DRCT: Saving Image Super-resolution away from Information Bottleneck
2404.00722
0
0
Abstract
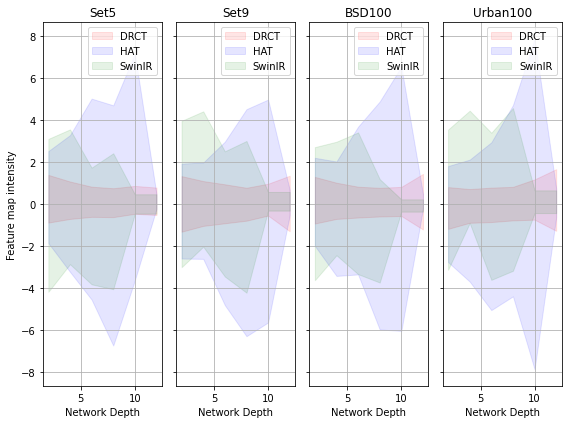
In recent years, Vision Transformer-based approaches for low-level vision tasks have achieved widespread success. Unlike CNN-based models, Transformers are more adept at capturing long-range dependencies, enabling the reconstruction of images utilizing non-local information. In the domain of super-resolution, Swin-transformer-based models have become mainstream due to their capability of global spatial information modeling and their shifting-window attention mechanism that facilitates the interchange of information between different windows. Many researchers have enhanced model performance by expanding the receptive fields or designing meticulous networks, yielding commendable results. However, we observed that it is a general phenomenon for the feature map intensity to be abruptly suppressed to small values towards the network's end. This implies an information bottleneck and a diminishment of spatial information, implicitly limiting the model's potential. To address this, we propose the Dense-residual-connected Transformer (DRCT), aimed at mitigating the loss of spatial information and stabilizing the information flow through dense-residual connections between layers, thereby unleashing the model's potential and saving the model away from information bottleneck. Experiment results indicate that our approach surpasses state-of-the-art methods on benchmark datasets and performs commendably at the NTIRE-2024 Image Super-Resolution (x4) Challenge. Our source code is available at https://github.com/ming053l/DRCT
Create account to get full access
Overview
- This paper proposes a new approach called DRCT (Decoupled Reconstruction and Correlation Transformation) for image super-resolution, which aims to overcome the limitations of existing information bottleneck-based methods.
- The key idea is to decouple the reconstruction and correlation transformation tasks, allowing the model to learn more effective representations for super-resolution.
- The authors demonstrate that DRCT outperforms state-of-the-art vision transformer-based super-resolution models on several benchmark datasets.
Plain English Explanation
Image super-resolution is the process of taking a low-quality image and generating a high-quality version of it. This is a challenging task because a lot of the original image information is lost when the resolution is reduced.
Many existing super-resolution models use an "information bottleneck" approach, where the model tries to compress the input image into a compact representation before reconstructing the high-quality output. The authors argue that this approach can limit the model's ability to learn effective representations for super-resolution.
To address this, the DRCT model separates the reconstruction and correlation transformation tasks. Instead of compressing the input into a bottleneck, DRCT first reconstructs the high-quality image, and then applies a separate correlation transformation to refine the details. This allows the model to learn more powerful representations for super-resolution without being constrained by the information bottleneck.
The authors show that DRCT outperforms other state-of-the-art vision transformer-based super-resolution models on several benchmark datasets. This suggests that decoupling the reconstruction and correlation tasks can be a powerful approach for improving image super-resolution.
Technical Explanation
The DRCT model consists of two main components: a reconstruction module and a correlation transformation module. The reconstruction module takes the low-quality input image and generates an initial high-quality reconstruction. The correlation transformation module then refines this reconstruction by learning to capture the spatial relationships between different image regions.
Importantly, the reconstruction and correlation transformation tasks are trained separately, rather than being coupled through an information bottleneck. This allows the model to learn more effective representations for super-resolution without being constrained by the need to compress the input into a compact form.
The authors evaluate DRCT on several benchmark super-resolution datasets, including DIV2K and Flickr2K. They show that DRCT outperforms state-of-the-art vision transformer-based models in terms of both quantitative metrics (e.g., PSNR, SSIM) and qualitative visual quality.
Critical Analysis
The authors provide a thorough evaluation of DRCT and demonstrate its superiority over existing vision transformer-based super-resolution models. However, the paper does not discuss potential limitations or areas for further research.
One potential concern is the computational complexity of the DRCT model, as separating the reconstruction and correlation transformation tasks may increase the model size and inference time. The authors could have provided more details on the model's computational efficiency and compared it to other approaches.
Additionally, the paper does not explore the generalizability of DRCT to other image restoration tasks beyond super-resolution, such as denoising or inpainting. Investigating the broader applicability of the DRCT approach could be an interesting direction for future work.
Conclusion
The DRCT model proposed in this paper offers a novel approach to image super-resolution by decoupling the reconstruction and correlation transformation tasks. This allows the model to learn more effective representations for super-resolution, leading to improved performance on several benchmark datasets.
The authors' findings suggest that breaking away from the information bottleneck constraint can be a fruitful direction for advancing image super-resolution and other image restoration tasks. As the field continues to evolve, techniques like DRCT that rethink fundamental architectural choices may unlock new levels of performance and capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Image Super-resolution Reconstruction Network based on Enhanced Swin Transformer via Alternating Aggregation of Local-Global Features
Yuming Huang, Yingpin Chen, Changhui Wu, Hanrong Xie, Binhui Song, Hui Wang
0
0
The Swin Transformer image super-resolution reconstruction network only relies on the long-range relationship of window attention and shifted window attention to explore features. This mechanism has two limitations. On the one hand, it only focuses on global features while ignoring local features. On the other hand, it is only concerned with spatial feature interactions while ignoring channel features and channel interactions, thus limiting its non-linear mapping ability. To address the above limitations, this paper proposes enhanced Swin Transformer modules via alternating aggregation of local-global features. In the local feature aggregation stage, we introduce a shift convolution to realize the interaction between local spatial information and channel information. Then, a block sparse global perception module is introduced in the global feature aggregation stage. In this module, we reorganize the spatial information first, then send the recombination information into a dense layer to implement the global perception. After that, a multi-scale self-attention module and a low-parameter residual channel attention module are introduced to realize information aggregation at different scales. Finally, the proposed network is validated on five publicly available datasets. The experimental results show that the proposed network outperforms the other state-of-the-art super-resolution networks.
4/9/2024

Single Image Super-Resolution Based on Global-Local Information Synergy
Nianzu Qiao, Lamei Di, Changyin Sun
0
0
Although several image super-resolution solutions exist, they still face many challenges. CNN-based algorithms, despite the reduction in computational complexity, still need to improve their accuracy. While Transformer-based algorithms have higher accuracy, their ultra-high computational complexity makes them difficult to be accepted in practical applications. To overcome the existing challenges, a novel super-resolution reconstruction algorithm is proposed in this paper. The algorithm achieves a significant increase in accuracy through a unique design while maintaining a low complexity. The core of the algorithm lies in its cleverly designed Global-Local Information Extraction Module and Basic Block Module. By combining global and local information, the Global-Local Information Extraction Module aims to understand the image content more comprehensively so as to recover the global structure and local details in the image more accurately, which provides rich information support for the subsequent reconstruction process. Experimental results show that the comprehensive performance of the algorithm proposed in this paper is optimal, providing an efficient and practical new solution in the field of super-resolution reconstruction.
5/3/2024
🛸
Hitchhiker's Guide to Super-Resolution: Introduction and Recent Advances
Brian Moser, Federico Raue, Stanislav Frolov, Jorn Hees, Sebastian Palacio, Andreas Dengel
0
0
With the advent of Deep Learning (DL), Super-Resolution (SR) has also become a thriving research area. However, despite promising results, the field still faces challenges that require further research e.g., allowing flexible upsampling, more effective loss functions, and better evaluation metrics. We review the domain of SR in light of recent advances, and examine state-of-the-art models such as diffusion (DDPM) and transformer-based SR models. We present a critical discussion on contemporary strategies used in SR, and identify promising yet unexplored research directions. We complement previous surveys by incorporating the latest developments in the field such as uncertainty-driven losses, wavelet networks, neural architecture search, novel normalization methods, and the latests evaluation techniques. We also include several visualizations for the models and methods throughout each chapter in order to facilitate a global understanding of the trends in the field. This review is ultimately aimed at helping researchers to push the boundaries of DL applied to SR.
4/30/2024
Empowering Image Recovery_ A Multi-Attention Approach
Juan Wen, Yawei Li, Chao Zhang, Weiyan Hou, Radu Timofte, Luc Van Gool
0
0
We propose Diverse Restormer (DART), a novel image restoration method that effectively integrates information from various sources (long sequences, local and global regions, feature dimensions, and positional dimensions) to address restoration challenges. While Transformer models have demonstrated excellent performance in image restoration due to their self-attention mechanism, they face limitations in complex scenarios. Leveraging recent advancements in Transformers and various attention mechanisms, our method utilizes customized attention mechanisms to enhance overall performance. DART, our novel network architecture, employs windowed attention to mimic the selective focusing mechanism of human eyes. By dynamically adjusting receptive fields, it optimally captures the fundamental features crucial for image resolution reconstruction. Efficiency and performance balance are achieved through the LongIR attention mechanism for long sequence image restoration. Integration of attention mechanisms across feature and positional dimensions further enhances the recovery of fine details. Evaluation across five restoration tasks consistently positions DART at the forefront. Upon acceptance, we commit to providing publicly accessible code and models to ensure reproducibility and facilitate further research.
4/10/2024