DRPC: Distributed Reinforcement Learning Approach for Scalable Resource Provisioning in Container-based Clusters

0

Sign in to get full access
Overview
- Presents a distributed reinforcement learning approach called DRPC for scalable resource provisioning in container-based clusters
- Aims to optimize resource allocation and utilization in Kubernetes-based microservice environments
- Leverages reinforcement learning techniques to dynamically adjust resource allocations based on real-time application demands
Plain English Explanation
This paper introduces a new system called DRPC that uses reinforcement learning to help manage resources in container-based cloud computing environments, like those powered by Kubernetes.
The key challenge the researchers are trying to solve is how to efficiently allocate computing resources (like CPU, memory, storage) to different microservices running in the cluster. This is important because the demands on these resources can change rapidly as user traffic and application needs fluctuate. Overprovisioning resources is wasteful, but underprovisioning can lead to performance issues.
DRPC attempts to address this by using a distributed reinforcement learning approach. It monitors the real-time resource usage of each microservice and uses that data to continuously learn and adjust the resource allocations. The goal is to automatically right-size the resources for each service based on its current needs, rather than relying on static configurations.
This dynamic, data-driven approach aims to improve resource utilization and application performance compared to traditional manual or rule-based resource management strategies. By jointly optimizing the caching, communication, and computing resources, DRPC seeks to create a more efficient and scalable system for running microservices in the cloud.
Technical Explanation
The DRPC system consists of several key components:
- Resource Monitor: Collects real-time metrics on CPU, memory, and other resource utilization for each microservice container.
- Reinforcement Learning Agent: Uses the monitoring data to learn an optimal resource allocation policy through trial-and-error interactions with the cluster.
- Resource Provisioner: Applies the learned policy to dynamically adjust resource allocations for each microservice as demands change.
The reinforcement learning agent uses a distributed multi-agent architecture, where each agent is responsible for a subset of the microservices. This allows the system to scale to large, complex Kubernetes environments.
The agents use a novel reward function that considers both the performance of individual microservices and the overall cluster-level resource utilization. This encourages the agents to find a balance between meeting application needs and efficiently using the available resources.
Through extensive simulations and real-world experiments, the researchers demonstrate that DRPC can outperform traditional rule-based autoscaling approaches in terms of application performance, resource efficiency, and scalability.
Critical Analysis
The DRPC system presents a promising approach to the challenge of dynamic resource management in container-based microservice environments. By leveraging reinforcement learning, the system can adapt to changing conditions in a more flexible and data-driven way compared to static rules or thresholds.
However, the paper does not address certain practical concerns that may arise in real-world deployments. For example, the impact of noisy or incomplete monitoring data on the learning process, the potential for instability or oscillation in the resource allocations, and the computational overhead of the distributed reinforcement learning algorithms.
Additionally, the evaluation is largely focused on synthetic workloads and does not consider the nuances of real-world microservice architectures, such as the effects of inter-service dependencies, network latency, and database interactions on overall application performance.
Further research is needed to better understand the robustness and generalizability of the DRPC approach, as well as its integration with existing Kubernetes autoscaling mechanisms and other cloud resource management tools.
Conclusion
The DRPC system presents a novel and promising approach to dynamic resource provisioning for container-based microservice applications. By leveraging distributed reinforcement learning, the system can adaptively adjust resource allocations to meet changing application demands, with the goal of improving overall performance and resource efficiency.
While the technical details and experimental results are encouraging, the paper also highlights the need for further research to address practical deployment challenges and better understand the system's behavior in real-world scenarios. As the use of microservices and container orchestration platforms like Kubernetes continues to grow, solutions like DRPC will become increasingly important for managing the complexity and dynamism of cloud-native applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DRPC: Distributed Reinforcement Learning Approach for Scalable Resource Provisioning in Container-based Clusters
Haoyu Bai, Minxian Xu, Kejiang Ye, Rajkumar Buyya, Chengzhong Xu
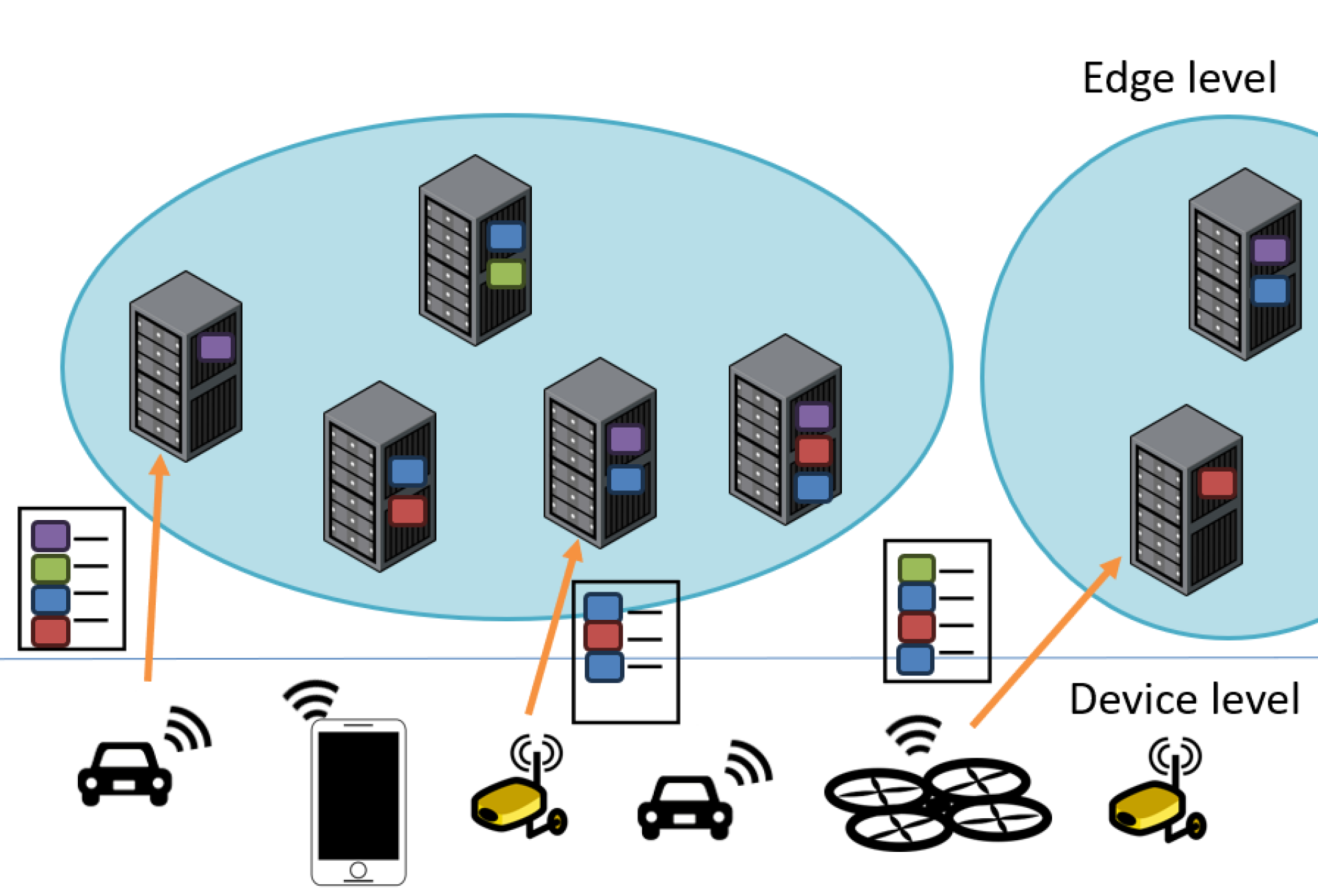
Microservices have transformed monolithic applications into lightweight, self-contained, and isolated application components, establishing themselves as a dominant paradigm for application development and deployment in public clouds such as Google and Alibaba. Autoscaling emerges as an efficient strategy for managing resources allocated to microservices' replicas. However, the dynamic and intricate dependencies within microservice chains present challenges to the effective management of scaled microservices. Additionally, the centralized autoscaling approach can encounter scalability issues, especially in the management of large-scale microservice-based clusters. To address these challenges and enhance scalability, we propose an innovative distributed resource provisioning approach for microservices based on the Twin Delayed Deep Deterministic Policy Gradient algorithm. This approach enables effective autoscaling decisions and decentralizes responsibilities from a central node to distributed nodes. Comparative results with state-of-the-art approaches, obtained from a realistic testbed and traces, indicate that our approach reduces the average response time by 15% and the number of failed requests by 24%, validating improved scalability as the number of requests increases.
Read more7/16/2024
0
Energy-aware Distributed Microservice Request Placement at the Edge
Klervie Tocz'e, Simin Nadjm-Tehrani
Microservice is a way of splitting the logic of an application into small blocks that can be run on different computing units and used by other applications. It has been successful for cloud applications and is now increasingly used for edge applications. This new architecture brings many benefits but it makes deciding where a given service request should be executed (i.e. its placement) more complex as every small block needed for the request has to be placed. In this paper, we investigate decentralized request placement (DRP) for services using the microservice architecture. We consider the DRP problem as an instance of a traveling purchaser problem and propose an integer linear programming formulation. This formulation aims at minimizing energy consumption while respecting latency requirements. We consider two different energy consumption metrics, namely overall or marginal energy, to study how optimizing towards these impacts the request placement decision. Our simulations show that the request placement decision can indeed be influenced by the energy metric chosen, leading to different energy reduction strategies.
Read more8/27/2024

0
Reinforcement Learning-Based Adaptive Load Balancing for Dynamic Cloud Environments
Kavish Chawla
Efficient load balancing is crucial in cloud computing environments to ensure optimal resource utilization, minimize response times, and prevent server overload. Traditional load balancing algorithms, such as round-robin or least connections, are often static and unable to adapt to the dynamic and fluctuating nature of cloud workloads. In this paper, we propose a novel adaptive load balancing framework using Reinforcement Learning (RL) to address these challenges. The RL-based approach continuously learns and improves the distribution of tasks by observing real-time system performance and making decisions based on traffic patterns and resource availability. Our framework is designed to dynamically reallocate tasks to minimize latency and ensure balanced resource usage across servers. Experimental results show that the proposed RL-based load balancer outperforms traditional algorithms in terms of response time, resource utilization, and adaptability to changing workloads. These findings highlight the potential of AI-driven solutions for enhancing the efficiency and scalability of cloud infrastructures.
Read more9/10/2024

0
On-Demand Model and Client Deployment in Federated Learning with Deep Reinforcement Learning
Mario Chahoud, Hani Sami, Azzam Mourad, Hadi Otrok, Jamal Bentahar, Mohsen Guizani
In Federated Learning (FL), the limited accessibility of data from diverse locations and user types poses a significant challenge due to restricted user participation. Expanding client access and diversifying data enhance models by incorporating diverse perspectives, thereby enhancing adaptability. However, challenges arise in dynamic and mobile environments where certain devices may become inaccessible as FL clients, impacting data availability and client selection methods. To address this, we propose an On-Demand solution, deploying new clients using Docker Containers on-the-fly. Our On-Demand solution, employing Deep Reinforcement Learning (DRL), targets client availability and selection, while considering data shifts, and container deployment complexities. It employs an autonomous end-to-end solution for handling model deployment and client selection. The DRL strategy uses a Markov Decision Process (MDP) framework, with a Master Learner and a Joiner Learner. The designed cost functions represent the complexity of the dynamic client deployment and selection. Simulated tests show that our architecture can easily adjust to changes in the environment and respond to On-Demand requests. This underscores its ability to improve client availability, capability, accuracy, and learning efficiency, surpassing heuristic and tabular reinforcement learning solutions.
Read more5/14/2024