Dreamguider: Improved Training free Diffusion-based Conditional Generation
2406.02549
0
0

Abstract
Diffusion models have emerged as a formidable tool for training-free conditional generation.However, a key hurdle in inference-time guidance techniques is the need for compute-heavy backpropagation through the diffusion network for estimating the guidance direction. Moreover, these techniques often require handcrafted parameter tuning on a case-by-case basis. Although some recent works have introduced minimal compute methods for linear inverse problems, a generic lightweight guidance solution to both linear and non-linear guidance problems is still missing. To this end, we propose Dreamguider, a method that enables inference-time guidance without compute-heavy backpropagation through the diffusion network. The key idea is to regulate the gradient flow through a time-varying factor. Moreover, we propose an empirical guidance scale that works for a wide variety of tasks, hence removing the need for handcrafted parameter tuning. We further introduce an effective lightweight augmentation strategy that significantly boosts the performance during inference-time guidance. We present experiments using Dreamguider on multiple tasks across multiple datasets and models to show the effectiveness of the proposed modules. To facilitate further research, we will make the code public after the review process.
Create account to get full access
Overview
- Introduces a new approach called "Dreamguider" for improved training-free diffusion-based conditional generation
- Builds on previous work in understanding and improving training-free loss-based diffusion, plug-and-play diffusion distillation, and using Fisher information for improved training-free conditional diffusion
- Proposes techniques to guide the diffusion model towards desired outputs without expensive finetuning
Plain English Explanation
Diffusion models are a type of AI system that can generate new images, text, or other content by learning from existing data. They work by gradually adding "noise" to an input, then trying to reverse that process to create something new. The Dreamguider approach aims to improve upon this by providing better ways to guide the diffusion model towards the desired outputs, without needing to go through the full expensive training process again.
The key idea is to leverage additional information, such as the user's preferences or domain knowledge, to steer the diffusion model in the right direction. This can be done in a flexible, "training-free" way, meaning the model doesn't have to be completely retrained from scratch.
The paper explores different techniques for this guidance, drawing on concepts like gradient guidance and Fisher information. The goal is to make diffusion models more controllable and useful for real-world applications, without the high computational cost of traditional fine-tuning approaches.
Technical Explanation
The paper introduces the "Dreamguider" framework, which builds on previous work in training-free diffusion models. The key innovations include:
-
Gradient Guidance: The authors propose a method to guide the diffusion model's gradients towards desired output characteristics, without expensive fine-tuning. This allows the model to be steered in the right direction while preserving its original capabilities.
-
Fisher Information Guidance: The paper also explores the use of Fisher information to better capture the model's uncertainty and guide it towards more desirable outputs. This helps address some of the limitations of previous training-free approaches.
-
Plug-and-Play Distillation: The authors demonstrate how their techniques can be combined with a plug-and-play distillation process, further improving the model's flexibility and performance.
Through extensive experiments, the paper shows that the Dreamguider framework can significantly improve the quality and controllability of diffusion-based conditional generation, without the need for full retraining. This has important implications for making these powerful AI models more accessible and useful in real-world applications.
Critical Analysis
The paper presents a well-designed and thorough exploration of the Dreamguider approach, with a range of experiments to validate its effectiveness. However, it's important to note that the techniques proposed are still relatively complex and may require some specialized knowledge to implement in practice.
Additionally, while the paper discusses the potential benefits of the Dreamguider framework, it does not delve into potential limitations or areas for further research. For example, it would be interesting to see how the approach performs on more diverse or challenging datasets, or how it compares to other recent advancements in training-free diffusion models.
Overall, the Dreamguider paper represents an important contribution to the field of diffusion-based conditional generation, offering a flexible and efficient way to guide these models towards desired outputs. However, as with any research, it's important for readers to critically evaluate the claims and consider the broader implications and potential areas for improvement.
Conclusion
The Dreamguider paper presents a novel approach for improving training-free diffusion-based conditional generation, offering a flexible and efficient way to guide these powerful AI models towards desired outputs. By leveraging techniques like gradient guidance and Fisher information, the authors demonstrate significant improvements in the quality and controllability of the generated content, without the need for expensive full retraining.
This work has important implications for making diffusion models more accessible and useful in real-world applications, where the ability to fine-tune or customize these models is crucial. As the field of AI continues to advance, research like Dreamguider will play a key role in unlocking the full potential of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Understanding and Improving Training-free Loss-based Diffusion Guidance
Yifei Shen, Xinyang Jiang, Yezhen Wang, Yifan Yang, Dongqi Han, Dongsheng Li
0
0
Adding additional control to pretrained diffusion models has become an increasingly popular research area, with extensive applications in computer vision, reinforcement learning, and AI for science. Recently, several studies have proposed training-free loss-based guidance by using off-the-shelf networks pretrained on clean images. This approach enables zero-shot conditional generation for universal control formats, which appears to offer a free lunch in diffusion guidance. In this paper, we aim to develop a deeper understanding of training-free guidance, as well as overcome its limitations. We offer a theoretical analysis that supports training-free guidance from the perspective of optimization, distinguishing it from classifier-based (or classifier-free) guidance. To elucidate their drawbacks, we theoretically demonstrate that training-free guidance is more susceptible to adversarial gradients and exhibits slower convergence rates compared to classifier guidance. We then introduce a collection of techniques designed to overcome the limitations, accompanied by theoretical rationale and empirical evidence. Our experiments in image and motion generation confirm the efficacy of these techniques.
5/30/2024

Plug-and-Play Diffusion Distillation
Yi-Ting Hsiao, Siavash Khodadadeh, Kevin Duarte, Wei-An Lin, Hui Qu, Mingi Kwon, Ratheesh Kalarot
0
0
Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this plug-and-play functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
6/17/2024
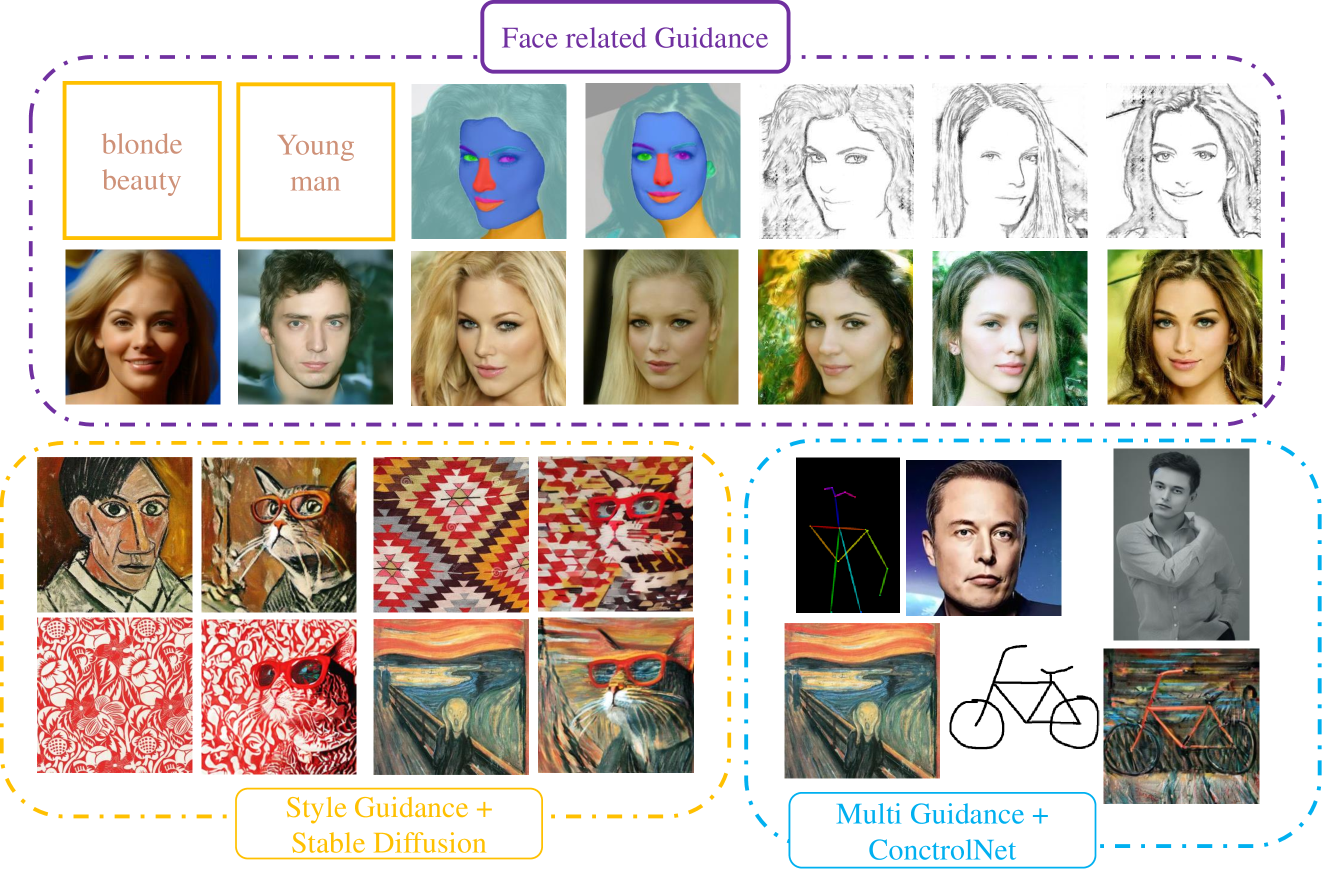
Fisher Information Improved Training-Free Conditional Diffusion Model
Kaiyu Song, Hanjiang Lai
0
0
Recently, the diffusion model with the training-free methods has succeeded in conditional image generation tasks. However, there is an efficiency problem because it requires calculating the gradient with high computational cost, and previous methods make strong assumptions to solve it, sacrificing generalization. In this work, we propose the Fisher information guided diffusion model (FIGD). Concretely, we introduce the Fisher information to estimate the gradient without making any additional assumptions to reduce computation cost. Meanwhile, we demonstrate that the Fisher information ensures the generalization of FIGD and provides new insights for training-free methods based on the information theory. The experimental results demonstrate that FIGD could achieve different conditional generations more quickly while maintaining high quality.
4/30/2024
Guiding a Diffusion Model with a Bad Version of Itself
Tero Karras, Miika Aittala, Tuomas Kynkaanniemi, Jaakko Lehtinen, Timo Aila, Samuli Laine
0
0
The primary axes of interest in image-generating diffusion models are image quality, the amount of variation in the results, and how well the results align with a given condition, e.g., a class label or a text prompt. The popular classifier-free guidance approach uses an unconditional model to guide a conditional model, leading to simultaneously better prompt alignment and higher-quality images at the cost of reduced variation. These effects seem inherently entangled, and thus hard to control. We make the surprising observation that it is possible to obtain disentangled control over image quality without compromising the amount of variation by guiding generation using a smaller, less-trained version of the model itself rather than an unconditional model. This leads to significant improvements in ImageNet generation, setting record FIDs of 1.01 for 64x64 and 1.25 for 512x512, using publicly available networks. Furthermore, the method is also applicable to unconditional diffusion models, drastically improving their quality.
6/5/2024