/6 of its computation cost. Codes are available at https://github.com/YuchuanTian/U-DiT.
6/4/2024