DSDRNet: Disentangling Representation and Reconstruct Network for Domain Generalization

0
Sign in to get full access
Overview
- The paper proposes a new model called DSDRNet (Disentangling Representation and Reconstruct Network) for domain generalization, which aims to improve the performance of machine learning models when applied to data from unseen domains.
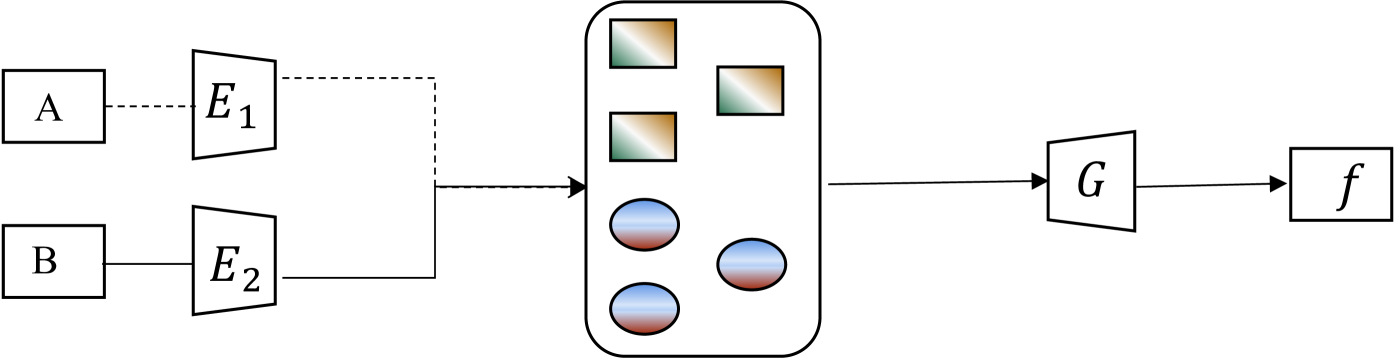
- The key idea is to disentangle the representation of an input into domain-specific and domain-agnostic components, and then use this disentangled representation to reconstruct the original input.
- This reconstruction task, combined with other objectives, helps the model learn a more robust and transferable representation that can generalize better to new domains.
Plain English Explanation
The paper introduces a new technique called DSDRNet that can help machine learning models perform well on data from different domains, even if they haven't seen that type of data before. The main idea is to split up the information in the input data into two parts: one part that is specific to the domain (like the background or lighting), and another part that is more general and applies across domains.
The model is trained to take the input data and reconstruct it from this split-up representation. This reconstruction task, along with some other training objectives, helps the model learn a representation that is robust and can work well on new, unseen domains. The key is that the model learns to focus on the general, domain-agnostic features rather than getting overly specialized to the training data.
This is an important problem because real-world data often comes from many different sources or "domains", and machine learning models need to be able to handle that variation. DSDRNet builds on related work in this area, like ,[object Object] and [object Object]. The authors show that their approach can outperform previous methods on standard domain generalization benchmarks.
Technical Explanation
The core of the DSDRNet model is a disentanglement module that splits the input representation into a domain-specific component and a domain-agnostic component. This disentangled representation is then used to reconstruct the original input through a reconstruction network.
The authors propose several training objectives to encourage the desired disentanglement and learning of a robust representation:
- Domain-Specific Reconstruction Loss: The model is trained to accurately reconstruct the input from the disentangled representation, encouraging the domain-specific component to capture domain-relevant information.
- Domain-Agnostic Reconstruction Loss: The model is also trained to reconstruct the input from just the domain-agnostic component, forcing it to learn a representation that can generalize across domains.
- Adversarial Domain Confusion: An adversarial domain classifier is used to encourage the domain-agnostic component to be indistinguishable across domains, promoting cross-domain generalization.
- Orthogonality Regularization: The domain-specific and domain-agnostic components are regularized to be orthogonal to each other, ensuring the disentanglement.
The authors evaluate DSDRNet on standard domain generalization benchmarks like PACS, DomainNet, and Office-Home, and show that it outperforms previous state-of-the-art methods. They also provide ablation studies to analyze the contribution of each training objective.
Critical Analysis
The authors acknowledge that while DSDRNet demonstrates strong performance on the evaluated benchmarks, there are still limitations and open challenges in the field of domain generalization. For example, the disentanglement may not always be perfect, and the model may still rely on some domain-specific features for its predictions.
Additionally, the paper does not explore the interpretability of the learned domain-specific and domain-agnostic representations, which could be an interesting area for further research. Understanding the nature of the disentanglement and its implications could lead to better design of domain generalization techniques.
Frequency Decomposition Driven Unsupervised Domain Adaptation for Remote Sensing and IIDM: Inter-Intra Domain Mixing for Semi-Supervised Domain Adaptation are other related works that explore different approaches to domain adaptation and generalization, and could provide additional insights for improving DSDRNet.
Conclusion
The DSDRNet model proposed in this paper represents an important step forward in the field of domain generalization. By disentangling the representation into domain-specific and domain-agnostic components, and using this disentanglement to reconstruct the input, the model is able to learn a more robust and transferable representation that can generalize well to new, unseen domains.
The strong empirical results on standard benchmarks demonstrate the effectiveness of this approach, and the authors' analysis of the various training objectives provides valuable insights into the key factors driving the model's performance. While there are still open challenges, DSDRNet contributes a promising new technique that could have significant impact on real-world applications where domain shift is a common problem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DSDRNet: Disentangling Representation and Reconstruct Network for Domain Generalization
Juncheng Yang, Zuchao Li, Shuai Xie, Wei Yu, Shijun Li
Domain generalization faces challenges due to the distribution shift between training and testing sets, and the presence of unseen target domains. Common solutions include domain alignment, meta-learning, data augmentation, or ensemble learning, all of which rely on domain labels or domain adversarial techniques. In this paper, we propose a Dual-Stream Separation and Reconstruction Network, dubbed DSDRNet. It is a disentanglement-reconstruction approach that integrates features of both inter-instance and intra-instance through dual-stream fusion. The method introduces novel supervised signals by combining inter-instance semantic distance and intra-instance similarity. Incorporating Adaptive Instance Normalization (AdaIN) into a two-stage cyclic reconstruction process enhances self-disentangled reconstruction signals to facilitate model convergence. Extensive experiments on four benchmark datasets demonstrate that DSDRNet outperforms other popular methods in terms of domain generalization capabilities.
Read more4/23/2024

0
ConDiSR: Contrastive Disentanglement and Style Regularization for Single Domain Generalization
Aleksandr Matsun, Numan Saeed, Fadillah Adamsyah Maani, Mohammad Yaqub
Medical data often exhibits distribution shifts, which cause test-time performance degradation for deep learning models trained using standard supervised learning pipelines. This challenge is addressed in the field of Domain Generalization (DG) with the sub-field of Single Domain Generalization (SDG) being specifically interesting due to the privacy- or logistics-related issues often associated with medical data. Existing disentanglement-based SDG methods heavily rely on structural information embedded in segmentation masks, however classification labels do not provide such dense information. This work introduces a novel SDG method aimed at medical image classification that leverages channel-wise contrastive disentanglement. It is further enhanced with reconstruction-based style regularization to ensure extraction of distinct style and structure feature representations. We evaluate our method on the complex task of multicenter histopathology image classification, comparing it against state-of-the-art (SOTA) SDG baselines. Results demonstrate that our method surpasses the SOTA by a margin of 1% in average accuracy while also showing more stable performance. This study highlights the importance and challenges of exploring SDG frameworks in the context of the classification task. The code is publicly available at https://github.com/BioMedIA-MBZUAI/ConDiSR
Read more7/16/2024

0
Generalizing to Unseen Domains in Diabetic Retinopathy with Disentangled Representations
Peng Xia, Ming Hu, Feilong Tang, Wenxue Li, Wenhao Zheng, Lie Ju, Peibo Duan, Huaxiu Yao, Zongyuan Ge
Diabetic Retinopathy (DR), induced by diabetes, poses a significant risk of visual impairment. Accurate and effective grading of DR aids in the treatment of this condition. Yet existing models experience notable performance degradation on unseen domains due to domain shifts. Previous methods address this issue by simulating domain style through simple visual transformation and mitigating domain noise via learning robust representations. However, domain shifts encompass more than image styles. They overlook biases caused by implicit factors such as ethnicity, age, and diagnostic criteria. In our work, we propose a novel framework where representations of paired data from different domains are decoupled into semantic features and domain noise. The resulting augmented representation comprises original retinal semantics and domain noise from other domains, aiming to generate enhanced representations aligned with real-world clinical needs, incorporating rich information from diverse domains. Subsequently, to improve the robustness of the decoupled representations, class and domain prototypes are employed to interpolate the disentangled representations while data-aware weights are designed to focus on rare classes and domains. Finally, we devise a robust pixel-level semantic alignment loss to align retinal semantics decoupled from features, maintaining a balance between intra-class diversity and dense class features. Experimental results on multiple benchmarks demonstrate the effectiveness of our method on unseen domains. The code implementations are accessible on https://github.com/richard-peng-xia/DECO.
Read more6/11/2024

0
Domain Generalized Recaptured Screen Image Identification Using SWIN Transformer
Preeti Mehta, Aman Sagar, Suchi Kumari
An increasing number of classification approaches have been developed to address the issue of image rebroadcast and recapturing, a standard attack strategy in insurance frauds, face spoofing, and video piracy. However, most of them neglected scale variations and domain generalization scenarios, performing poorly in instances involving domain shifts, typically made worse by inter-domain and cross-domain scale variances. To overcome these issues, we propose a cascaded data augmentation and SWIN transformer domain generalization framework (DAST-DG) in the current research work Initially, we examine the disparity in dataset representation. A feature generator is trained to make authentic images from various domains indistinguishable. This process is then applied to recaptured images, creating a dual adversarial learning setup. Extensive experiments demonstrate that our approach is practical and surpasses state-of-the-art methods across different databases. Our model achieves an accuracy of approximately 82% with a precision of 95% on high-variance datasets.
Read more7/26/2024