Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
2405.04312
0
0
🖼️
Abstract
Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096
Create account to get full access
Overview
- Diffusion models have shown impressive performance in image generation, but face challenges with generating ultra-high-resolution images due to increased memory requirements.
- The authors propose a unidirectional block attention mechanism that can adaptively adjust memory overhead during inference, allowing for the generation of ultra-high-resolution images.
- Building on this module, the authors adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upscaling images of various shapes and resolutions.
- Experiments show the model achieves state-of-the-art performance in generating ultra-high-resolution images, while using significantly less memory than common UNet structures.
Plain English Explanation
Diffusion models are a type of machine learning system that can generate impressive images. However, when trying to create extremely high-resolution images (like 4096x4096 pixels), these models can quickly run out of computer memory, limiting the resolution of the generated images to around 1024x1024.
To solve this problem, the researchers developed a new module that can dynamically adjust the memory usage during the image generation process. This allows the model to efficiently generate ultra-high-resolution images without running out of memory.
Building on this memory-efficient module, the researchers created an "infinite super-resolution" model. This model can take in images of various sizes and resolutions, and then upscale them to much higher resolutions, saving memory and computation compared to other approaches.
Through extensive testing, the researchers showed that their model can generate incredibly detailed, high-resolution images that outperform other state-of-the-art methods. Compared to common models, their approach can save over 5 times the memory when generating 4096x4096 images, making it much more efficient.
Technical Explanation
The key innovation in this work is a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process. This allows the model to handle global dependencies while generating ultra-high-resolution images.
The researchers build upon the DiT (Diffusion Transformer) structure, adopting it for the upsampling task and developing an "infinite super-resolution" model. This model can take in images of various shapes and resolutions and upscale them to much higher resolutions, leveraging the efficiency of the Diffusion Transformer architecture.
Comprehensive experiments demonstrate that the proposed model achieves state-of-the-art performance in generating ultra-high-resolution images, as evaluated by both machine and human metrics. Compared to commonly used UNet structures, the authors' model can save over 5x memory when generating 4096x4096 images.
Critical Analysis
The paper provides a thorough technical explanation of the proposed model and its key innovations. However, it would be helpful to have more discussion around the potential limitations or caveats of the approach.
For example, the paper does not address how the model might perform on diverse, real-world image datasets beyond the standard benchmarks. There could be concerns around the model's robustness or generalization to more challenging or noisy input images.
Additionally, the paper does not delve into the computational and training costs of the proposed model. While the inference-time memory efficiency is impressive, the training process may require significant resources that could limit the model's practical deployment.
Overall, the research represents an important advance in diffusion-based image generation, particularly for ultra-high-resolution outputs. However, further analysis and discussion of the model's limitations and potential issues would strengthen the critical perspective.
Conclusion
This paper presents a novel approach to generating ultra-high-resolution images using diffusion models. By introducing a unidirectional block attention mechanism that can adaptively manage memory usage, the researchers have developed an "infinite super-resolution" model capable of upscaling images of various shapes and resolutions.
The comprehensive experiments demonstrate that this model outperforms state-of-the-art methods in terms of both machine and human evaluation metrics. Crucially, the model can save over 5 times the memory compared to common UNet structures when generating 4096x4096 images, a significant efficiency improvement.
This research represents an important step forward in the field of diffusion-based image generation, unlocking the potential for highly detailed, high-resolution creative outputs. The memory-efficient approach could have widespread applications in areas like art, design, and visual effects, paving the way for more efficient and powerful image generation tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
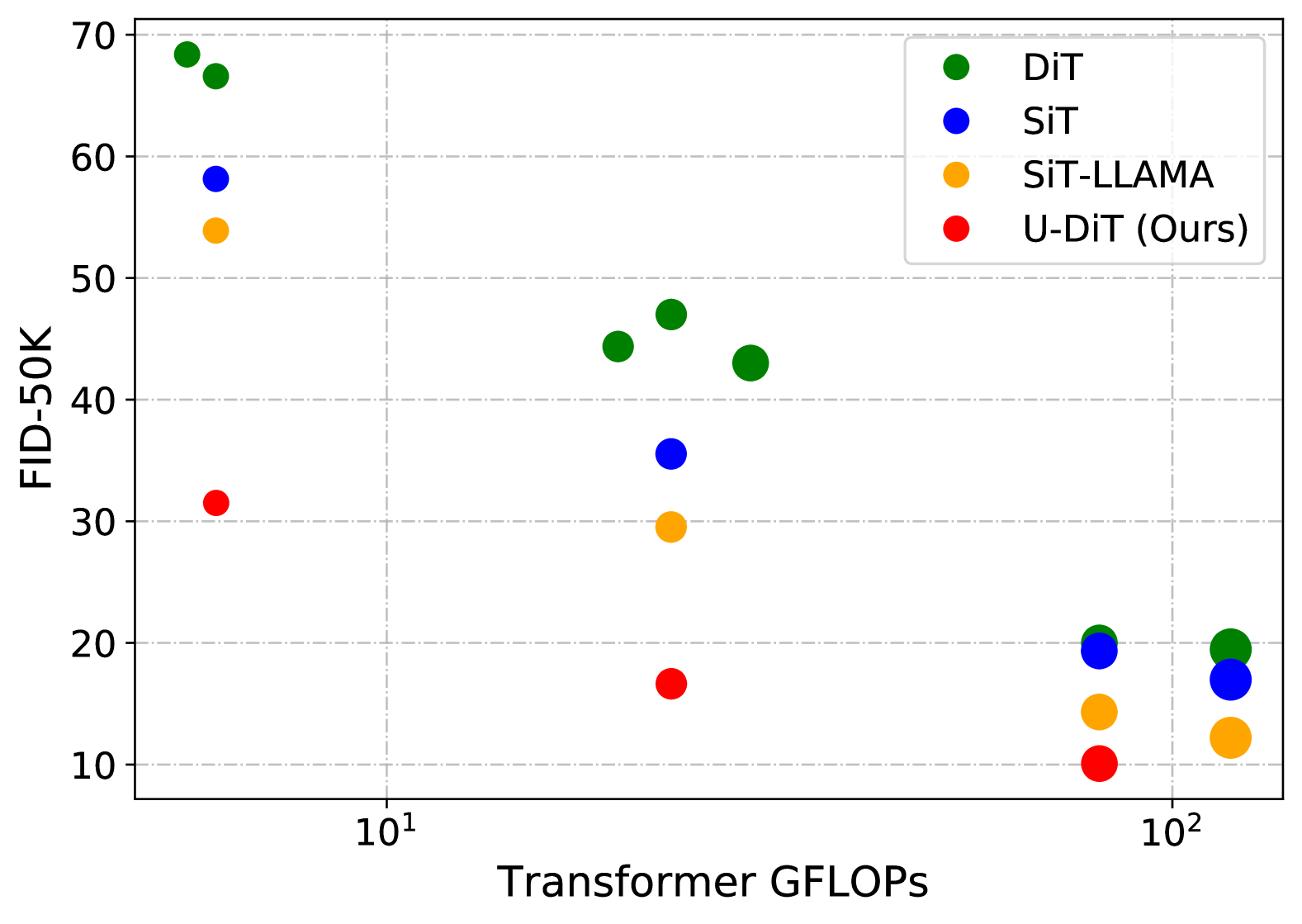
U-DiTs: Downsample Tokens in U-Shaped Diffusion Transformers
Yuchuan Tian, Zhijun Tu, Hanting Chen, Jie Hu, Chao Xu, Yunhe Wang
0
0
Diffusion Transformers (DiTs) introduce the transformer architecture to diffusion tasks for latent-space image generation. With an isotropic architecture that chains a series of transformer blocks, DiTs demonstrate competitive performance and good scalability; but meanwhile, the abandonment of U-Net by DiTs and their following improvements is worth rethinking. To this end, we conduct a simple toy experiment by comparing a U-Net architectured DiT with an isotropic one. It turns out that the U-Net architecture only gain a slight advantage amid the U-Net inductive bias, indicating potential redundancies within the U-Net-style DiT. Inspired by the discovery that U-Net backbone features are low-frequency-dominated, we perform token downsampling on the query-key-value tuple for self-attention that bring further improvements despite a considerable amount of reduction in computation. Based on self-attention with downsampled tokens, we propose a series of U-shaped DiTs (U-DiTs) in the paper and conduct extensive experiments to demonstrate the extraordinary performance of U-DiT models. The proposed U-DiT could outperform DiT-XL/2 with only 1/6 of its computation cost. Codes are available at https://github.com/YuchuanTian/U-DiT.
6/4/2024
↗️
HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, Jiajun Liang
0
0
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net (RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention (MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096x4096 at 1.5-6x the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
4/30/2024
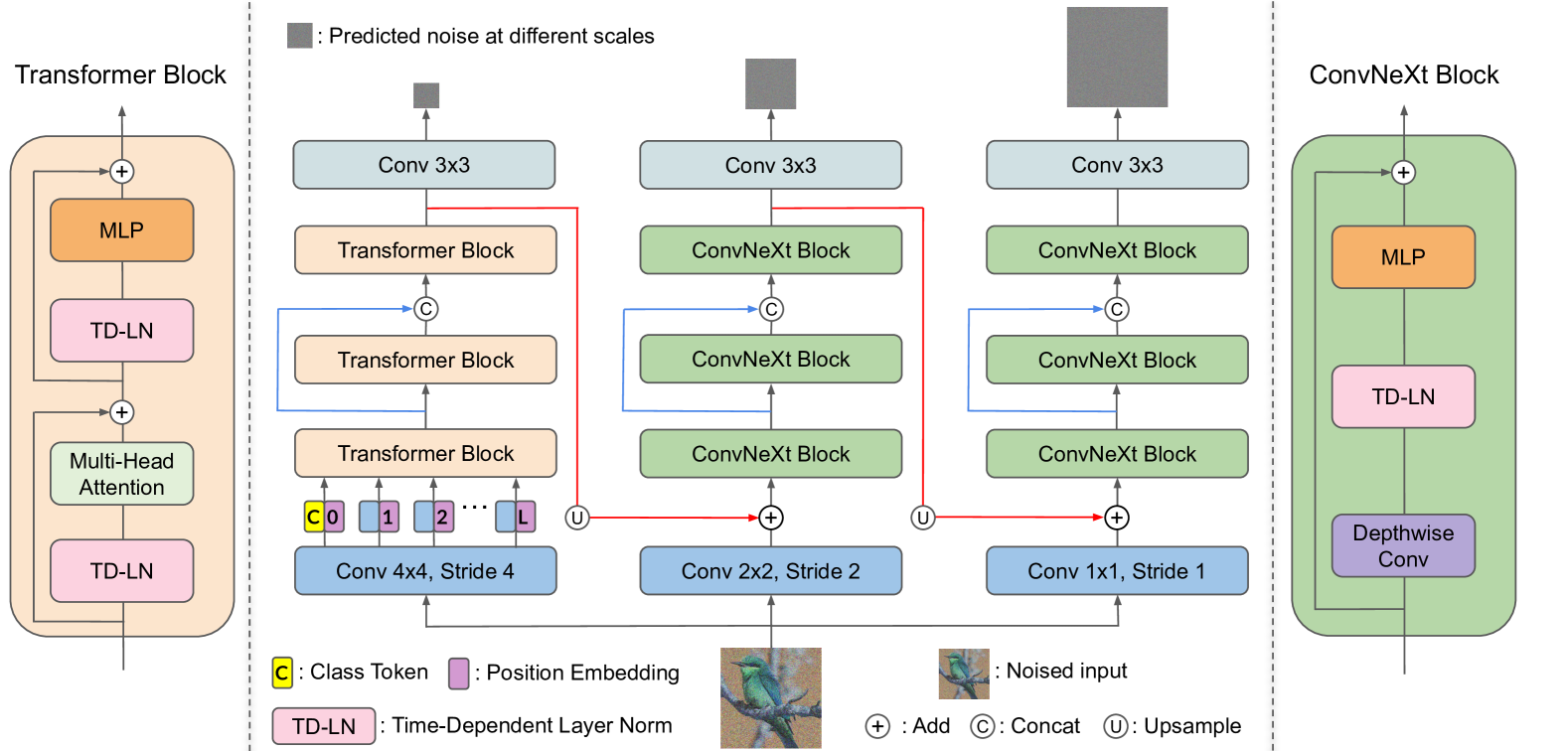
Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models
Qihao Liu, Zhanpeng Zeng, Ju He, Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
0
0
This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation. While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via patchification), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length. While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution. Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance. Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512. Project page: https://qihao067.github.io/projects/DiMR
6/14/2024
🌐
TerDiT: Ternary Diffusion Models with Transformers
Xudong Lu, Aojun Zhou, Ziyi Lin, Qi Liu, Yuhui Xu, Renrui Zhang, Yafei Wen, Shuai Ren, Peng Gao, Junchi Yan, Hongsheng Li
0
0
Recent developments in large-scale pre-trained text-to-image diffusion models have significantly improved the generation of high-fidelity images, particularly with the emergence of diffusion models based on transformer architecture (DiTs). Among these diffusion models, diffusion transformers have demonstrated superior image generation capabilities, boosting lower FID scores and higher scalability. However, deploying large-scale DiT models can be expensive due to their extensive parameter numbers. Although existing research has explored efficient deployment techniques for diffusion models such as model quantization, there is still little work concerning DiT-based models. To tackle this research gap, in this paper, we propose TerDiT, a quantization-aware training (QAT) and efficient deployment scheme for ternary diffusion models with transformers. We focus on the ternarization of DiT networks and scale model sizes from 600M to 4.2B. Our work contributes to the exploration of efficient deployment strategies for large-scale DiT models, demonstrating the feasibility of training extremely low-bit diffusion transformer models from scratch while maintaining competitive image generation capacities compared to full-precision models. Code will be available at https://github.com/Lucky-Lance/TerDiT.
5/24/2024