DPOT: Auto-Regressive Denoising Operator Transformer for Large-Scale PDE Pre-Training
2403.03542
0
0
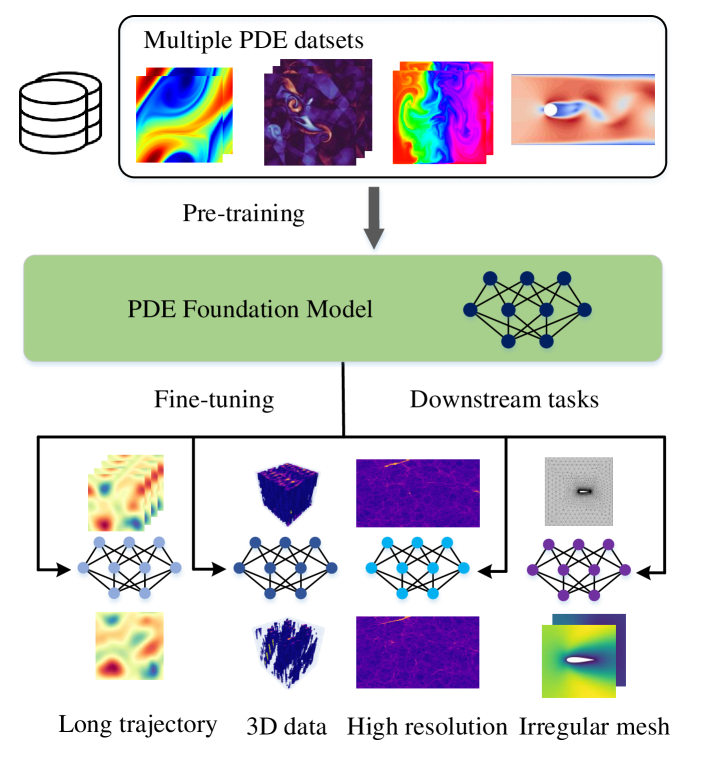
Abstract
Pre-training has been investigated to improve the efficiency and performance of training neural operators in data-scarce settings. However, it is largely in its infancy due to the inherent complexity and diversity, such as long trajectories, multiple scales and varying dimensions of partial differential equations (PDEs) data. In this paper, we present a new auto-regressive denoising pre-training strategy, which allows for more stable and efficient pre-training on PDE data and generalizes to various downstream tasks. Moreover, by designing a flexible and scalable model architecture based on Fourier attention, we can easily scale up the model for large-scale pre-training. We train our PDE foundation model with up to 0.5B parameters on 10+ PDE datasets with more than 100k trajectories. Extensive experiments show that we achieve SOTA on these benchmarks and validate the strong generalizability of our model to significantly enhance performance on diverse downstream PDE tasks like 3D data. Code is available at url{https://github.com/thu-ml/DPOT}.
Create account to get full access
Overview
- This paper introduces DPOT, an Auto-Regressive Denoising Operator Transformer for large-scale PDE pre-training.
- DPOT aims to solve partial differential equations (PDEs) by learning a universal PDE operator that can be applied to different PDE tasks.
- The model is pre-trained on a diverse set of PDE problems, allowing it to learn generalizable features that can be fine-tuned for specific tasks.
Plain English Explanation
The paper presents a new machine learning model called DPOT, which is designed to help solve a wide variety of partial differential equations (PDEs). PDEs are mathematical equations that describe how different quantities, like temperature or pressure, change over time and space. They are used to model many real-world phenomena, from fluid dynamics to quantum mechanics.
DPOT works by learning a "universal PDE operator" - a mathematical function that can be applied to different PDE problems to find their solutions. This operator is trained on a large and diverse set of PDE problems, allowing it to learn general patterns and features that are useful across many domains.
Once the DPOT model is pre-trained on this broad set of PDE tasks, it can then be fine-tuned or adjusted to work on more specific PDE problems. This approach allows DPOT to leverage its broad knowledge to solve new PDE problems more efficiently than starting from scratch.
The key innovation of DPOT is its <a href="https://aimodels.fyi/papers/arxiv/pretraining-codomain-attention-neural-operators-solving-multiphysics">auto-regressive</a> and <a href="https://aimodels.fyi/papers/arxiv/ode-dps-ode-based-diffusion-posterior-sampling">denoising</a> architecture, which helps it capture the complex relationships and patterns in PDEs. This allows DPOT to outperform previous neural network approaches to PDE solving, which struggled to generalize across different problem domains.
Overall, DPOT represents an important step towards building more <a href="https://aimodels.fyi/papers/arxiv/gplasdi-gaussian-process-based-interpretable-latent-space">interpretable</a> and <a href="https://aimodels.fyi/papers/arxiv/automating-discovery-partial-differential-equations-dynamical-systems">generalizable</a> AI systems for solving complex <a href="https://aimodels.fyi/papers/arxiv/towards-foundation-model-partial-differential-equations-multi">multi-physics</a> problems described by PDEs.
Technical Explanation
The key technical innovation of DPOT is its auto-regressive and denoising architecture, which allows it to effectively capture the complex relationships and patterns present in PDEs.
Specifically, DPOT uses an auto-regressive approach, where it generates the solution to a PDE problem one step at a time, conditioning each step on the previous outputs. This helps the model learn the inherent structure and dynamics of the PDE, rather than just fitting a static function.
Additionally, DPOT incorporates denoising mechanisms, which help it handle the noise and uncertainty often present in real-world PDE data. This denoising capability allows DPOT to generalize better to new PDE problems, rather than overfitting to the training data.
The DPOT model is pre-trained on a large and diverse collection of PDE problems, spanning different physical domains and numerical discretizations. This pre-training stage allows the model to learn generalizable features and operators that can be efficiently fine-tuned for specific PDE tasks.
Extensive experiments demonstrate that DPOT outperforms previous neural network approaches to PDE solving, particularly on complex, multi-physics problems. The model's auto-regressive and denoising capabilities contribute to its strong performance, as do the benefits of pre-training on a broad range of PDE tasks.
Critical Analysis
The paper presents a compelling approach to PDE solving, but it's important to consider some potential limitations and areas for further research.
One key challenge is the reliance on a diverse pre-training dataset. While the authors have made efforts to curate a broad collection of PDE problems, there may be limitations in the types of PDEs represented. It would be valuable to further explore the model's performance on a wider range of PDE domains, including those not covered in the pre-training data.
Additionally, the paper does not provide extensive analysis of the model's interpretability or the insights it can offer into the underlying PDE dynamics. As the authors note, improving the interpretability of neural PDE solvers is an important direction for future work.
Finally, while DPOT demonstrates strong performance on the evaluated tasks, it would be helpful to understand its computational efficiency and scalability, particularly for large-scale, high-resolution PDE problems. Comparing DPOT's runtime and memory requirements to traditional numerical PDE solvers could provide valuable insights.
Conclusion
Overall, the DPOT model presented in this paper represents a significant advancement in the field of neural PDE solvers. By leveraging auto-regressive and denoising techniques, along with broad pre-training, DPOT shows promising results in solving complex, multi-physics PDE problems.
As the authors note, this work lays the foundation for more interpretable and generalizable AI systems for modeling physical phenomena described by PDEs. Further research to address the identified limitations and explore the model's broader applicability could lead to even more impactful applications in fields like fluid dynamics, materials science, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Strategies for Pretraining Neural Operators
Anthony Zhou, Cooper Lorsung, AmirPouya Hemmasian, Amir Barati Farimani
0
0
Pretraining for partial differential equation (PDE) modeling has recently shown promise in scaling neural operators across datasets to improve generalizability and performance. Despite these advances, our understanding of how pretraining affects neural operators is still limited; studies generally propose tailored architectures and datasets that make it challenging to compare or examine different pretraining frameworks. To address this, we compare various pretraining methods without optimizing architecture choices to characterize pretraining dynamics on different models and datasets as well as to understand its scaling and generalization behavior. We find that pretraining is highly dependent on model and dataset choices, but in general transfer learning or physics-based pretraining strategies work best. In addition, pretraining performance can be further improved by using data augmentations. Lastly, pretraining is additionally beneficial when fine-tuning in scarce data regimes or when generalizing to downstream data similar to the pretraining distribution. Through providing insights into pretraining neural operators for physics prediction, we hope to motivate future work in developing and evaluating pretraining methods for PDEs.
6/13/2024
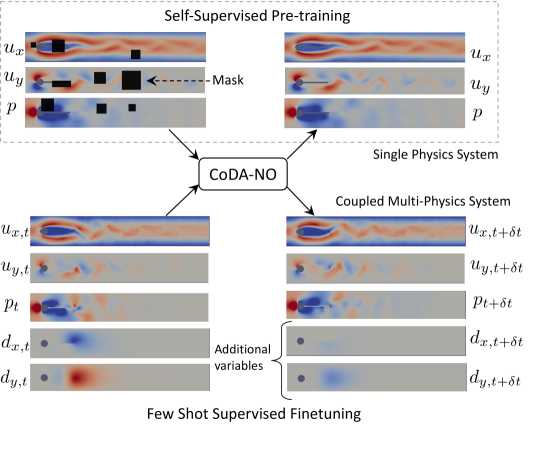
Pretraining Codomain Attention Neural Operators for Solving Multiphysics PDEs
Md Ashiqur Rahman, Robert Joseph George, Mogab Elleithy, Daniel Leibovici, Zongyi Li, Boris Bonev, Colin White, Julius Berner, Raymond A. Yeh, Jean Kossaifi, Kamyar Azizzadenesheli, Anima Anandkumar
0
0
Existing neural operator architectures face challenges when solving multiphysics problems with coupled partial differential equations (PDEs), due to complex geometries, interactions between physical variables, and the lack of large amounts of high-resolution training data. To address these issues, we propose Codomain Attention Neural Operator (CoDA-NO), which tokenizes functions along the codomain or channel space, enabling self-supervised learning or pretraining of multiple PDE systems. Specifically, we extend positional encoding, self-attention, and normalization layers to the function space. CoDA-NO can learn representations of different PDE systems with a single model. We evaluate CoDA-NO's potential as a backbone for learning multiphysics PDEs over multiple systems by considering few-shot learning settings. On complex downstream tasks with limited data, such as fluid flow simulations and fluid-structure interactions, we found CoDA-NO to outperform existing methods on the few-shot learning task by over $36%$. The code is available at https://github.com/ashiq24/CoDA-NO.
4/8/2024
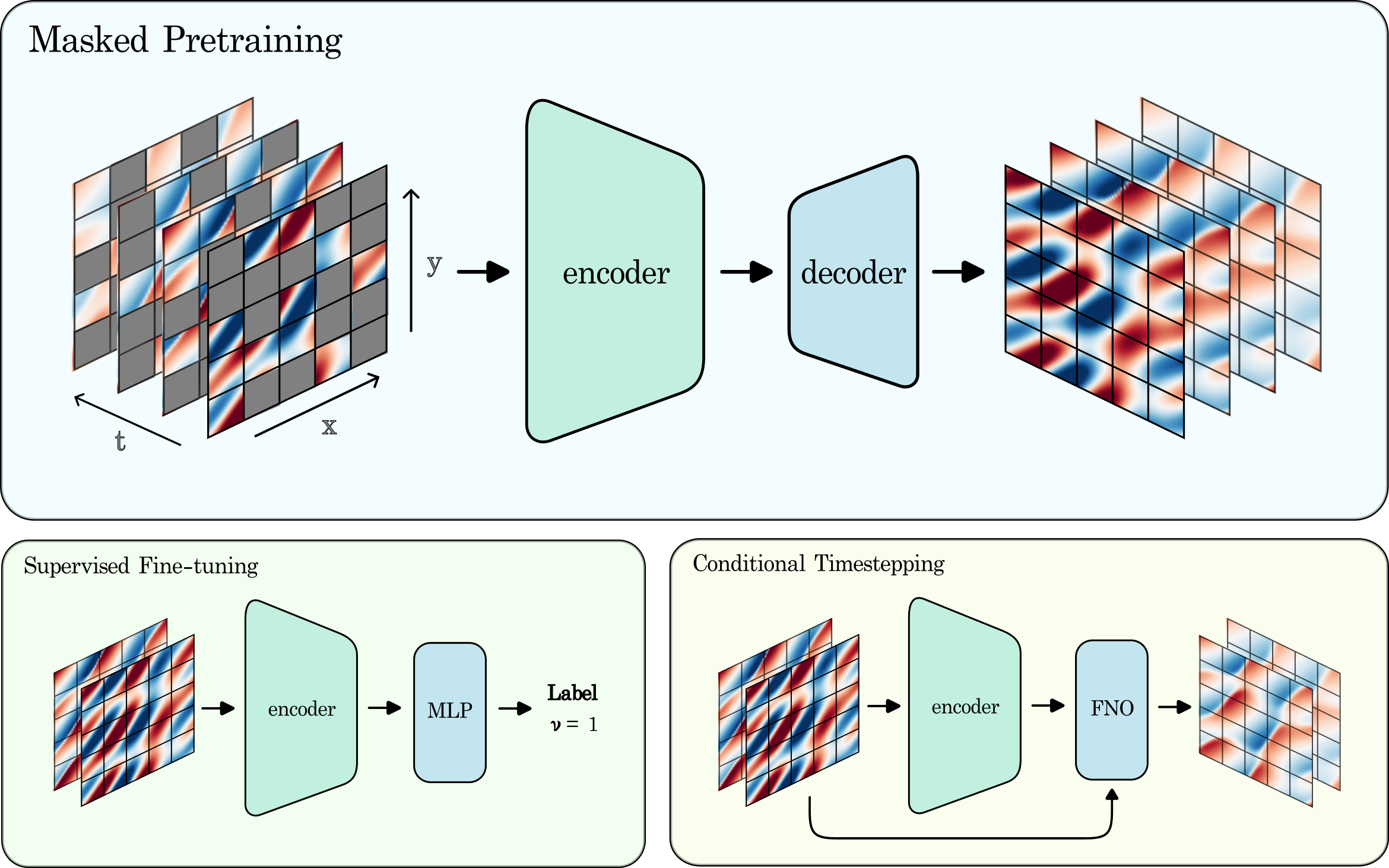
Masked Autoencoders are PDE Learners
Anthony Zhou, Amir Barati Farimani
0
0
Neural solvers for partial differential equations (PDEs) have great potential to generate fast and accurate physics solutions, yet their practicality is currently limited by their generalizability. PDEs evolve over broad scales and exhibit diverse behaviors; predicting these phenomena will require learning representations across a wide variety of inputs which may encompass different coefficients, boundary conditions, resolutions, or even equations. As a step towards generalizable PDE modeling, we adapt masked pretraining for physics problems. Through self-supervised learning across PDEs, masked autoencoders can consolidate heterogeneous physics to learn meaningful latent representations and perform latent PDE arithmetic in this space. Furthermore, we demonstrate that masked pretraining can improve PDE coefficient regression and the classification of PDE features. Lastly, conditioning neural solvers on learned latent representations can improve time-stepping and super-resolution performance across a variety of coefficients, discretizations, or boundary conditions, as well as on unseen PDEs. We hope that masked pretraining can emerge as a unifying method across large, unlabeled, and heterogeneous datasets to learn latent physics at scale.
5/30/2024
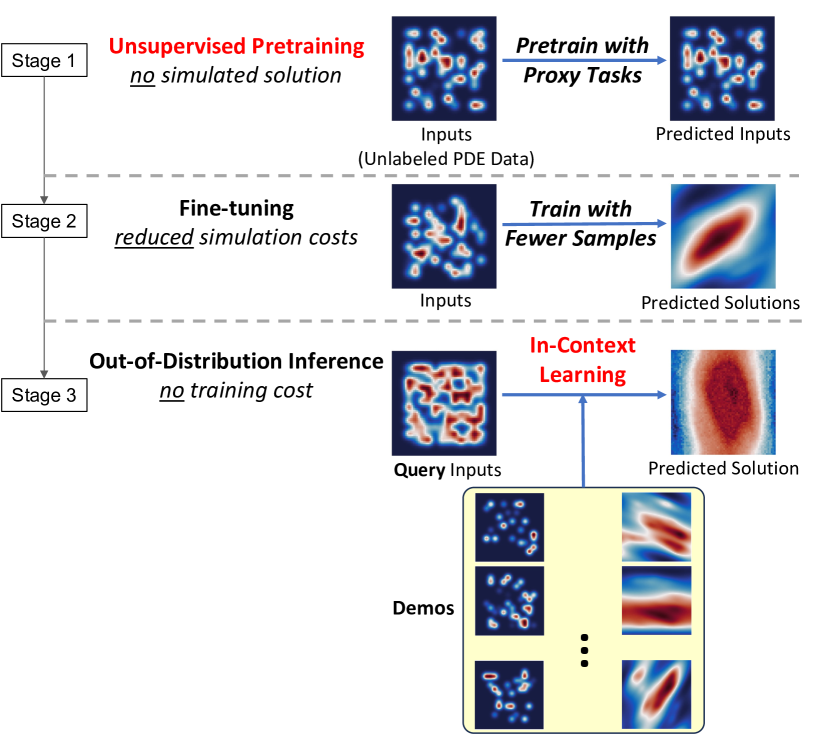
Data-Efficient Operator Learning via Unsupervised Pretraining and In-Context Learning
Wuyang Chen, Jialin Song, Pu Ren, Shashank Subramanian, Dmitriy Morozov, Michael W. Mahoney
0
0
Recent years have witnessed the promise of coupling machine learning methods and physical domainspecific insights for solving scientific problems based on partial differential equations (PDEs). However, being data-intensive, these methods still require a large amount of PDE data. This reintroduces the need for expensive numerical PDE solutions, partially undermining the original goal of avoiding these expensive simulations. In this work, seeking data efficiency, we design unsupervised pretraining for PDE operator learning. To reduce the need for training data with heavy simulation costs, we mine unlabeled PDE data without simulated solutions, and pretrain neural operators with physics-inspired reconstruction-based proxy tasks. To improve out-of-distribution performance, we further assist neural operators in flexibly leveraging in-context learning methods, without incurring extra training costs or designs. Extensive empirical evaluations on a diverse set of PDEs demonstrate that our method is highly data-efficient, more generalizable, and even outperforms conventional vision-pretrained models.
6/14/2024