DPO Meets PPO: Reinforced Token Optimization for RLHF
2404.18922
0
0

Abstract
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel reinforcement learning approach called "Reinforced Token Optimization for RLHF" (RTO-RLHF), which combines Deterministic Policy Optimization (DPO) and Proximal Policy Optimization (PPO) to optimize language models for alignment with human preferences.
- The authors demonstrate that RTO-RLHF outperforms existing RLHF methods on various benchmarks, including token-level direct preference optimization and filtered direct preference optimization.
- The key innovations of RTO-RLHF include a novel token-level optimization objective and the integration of DPO and PPO to leverage the strengths of both approaches.
Plain English Explanation
The paper describes a new way to train large language models (LLMs) to be more aligned with human preferences. This is an important problem because as LLMs become more powerful, it's crucial that they behave in ways that are beneficial to humans.
The authors' approach, called Reinforced Token Optimization for RLHF (RTO-RLHF), combines two existing techniques: Deterministic Policy Optimization (DPO) and Proximal Policy Optimization (PPO). DPO is good at optimizing the model at the individual token level, while PPO is better at maintaining the overall coherence and consistency of the model's outputs.
By combining these two methods, the authors create a more effective system for training LLMs to produce text that is aligned with human preferences. They show that RTO-RLHF outperforms other state-of-the-art RLHF methods on a variety of benchmarks.
The key innovation in RTO-RLHF is the way it optimizes the model at the individual token level, rather than just looking at the overall quality of the generated text. This allows the model to learn more fine-grained preferences and produce outputs that are more closely aligned with what humans want.
Technical Explanation
The RTO-RLHF approach combines DPO and PPO to optimize language models for alignment with human preferences. DPO is used to directly optimize the probability of generating each token in a way that aligns with human preferences, while PPO is used to maintain the overall coherence and consistency of the model's outputs.
The authors formulate a novel token-level optimization objective that combines the advantages of DPO and PPO. This objective encourages the model to generate tokens that are highly preferred by humans, while also ensuring that the overall distribution of generated text remains close to the original language model distribution.
The authors evaluate RTO-RLHF on a variety of benchmarks, including token-level direct preference optimization and filtered direct preference optimization. Their results show that RTO-RLHF outperforms these existing RLHF methods, indicating that the combined DPO and PPO approach is more effective at aligning language models with human preferences.
Critical Analysis
The authors provide a thorough analysis of the limitations and potential issues with RTO-RLHF. They acknowledge that the token-level optimization objective may be difficult to scale to very large language models, and that further research is needed to improve the computational efficiency of the approach.
Additionally, the authors note that the current implementation of RTO-RLHF assumes access to a well-curated dataset of human preferences, which may not always be available in real-world scenarios. More research is needed to explore how RTO-RLHF can be adapted to work with noisier or more limited preference information.
Finally, the authors highlight the importance of further investigating the long-term behavioral alignment of language models trained using RTO-RLHF, as there may be unexpected consequences or unintended behaviors that arise over time.
Conclusion
The RTO-RLHF approach represents a significant advancement in the field of language model alignment, combining the strengths of DPO and PPO to optimize models for better agreement with human preferences. By focusing on token-level optimization and maintaining overall coherence, the authors have developed a more effective method for training language models to behave in ways that are beneficial to humans.
While the current implementation has some limitations, the authors have identified key areas for future research and improvement. As the development of powerful language models continues, approaches like RTO-RLHF will become increasingly important for ensuring that these models are aligned with human values and priorities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, Yi Wu
0
0
Reinforcement Learning from Human Feedback (RLHF) is currently the most widely used method to align large language models (LLMs) with human preferences. Existing RLHF methods can be roughly categorized as either reward-based or reward-free. Novel applications such as ChatGPT and Claude leverage reward-based methods that first learn a reward model and apply actor-critic algorithms, such as Proximal Policy Optimization (PPO). However, in academic benchmarks, state-of-the-art results are often achieved via reward-free methods, such as Direct Preference Optimization (DPO). Is DPO truly superior to PPO? Why does PPO perform poorly on these benchmarks? In this paper, we first conduct both theoretical and empirical studies on the algorithmic properties of DPO and show that DPO may have fundamental limitations. Moreover, we also comprehensively examine PPO and reveal the key factors for the best performances of PPO in fine-tuning LLMs. Finally, we benchmark DPO and PPO across a collection of RLHF testbeds, ranging from dialogue to code generation. Experiment results demonstrate that PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
4/23/2024

From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function
Rafael Rafailov, Joey Hejna, Ryan Park, Chelsea Finn
0
0
Reinforcement Learning From Human Feedback (RLHF) has been a critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline, direct alignment algorithms such as Direct Preference Optimization (DPO) have emerged as an alternative approach. Although DPO solves the same objective as the standard RLHF setup, there is a mismatch between the two approaches. Standard RLHF deploys reinforcement learning in a specific token-level MDP, while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference, first we theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation. Using our theoretical results, we provide three concrete empirical insights. First, we show that because of its token level interpretation, DPO is able to perform some type of credit assignment. Next, we prove that under the token level formulation, classical search-based algorithms, such as MCTS, which have recently been applied to the language generation space, are equivalent to likelihood-based search on a DPO policy. Empirically we show that a simple beam search yields meaningful improvement over the base DPO policy. Finally, we show how the choice of reference policy causes implicit rewards to decline during training. We conclude by discussing applications of our work, including information elicitation in multi-tun dialogue, reasoning, agentic applications and end-to-end training of multi-model systems.
4/19/2024
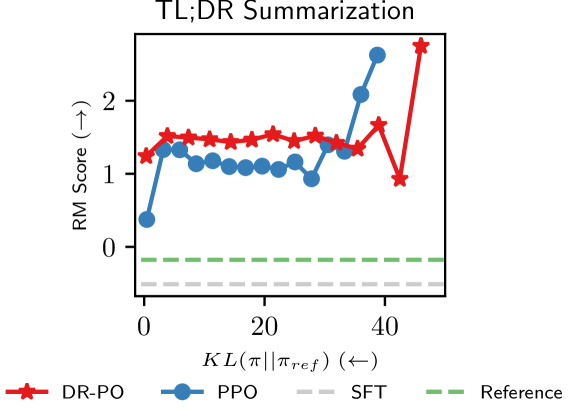
Dataset Reset Policy Optimization for RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kiant'e Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
0
0
Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus. This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees. Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution. In theory, we show that DR-PO learns to perform at least as good as any policy that is covered by the offline dataset under general function approximation with finite sample complexity. In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate. Code for this work can be found at https://github.com/Cornell-RL/drpo.
4/17/2024
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024