Empowering Image Recovery_ A Multi-Attention Approach
2404.04617
0
0
Abstract
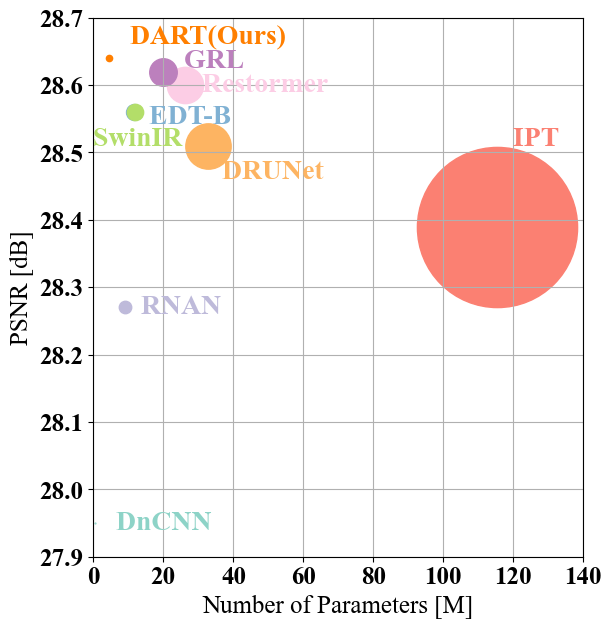
We propose Diverse Restormer (DART), a novel image restoration method that effectively integrates information from various sources (long sequences, local and global regions, feature dimensions, and positional dimensions) to address restoration challenges. While Transformer models have demonstrated excellent performance in image restoration due to their self-attention mechanism, they face limitations in complex scenarios. Leveraging recent advancements in Transformers and various attention mechanisms, our method utilizes customized attention mechanisms to enhance overall performance. DART, our novel network architecture, employs windowed attention to mimic the selective focusing mechanism of human eyes. By dynamically adjusting receptive fields, it optimally captures the fundamental features crucial for image resolution reconstruction. Efficiency and performance balance are achieved through the LongIR attention mechanism for long sequence image restoration. Integration of attention mechanisms across feature and positional dimensions further enhances the recovery of fine details. Evaluation across five restoration tasks consistently positions DART at the forefront. Upon acceptance, we commit to providing publicly accessible code and models to ensure reproducibility and facilitate further research.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a novel multi-attention approach for image recovery tasks
- Leverages different attention mechanisms to capture various aspects of the image
- Claims improved performance over state-of-the-art methods on several image recovery benchmarks
Plain English Explanation
This research paper presents a new way to recover or reconstruct images that have been damaged or distorted. The key idea is to use multiple "attention" mechanisms, which allow the model to focus on different parts of the image at different times. This multi-attention approach is designed to capture more nuanced and comprehensive information about the image, enabling more accurate recovery.
The researchers claim that their proposed method outperforms existing state-of-the-art techniques on standard image recovery benchmarks. This suggests their multi-attention approach is a promising direction for empowering image recovery and restoration tasks, which are important for applications like photo editing, medical imaging, and surveillance.
Technical Explanation
The paper introduces a Multi-Attention Image Recovery (MAIR) model that leverages multiple attention mechanisms to enhance image recovery performance. The model consists of an encoder-decoder architecture with several attention modules integrated throughout.
The attention modules allow the model to dynamically focus on different spatial regions and features of the input image. This helps the model better capture the complex, multi-scale characteristics of image content. The researchers experiment with several attention mechanisms, including self-attention, non-local attention, and spatial-channel attention, and find that combining them leads to the best results.
The MAIR model is evaluated on several image recovery tasks, including image super-resolution, denoising, and inpainting. The results demonstrate the effectiveness of the multi-attention approach, with MAIR outperforming previous state-of-the-art methods across the benchmarks.
Critical Analysis
The paper provides a thorough evaluation of the MAIR model, exploring its performance on a range of image recovery tasks. However, the authors do not discuss potential limitations or caveats of their approach. For example, the computational complexity and runtime of the multi-attention modules are not analyzed, which could be an important practical consideration.
Additionally, the paper would benefit from a more in-depth discussion of the trade-offs between the different attention mechanisms used. While the authors claim that combining them leads to the best results, it's unclear if all the attention modules are equally important or if certain ones contribute more to the overall performance.
Further research could explore the interpretability of the attention maps generated by the MAIR model, which could provide valuable insights into how the multi-attention approach is able to improve image recovery. Analyzing failure cases and edge cases would also help strengthen the claims made in the paper.
Conclusion
This research paper presents a novel multi-attention approach for image recovery tasks, which aims to capture more comprehensive information about the image by leveraging different attention mechanisms. The proposed MAIR model is shown to outperform state-of-the-art methods on several benchmarks, suggesting the effectiveness of the multi-attention approach.
While the paper provides a strong technical foundation, further research is needed to fully understand the model's limitations, trade-offs, and potential for real-world applications. Nonetheless, the work represents an important step forward in empowering image recovery and restoration, with promising implications for a wide range of fields that rely on high-quality visual data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DRCT: Saving Image Super-resolution away from Information Bottleneck
Chih-Chung Hsu, Chia-Ming Lee, Yi-Shiuan Chou
0
0
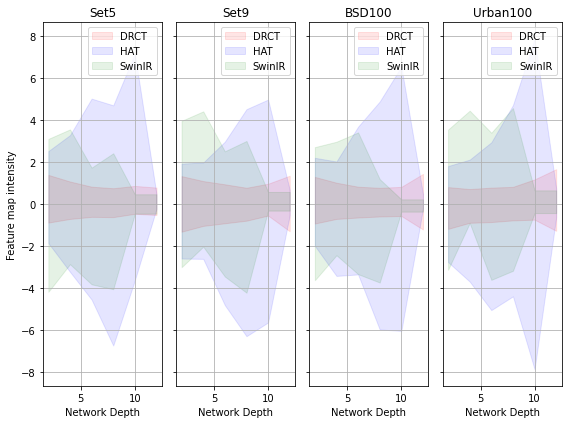
In recent years, Vision Transformer-based approaches for low-level vision tasks have achieved widespread success. Unlike CNN-based models, Transformers are more adept at capturing long-range dependencies, enabling the reconstruction of images utilizing non-local information. In the domain of super-resolution, Swin-transformer-based models have become mainstream due to their capability of global spatial information modeling and their shifting-window attention mechanism that facilitates the interchange of information between different windows. Many researchers have enhanced model performance by expanding the receptive fields or designing meticulous networks, yielding commendable results. However, we observed that it is a general phenomenon for the feature map intensity to be abruptly suppressed to small values towards the network's end. This implies an information bottleneck and a diminishment of spatial information, implicitly limiting the model's potential. To address this, we propose the Dense-residual-connected Transformer (DRCT), aimed at mitigating the loss of spatial information and stabilizing the information flow through dense-residual connections between layers, thereby unleashing the model's potential and saving the model away from information bottleneck. Experiment results indicate that our approach surpasses state-of-the-art methods on benchmark datasets and performs commendably at the NTIRE-2024 Image Super-Resolution (x4) Challenge. Our source code is available at https://github.com/ming053l/DRCT
4/16/2024
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
0
0
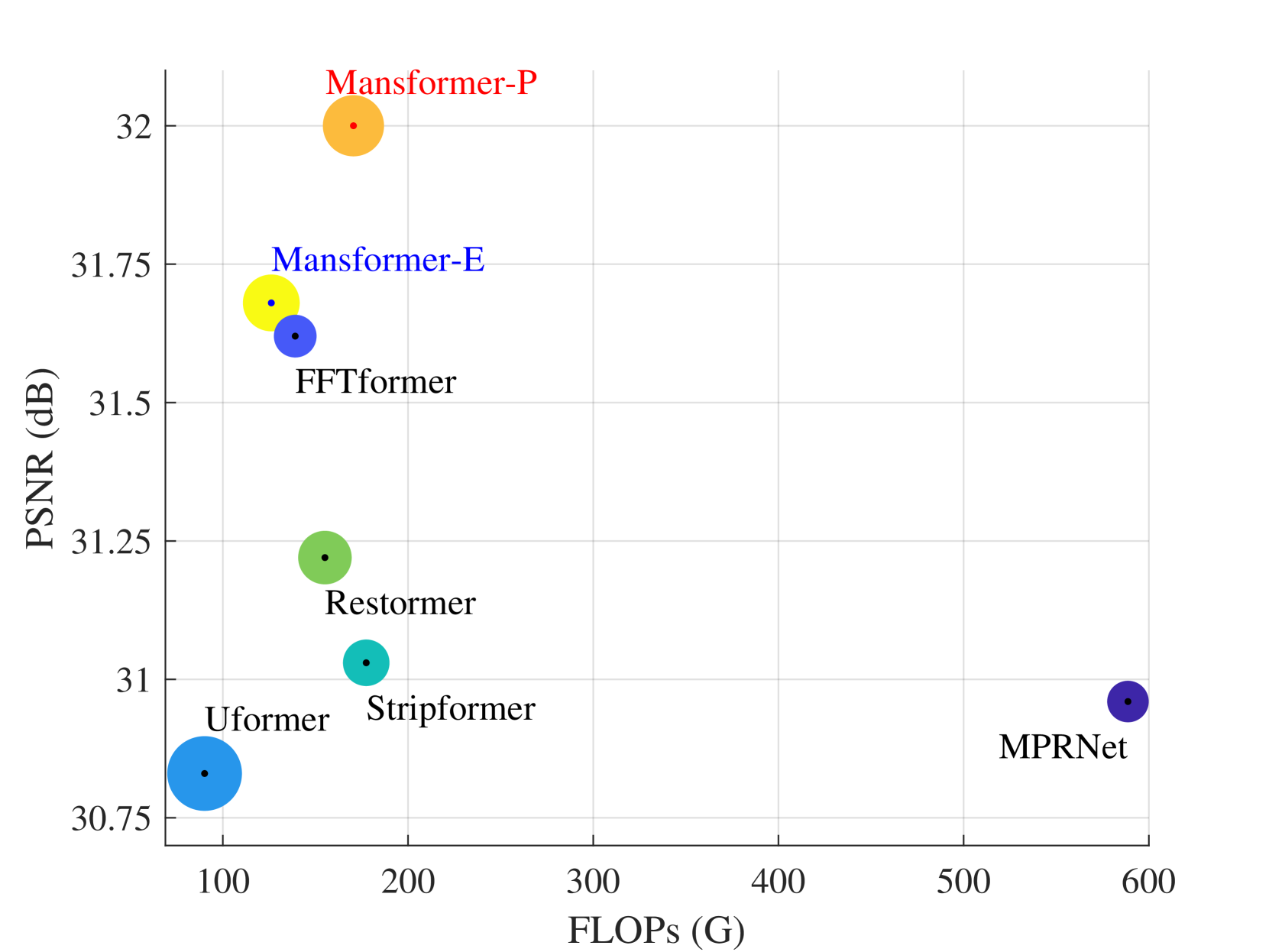
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
4/10/2024
🖼️
Reciprocal Attention Mixing Transformer for Lightweight Image Restoration
Haram Choi, Cheolwoong Na, Jihyeon Oh, Seungjae Lee, Jinseop Kim, Subeen Choe, Jeongmin Lee, Taehoon Kim, Jihoon Yang
0
0
Although many recent works have made advancements in the image restoration (IR) field, they often suffer from an excessive number of parameters. Another issue is that most Transformer-based IR methods focus only on either local or global features, leading to limited receptive fields or deficient parameter issues. To address these problems, we propose a lightweight IR network, Reciprocal Attention Mixing Transformer (RAMiT). It employs our proposed dimensional reciprocal attention mixing Transformer (D-RAMiT) blocks, which compute bi-dimensional (spatial and channel) self-attentions in parallel with different numbers of multi-heads. The bi-dimensional attentions help each other to complement their counterpart's drawbacks and are then mixed. Additionally, we introduce a hierarchical reciprocal attention mixing (H-RAMi) layer that compensates for pixel-level information losses and utilizes semantic information while maintaining an efficient hierarchical structure. Furthermore, we revisit and modify MobileNet V1 and V2 to attach efficient convolutions to our proposed components. The experimental results demonstrate that RAMiT achieves state-of-the-art performance on multiple lightweight IR tasks, including super-resolution, color denoising, grayscale denoising, low-light enhancement, and deraining. Codes are available at https://github.com/rami0205/RAMiT.
4/19/2024
Dynamic Pre-training: Towards Efficient and Scalable All-in-One Image Restoration
Akshay Dudhane, Omkar Thawakar, Syed Waqas Zamir, Salman Khan, Fahad Shahbaz Khan, Ming-Hsuan Yang
0
0
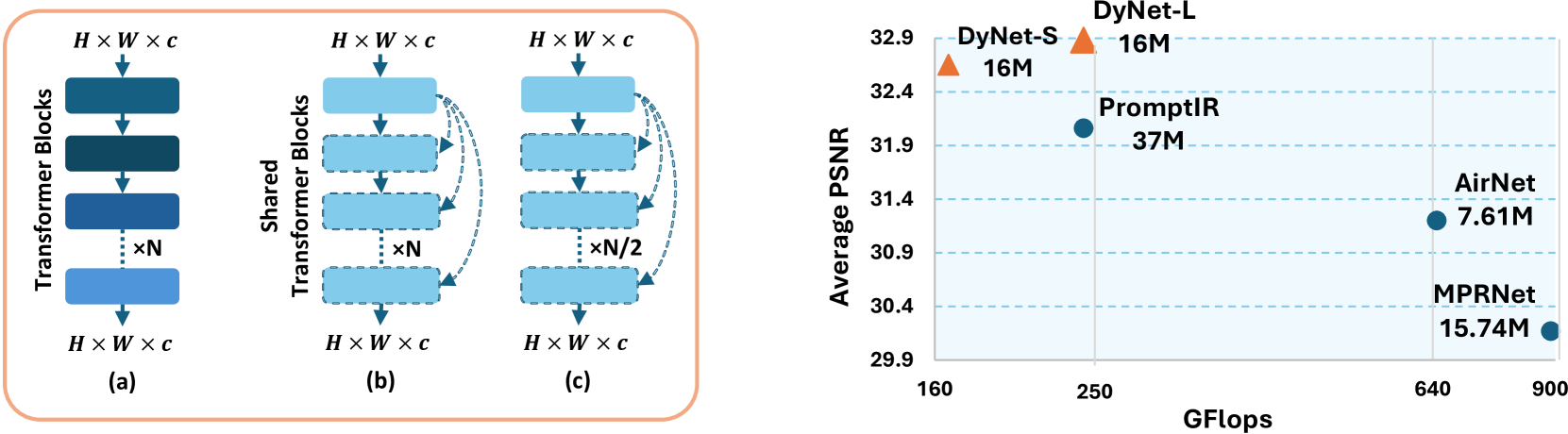
All-in-one image restoration tackles different types of degradations with a unified model instead of having task-specific, non-generic models for each degradation. The requirement to tackle multiple degradations using the same model can lead to high-complexity designs with fixed configuration that lack the adaptability to more efficient alternatives. We propose DyNet, a dynamic family of networks designed in an encoder-decoder style for all-in-one image restoration tasks. Our DyNet can seamlessly switch between its bulkier and lightweight variants, thereby offering flexibility for efficient model deployment with a single round of training. This seamless switching is enabled by our weights-sharing mechanism, forming the core of our architecture and facilitating the reuse of initialized module weights. Further, to establish robust weights initialization, we introduce a dynamic pre-training strategy that trains variants of the proposed DyNet concurrently, thereby achieving a 50% reduction in GPU hours. To tackle the unavailability of large-scale dataset required in pre-training, we curate a high-quality, high-resolution image dataset named Million-IRD having 2M image samples. We validate our DyNet for image denoising, deraining, and dehazing in all-in-one setting, achieving state-of-the-art results with 31.34% reduction in GFlops and a 56.75% reduction in parameters compared to baseline models. The source codes and trained models are available at https://github.com/akshaydudhane16/DyNet.
4/3/2024