Strategies for Pretraining Neural Operators
2406.08473
0
0

Abstract
Pretraining for partial differential equation (PDE) modeling has recently shown promise in scaling neural operators across datasets to improve generalizability and performance. Despite these advances, our understanding of how pretraining affects neural operators is still limited; studies generally propose tailored architectures and datasets that make it challenging to compare or examine different pretraining frameworks. To address this, we compare various pretraining methods without optimizing architecture choices to characterize pretraining dynamics on different models and datasets as well as to understand its scaling and generalization behavior. We find that pretraining is highly dependent on model and dataset choices, but in general transfer learning or physics-based pretraining strategies work best. In addition, pretraining performance can be further improved by using data augmentations. Lastly, pretraining is additionally beneficial when fine-tuning in scarce data regimes or when generalizing to downstream data similar to the pretraining distribution. Through providing insights into pretraining neural operators for physics prediction, we hope to motivate future work in developing and evaluating pretraining methods for PDEs.
Create account to get full access
Overview
- This paper presents strategies for pretraining neural operators, which are a type of machine learning model for solving partial differential equations (PDEs).
- The authors explore different pretraining approaches to improve the performance and generalization of neural operators.
- Key strategies include using self-supervised learning, transfer learning, and physics-informed neural networks.
Plain English Explanation
Neural operators are a powerful tool for solving complex PDEs, which are mathematical equations that describe physical processes like fluid flow or heat transfer. These models can learn to approximate the solutions to PDEs directly from data, without requiring explicit knowledge of the underlying physics.
However, training neural operators can be challenging, as they often require large amounts of high-quality training data that may be difficult or expensive to obtain. The authors of this paper investigate different pretraining approaches to address this issue.
One key strategy they explore is self-supervised learning, where the model is first trained on a related but easier task, such as predicting the next step in a sequence of PDE solutions. This pre-training can help the model learn useful representations and patterns that can then be fine-tuned for the target PDE problem.
The authors also investigate transfer learning approaches, where the neural operator is first trained on a related PDE problem and then adapted to the target problem. This can be particularly effective when the target PDE is similar to the source PDE, as the model can leverage the knowledge gained from the previous task.
Finally, the paper explores the use of physics-informed neural networks, which incorporate known physical constraints and principles into the neural network architecture. This can help the model learn more accurate and generalizable representations, by ensuring that the learned solutions satisfy the underlying physics.
Overall, this paper provides valuable insights into the effective pretraining of neural operators, which can significantly improve their performance and applicability in a wide range of scientific and engineering domains.
Technical Explanation
The paper begins by reviewing the related work on pretraining strategies for neural operators, including self-supervised learning, transfer learning, and physics-informed neural networks.
The authors then present several pretraining approaches and experimentally evaluate their effectiveness on a range of PDE problems. One approach involves pretraining the neural operator on a self-supervised task, such as predicting the next step in a sequence of PDE solutions. The intuition is that this can help the model learn useful representations and patterns that can be leveraged for the target PDE problem.
Another strategy is to use transfer learning, where the neural operator is first trained on a related PDE problem and then fine-tuned on the target problem. The authors demonstrate that this can be particularly effective when the target PDE is similar to the source PDE, as the model can reuse the knowledge gained from the previous task.
The paper also explores the use of physics-informed neural networks, where the neural operator architecture is designed to incorporate known physical constraints and principles. This can help the model learn more accurate and generalizable representations, as the learned solutions must satisfy the underlying physics.
The authors conduct extensive experiments on a variety of PDE problems, including the Burgers' equation, the Poisson equation, and the Navier-Stokes equation. They compare the performance of the different pretraining strategies and show that they can significantly improve the accuracy and robustness of the neural operators compared to training from scratch.
Critical Analysis
The paper presents a thorough and well-designed study on pretraining strategies for neural operators. The authors have carefully considered the existing research in this area and have proposed several novel approaches that demonstrate promising results.
One potential limitation of the work is that the experiments are primarily focused on relatively simple PDE problems, such as the Burgers' equation and the Poisson equation. It would be interesting to see how the proposed pretraining strategies perform on more complex and realistic PDE problems, such as those encountered in fluid dynamics, climate modeling, or materials science.
Additionally, the paper does not provide a detailed analysis of the computational and memory requirements of the different pretraining approaches. This information would be valuable for practitioners who need to choose the most appropriate pretraining strategy for their specific use case and resource constraints.
Another area for further research could be the development of more sophisticated pretraining techniques that can effectively leverage the underlying physical principles and constraints of the PDE problems. For example, the authors mention the use of physics-informed neural networks, but there may be other ways to incorporate domain-specific knowledge into the pretraining process.
Overall, this paper makes a valuable contribution to the field of neural operators and provides a solid foundation for future research in this area. The proposed pretraining strategies have the potential to significantly improve the performance and applicability of these models in a wide range of scientific and engineering domains.
Conclusion
This paper presents several effective strategies for pretraining neural operators, which are a powerful class of machine learning models for solving partial differential equations (PDEs). The authors explore approaches such as self-supervised learning, transfer learning, and physics-informed neural networks, and demonstrate their ability to improve the accuracy and generalization of neural operators on a variety of PDE problems.
The insights and techniques described in this paper have important implications for the broader field of scientific machine learning, as they can help overcome the challenges of training data scarcity and improve the performance of neural models in simulating complex physical phenomena. By leveraging pretraining and incorporating domain-specific knowledge, the authors show that neural operators can be made more robust and effective, paving the way for their widespread adoption in fields like fluid dynamics, materials science, and climate modeling.
As the field of neural operators continues to evolve, this paper provides a valuable contribution and a foundation for future research in this area. By building on the strategies outlined here and exploring new ways to incorporate physical constraints and principles, researchers and practitioners can further enhance the capabilities of these models and unlock their full potential in solving the most challenging PDE problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
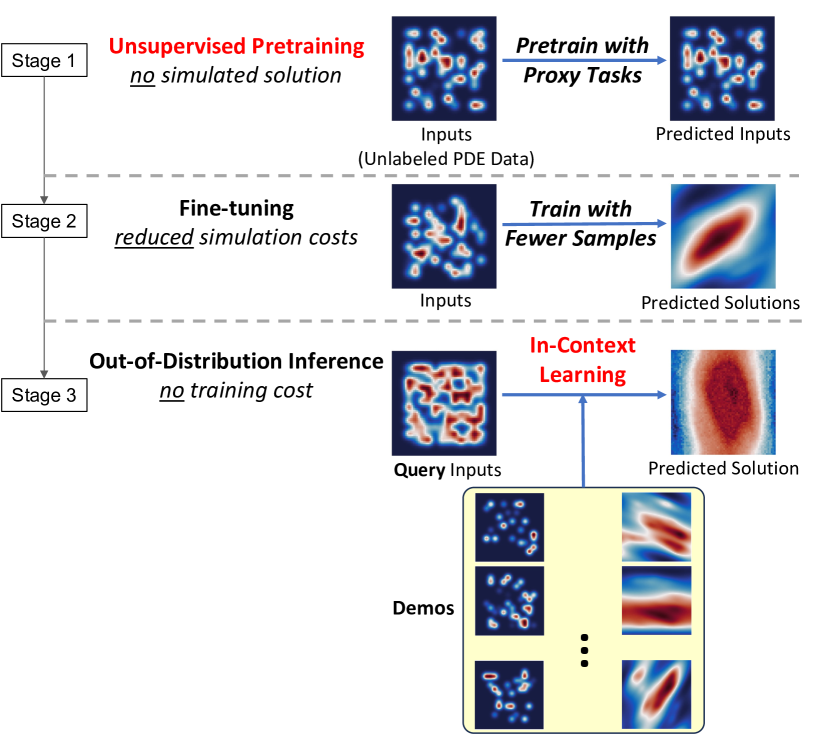
Data-Efficient Operator Learning via Unsupervised Pretraining and In-Context Learning
Wuyang Chen, Jialin Song, Pu Ren, Shashank Subramanian, Dmitriy Morozov, Michael W. Mahoney
0
0
Recent years have witnessed the promise of coupling machine learning methods and physical domainspecific insights for solving scientific problems based on partial differential equations (PDEs). However, being data-intensive, these methods still require a large amount of PDE data. This reintroduces the need for expensive numerical PDE solutions, partially undermining the original goal of avoiding these expensive simulations. In this work, seeking data efficiency, we design unsupervised pretraining for PDE operator learning. To reduce the need for training data with heavy simulation costs, we mine unlabeled PDE data without simulated solutions, and pretrain neural operators with physics-inspired reconstruction-based proxy tasks. To improve out-of-distribution performance, we further assist neural operators in flexibly leveraging in-context learning methods, without incurring extra training costs or designs. Extensive empirical evaluations on a diverse set of PDEs demonstrate that our method is highly data-efficient, more generalizable, and even outperforms conventional vision-pretrained models.
6/14/2024
🛸
PICL: Physics Informed Contrastive Learning for Partial Differential Equations
Cooper Lorsung, Amir Barati Farimani
0
0
Neural operators have recently grown in popularity as Partial Differential Equation (PDE) surrogate models. Learning solution functionals, rather than functions, has proven to be a powerful approach to calculate fast, accurate solutions to complex PDEs. While much work has been done evaluating neural operator performance on a wide variety of surrogate modeling tasks, these works normally evaluate performance on a single equation at a time. In this work, we develop a novel contrastive pretraining framework utilizing Generalized Contrastive Loss that improves neural operator generalization across multiple governing equations simultaneously. Governing equation coefficients are used to measure ground-truth similarity between systems. A combination of physics-informed system evolution and latent-space model output are anchored to input data and used in our distance function. We find that physics-informed contrastive pretraining improves accuracy for the Fourier Neural Operator in fixed-future and autoregressive rollout tasks for the 1D and 2D Heat, Burgers', and linear advection equations.
6/18/2024

An operator preconditioning perspective on training in physics-informed machine learning
Tim De Ryck, Florent Bonnet, Siddhartha Mishra, Emmanuel de B'ezenac
0
0
In this paper, we investigate the behavior of gradient descent algorithms in physics-informed machine learning methods like PINNs, which minimize residuals connected to partial differential equations (PDEs). Our key result is that the difficulty in training these models is closely related to the conditioning of a specific differential operator. This operator, in turn, is associated to the Hermitian square of the differential operator of the underlying PDE. If this operator is ill-conditioned, it results in slow or infeasible training. Therefore, preconditioning this operator is crucial. We employ both rigorous mathematical analysis and empirical evaluations to investigate various strategies, explaining how they better condition this critical operator, and consequently improve training.
5/6/2024

Physics-informed Mesh-independent Deep Compositional Operator Network
Weiheng Zhong, Hadi Meidani
0
0
Solving parametric Partial Differential Equations (PDEs) for a broad range of parameters is a critical challenge in scientific computing. To this end, neural operators, which learn mappings from parameters to solutions, have been successfully used. However, the training of neural operators typically demands large training datasets, the acquisition of which can be prohibitively expensive. To address this challenge, physics-informed training can offer a cost-effective strategy. However, current physics-informed neural operators face limitations, either in handling irregular domain shapes or in generalization to various discretizations of PDE parameters with variable mesh sizes. In this research, we introduce a novel physics-informed model architecture which can generalize to parameter discretizations of variable size and irregular domain shapes. Particularly, inspired by deep operator neural networks, our model involves a discretization-independent learning of parameter embedding repeatedly, and this parameter embedding is integrated with the response embeddings through multiple compositional layers, for more expressivity. Numerical results demonstrate the accuracy and efficiency of the proposed method.
4/23/2024