DragPoser: Motion Reconstruction from Variable Sparse Tracking Signals via Latent Space Optimization
2406.14567
0
0
Abstract
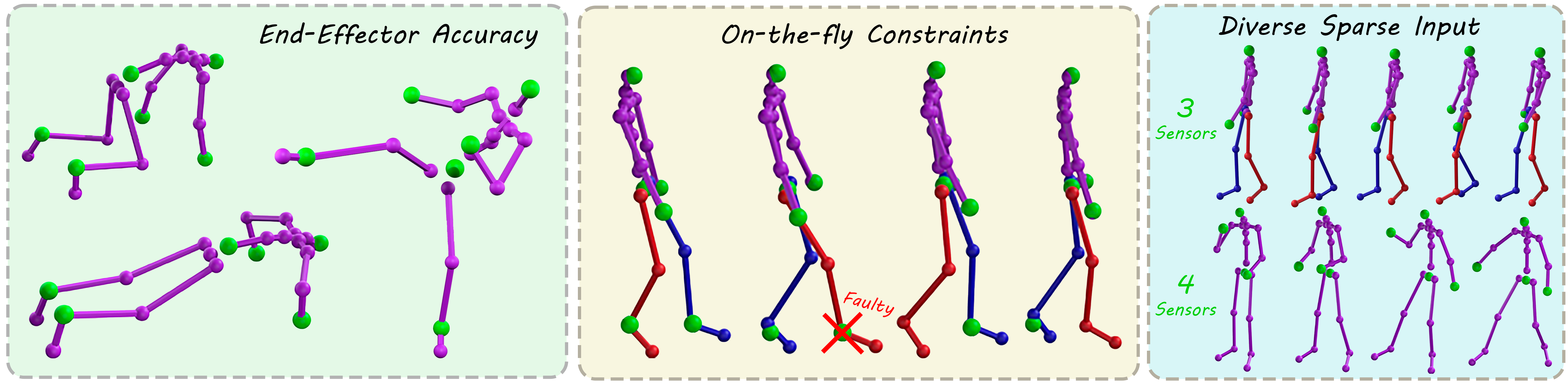
High-quality motion reconstruction that follows the user's movements can be achieved by high-end mocap systems with many sensors. However, obtaining such animation quality with fewer input devices is gaining popularity as it brings mocap closer to the general public. The main challenges include the loss of end-effector accuracy in learning-based approaches, or the lack of naturalness and smoothness in IK-based solutions. In addition, such systems are often finely tuned to a specific number of trackers and are highly sensitive to missing data e.g., in scenarios where a sensor is occluded or malfunctions. In response to these challenges, we introduce DragPoser, a novel deep-learning-based motion reconstruction system that accurately represents hard and dynamic on-the-fly constraints, attaining real-time high end-effectors position accuracy. This is achieved through a pose optimization process within a structured latent space. Our system requires only one-time training on a large human motion dataset, and then constraints can be dynamically defined as losses, while the pose is iteratively refined by computing the gradients of these losses within the latent space. To further enhance our approach, we incorporate a Temporal Predictor network, which employs a Transformer architecture to directly encode temporality within the latent space. This network ensures the pose optimization is confined to the manifold of valid poses and also leverages past pose data to predict temporally coherent poses. Results demonstrate that DragPoser surpasses both IK-based and the latest data-driven methods in achieving precise end-effector positioning, while it produces natural poses and temporally coherent motion. In addition, our system showcases robustness against on-the-fly constraint modifications, and exhibits exceptional adaptability to various input configurations and changes.
Create account to get full access
Overview
- This paper presents DragPoser, a novel method for reconstructing human motion from variable sparse tracking signals using latent space optimization.
- The approach aims to enable scalable motion capture and tracking using wearable devices with limited sensors.
- The method leverages a learned latent space representation to reconstruct full-body poses from sparse input data.
Plain English Explanation
The DragPoser system is designed to reconstruct detailed human motion, such as the movement of a person's arms, legs, and body, using only sparse or limited tracking data. Traditional motion capture systems often require complex setups with many sensors, which can be impractical or expensive. DragPoser offers a solution by using a machine learning model to infer the complete motion from just a few tracking signals.
The key idea is to learn a latent space representation - a compact, abstract encoding of the human motion data. This latent space acts as an intermediary between the sparse input signals and the full-body pose. By optimizing within this latent space, DragPoser can reconstruct detailed motion that is consistent with the limited input data. This allows for more scalable and accessible motion capture, potentially using wearable devices with just a handful of sensors.
Technical Explanation
The DragPoser framework consists of three main components:
- A motion capture encoder that maps sparse input tracking signals to a low-dimensional latent space representation.
- A latent space optimizer that reconstructs the full-body pose by finding the latent code that best matches the input data.
- A pose decoder that translates the optimized latent code back into a complete 3D body pose.
The key innovation is the use of this latent space optimization approach, which allows DragPoser to handle variable and sparse input data. This is in contrast to prior work that relied on more constrained or fixed sensor configurations. DragPoser's ability to work with limited tracking signals makes it well-suited for applications like wearable motion capture or free-moving object reconstruction.
Critical Analysis
The paper provides a thorough evaluation of the DragPoser system, demonstrating its ability to reconstruct high-quality motion from sparse input data. However, the authors note that the approach is currently limited to offline processing and may struggle with real-time applications that require extremely low latency.
Additionally, the performance of DragPoser is highly dependent on the quality and coverage of the training data used to learn the latent space representation. Further research may be needed to address potential biases or generalization issues when applying the method to diverse human movements or novel scenarios.
Conclusion
The DragPoser system represents a significant advancement in the field of motion capture and tracking, enabling detailed human pose reconstruction from variable sparse input signals. By leveraging latent space optimization, the approach demonstrates the potential for more scalable and accessible motion capture solutions, particularly in the context of wearable devices and free-moving object tracking. While the method has some limitations, the insights and techniques presented in this paper open up new avenues for future research and practical applications in human-computer interaction, animation, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
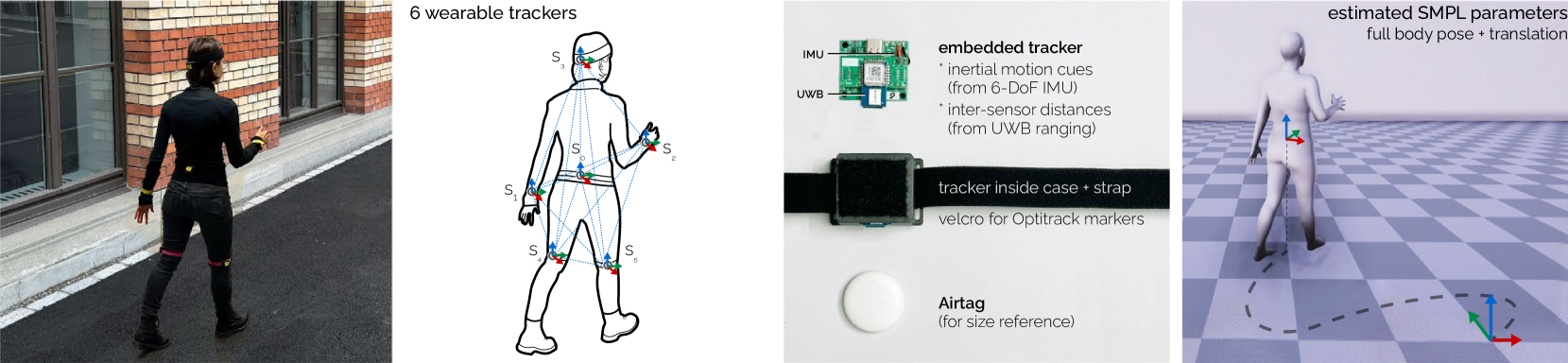
Ultra Inertial Poser: Scalable Motion Capture and Tracking from Sparse Inertial Sensors and Ultra-Wideband Ranging
Rayan Armani, Changlin Qian, Jiaxi Jiang, Christian Holz
0
0
While camera-based capture systems remain the gold standard for recording human motion, learning-based tracking systems based on sparse wearable sensors are gaining popularity. Most commonly, they use inertial sensors, whose propensity for drift and jitter have so far limited tracking accuracy. In this paper, we propose Ultra Inertial Poser, a novel 3D full body pose estimation method that constrains drift and jitter in inertial tracking via inter-sensor distances. We estimate these distances across sparse sensor setups using a lightweight embedded tracker that augments inexpensive off-the-shelf 6D inertial measurement units with ultra-wideband radio-based ranging$-$dynamically and without the need for stationary reference anchors. Our method then fuses these inter-sensor distances with the 3D states estimated from each sensor Our graph-based machine learning model processes the 3D states and distances to estimate a person's 3D full body pose and translation. To train our model, we synthesize inertial measurements and distance estimates from the motion capture database AMASS. For evaluation, we contribute a novel motion dataset of 10 participants who performed 25 motion types, captured by 6 wearable IMU+UWB trackers and an optical motion capture system, totaling 200 minutes of synchronized sensor data (UIP-DB). Our extensive experiments show state-of-the-art performance for our method over PIP and TIP, reducing position error from $13.62$ to $10.65cm$ ($22%$ better) and lowering jitter from $1.56$ to $0.055km/s^3$ (a reduction of $97%$).
5/1/2024
🤷
ImitationNet: Unsupervised Human-to-Robot Motion Retargeting via Shared Latent Space
Yashuai Yan, Esteve Valls Mascaro, Dongheui Lee
0
0
This paper introduces a novel deep-learning approach for human-to-robot motion retargeting, enabling robots to mimic human poses accurately. Contrary to prior deep-learning-based works, our method does not require paired human-to-robot data, which facilitates its translation to new robots. First, we construct a shared latent space between humans and robots via adaptive contrastive learning that takes advantage of a proposed cross-domain similarity metric between the human and robot poses. Additionally, we propose a consistency term to build a common latent space that captures the similarity of the poses with precision while allowing direct robot motion control from the latent space. For instance, we can generate in-between motion through simple linear interpolation between two projected human poses. We conduct a comprehensive evaluation of robot control from diverse modalities (i.e., texts, RGB videos, and key poses), which facilitates robot control for non-expert users. Our model outperforms existing works regarding human-to-robot retargeting in terms of efficiency and precision. Finally, we implemented our method in a real robot with self-collision avoidance through a whole-body controller to showcase the effectiveness of our approach. More information on our website https://evm7.github.io/UnsH2R/
4/9/2024

Purposer: Putting Human Motion Generation in Context
Nicolas Ugrinovic, Thomas Lucas, Fabien Baradel, Philippe Weinzaepfel, Gregory Rogez, Francesc Moreno-Noguer
0
0
We present a novel method to generate human motion to populate 3D indoor scenes. It can be controlled with various combinations of conditioning signals such as a path in a scene, target poses, past motions, and scenes represented as 3D point clouds. State-of-the-art methods are either models specialized to one single setting, require vast amounts of high-quality and diverse training data, or are unconditional models that do not integrate scene or other contextual information. As a consequence, they have limited applicability and rely on costly training data. To address these limitations, we propose a new method ,dubbed Purposer, based on neural discrete representation learning. Our model is capable of exploiting, in a flexible manner, different types of information already present in open access large-scale datasets such as AMASS. First, we encode unconditional human motion into a discrete latent space. Second, an autoregressive generative model, conditioned with key contextual information, either with prompting or additive tokens, and trained for next-step prediction in this space, synthesizes sequences of latent indices. We further design a novel conditioning block to handle future conditioning information in such a causal model by using a network with two branches to compute separate stacks of features. In this manner, Purposer can generate realistic motion sequences in diverse test scenes. Through exhaustive evaluation, we demonstrate that our multi-contextual solution outperforms existing specialized approaches for specific contextual information, both in terms of quality and diversity. Our model is trained with short sequences, but a byproduct of being able to use various conditioning signals is that at test time different combinations can be used to chain short sequences together and generate long motions within a context scene.
4/22/2024
A Mixture of Experts Approach to 3D Human Motion Prediction
Edmund Shieh, Joshua Lee Franco, Kang Min Bae, Tej Lalvani
0
0
This project addresses the challenge of human motion prediction, a critical area for applications such as au- tonomous vehicle movement detection. Previous works have emphasized the need for low inference times to provide real time performance for applications like these. Our primary objective is to critically evaluate existing model ar- chitectures, identifying their advantages and opportunities for improvement by replicating the state-of-the-art (SOTA) Spatio-Temporal Transformer model as best as possible given computational con- straints. These models have surpassed the limitations of RNN-based models and have demonstrated the ability to generate plausible motion sequences over both short and long term horizons through the use of spatio-temporal rep- resentations. We also propose a novel architecture to ad- dress challenges of real time inference speed by incorpo- rating a Mixture of Experts (MoE) block within the Spatial- Temporal (ST) attention layer. The particular variation that is used is Soft MoE, a fully-differentiable sparse Transformer that has shown promising ability to enable larger model capacity at lower inference cost. We make out code publicly available at https://github.com/edshieh/motionprediction
5/13/2024