DTR: A Unified Deep Tensor Representation Framework for Multimedia Data Recovery

0

Sign in to get full access
Overview
- Proposes a unified deep tensor representation (DTR) framework for recovering multimedia data
- Includes a deep latent generative module and a deep transform module to learn a compact and interpretable tensor representation
- Demonstrates the effectiveness of DTR on various multimedia data recovery tasks
Plain English Explanation
The paper introduces a new framework called "Deep Tensor Representation" (DTR) that aims to improve how computers process and recover multimedia data, such as images, videos, and audio.
The key idea behind DTR is to learn a compact and interpretable representation of the data in the form of a tensor (a multi-dimensional array). This is achieved through two main components: a deep latent generative module that learns a low-dimensional latent representation of the data, and a deep transform module that maps this latent representation to the final tensor representation.
By learning this tensor representation, the DTR framework can then be used to recover or reconstruct the original multimedia data, even in cases where the data is incomplete or corrupted. This could be useful for applications like image restoration, video inpainting, or audio enhancement.
The paper demonstrates the effectiveness of DTR on several multimedia data recovery tasks and shows that it outperforms other state-of-the-art methods. The tensor representation learned by DTR is also claimed to be more compact and interpretable compared to traditional approaches.
Technical Explanation
The DTR framework consists of two key modules: the deep latent generative module and the deep transform module.
The deep latent generative module takes the input multimedia data (e.g., an image) and learns a low-dimensional latent representation of it. This is done using a deep neural network architecture that maps the input data to a latent vector. The authors draw inspiration from techniques like variational autoencoders to ensure the latent representation is smooth and structured.
The deep transform module then takes this latent representation and maps it to the final tensor representation. This is accomplished using another deep neural network that learns a set of transformations to apply to the latent vector, resulting in a multi-dimensional tensor that captures the structure and patterns in the original data.
To train the DTR framework, the authors use a combination of reconstruction loss (to ensure the tensor representation can be used to accurately recover the input data) and regularization terms (to encourage the latent representation to be compact and interpretable).
The authors demonstrate the effectiveness of DTR on a variety of multimedia data recovery tasks, including image inpainting, video frame interpolation, and audio enhancement. They show that DTR outperforms other state-of-the-art methods on these tasks, while also producing a more compact and interpretable tensor representation.
Critical Analysis
The DTR framework presented in the paper appears to be a promising approach for learning compact and interpretable representations of multimedia data. The authors have carefully designed the deep latent generative and deep transform modules to capture the underlying structure of the data, and the results on various recovery tasks are impressive.
However, the paper does not address some potential limitations or areas for further research. For example, the authors do not discuss how the performance of DTR scales with the size and complexity of the input data, or how robust the framework is to different types of noise or corruption in the data.
Additionally, while the interpretability of the learned tensor representation is highlighted as a key advantage, the paper does not provide a detailed analysis of what insights this representation can offer or how it compares to other interpretable representations, such as those learned by dictionary-based decomposition methods.
Overall, the DTR framework is a valuable contribution to the field of multimedia data processing and recovery. However, further research and analysis would be needed to fully understand its strengths, weaknesses, and potential applications in real-world scenarios.
Conclusion
The DTR framework proposed in this paper represents a significant advancement in the field of multimedia data recovery. By learning a compact and interpretable tensor representation of the data, the framework is able to outperform other state-of-the-art methods on a variety of tasks, such as image inpainting, video frame interpolation, and audio enhancement.
The key innovations of DTR are the deep latent generative module and the deep transform module, which work together to capture the underlying structure and patterns in the input data. This tensor representation can then be used to recover the original data, even in the presence of noise or missing information.
While the paper does not address all potential limitations of the framework, the results presented are highly promising and suggest that DTR could have a significant impact on a wide range of multimedia applications. As the field of deep learning continues to advance, frameworks like DTR will play an increasingly important role in helping computers understand and process the complex, high-dimensional data that is ubiquitous in our digital world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DTR: A Unified Deep Tensor Representation Framework for Multimedia Data Recovery
Ting-Wei Zhou, Xi-Le Zhao, Jian-Li Wang, Yi-Si Luo, Min Wang, Xiao-Xuan Bai, Hong Yan
Recently, the transform-based tensor representation has attracted increasing attention in multimedia data (e.g., images and videos) recovery problems, which consists of two indispensable components, i.e., transform and characterization. Previously, the development of transform-based tensor representation mainly focuses on the transform aspect. Although several attempts consider using shallow matrix factorization (e.g., singular value decomposition and negative matrix factorization) to characterize the frontal slices of transformed tensor (termed as latent tensor), the faithful characterization aspect is underexplored. To address this issue, we propose a unified Deep Tensor Representation (termed as DTR) framework by synergistically combining the deep latent generative module and the deep transform module. Especially, the deep latent generative module can faithfully generate the latent tensor as compared with shallow matrix factorization. The new DTR framework not only allows us to better understand the classic shallow representations, but also leads us to explore new representation. To examine the representation ability of the proposed DTR, we consider the representative multi-dimensional data recovery task and suggest an unsupervised DTR-based multi-dimensional data recovery model. Extensive experiments demonstrate that DTR achieves superior performance compared to state-of-the-art methods in both quantitative and qualitative aspects, especially for fine details recovery.
Read more7/9/2024

0
Discrete Dictionary-based Decomposition Layer for Structured Representation Learning
Taewon Park, Hyun-Chul Kim, Minho Lee
Neuro-symbolic neural networks have been extensively studied to integrate symbolic operations with neural networks, thereby improving systematic generalization. Specifically, Tensor Product Representation (TPR) framework enables neural networks to perform differentiable symbolic operations by encoding the symbolic structure of data within vector spaces. However, TPR-based neural networks often struggle to decompose unseen data into structured TPR representations, undermining their symbolic operations. To address this decomposition problem, we propose a Discrete Dictionary-based Decomposition (D3) layer designed to enhance the decomposition capabilities of TPR-based models. D3 employs discrete, learnable key-value dictionaries trained to capture symbolic features essential for decomposition operations. It leverages the prior knowledge acquired during training to generate structured TPR representations by mapping input data to pre-learned symbolic features within these dictionaries. D3 is a straightforward drop-in layer that can be seamlessly integrated into any TPR-based model without modifications. Our experimental results demonstrate that D3 significantly improves the systematic generalization of various TPR-based models while requiring fewer additional parameters. Notably, D3 outperforms baseline models on the synthetic task that demands the systematic decomposition of unseen combinatorial data.
Read more6/12/2024

0
Audio-text Retrieval with Transformer-based Hierarchical Alignment and Disentangled Cross-modal Representation
Yifei Xin, Zhihong Zhu, Xuxin Cheng, Xusheng Yang, Yuexian Zou
Most existing audio-text retrieval (ATR) approaches typically rely on a single-level interaction to associate audio and text, limiting their ability to align different modalities and leading to suboptimal matches. In this work, we present a novel ATR framework that leverages two-stream Transformers in conjunction with a Hierarchical Alignment (THA) module to identify multi-level correspondences of different Transformer blocks between audio and text. Moreover, current ATR methods mainly focus on learning a global-level representation, missing out on intricate details to capture audio occurrences that correspond to textual semantics. To bridge this gap, we introduce a Disentangled Cross-modal Representation (DCR) approach that disentangles high-dimensional features into compact latent factors to grasp fine-grained audio-text semantic correlations. Additionally, we develop a confidence-aware (CA) module to estimate the confidence of each latent factor pair and adaptively aggregate cross-modal latent factors to achieve local semantic alignment. Experiments show that our THA effectively boosts ATR performance, with the DCR approach further contributing to consistent performance gains.
Read more9/17/2024
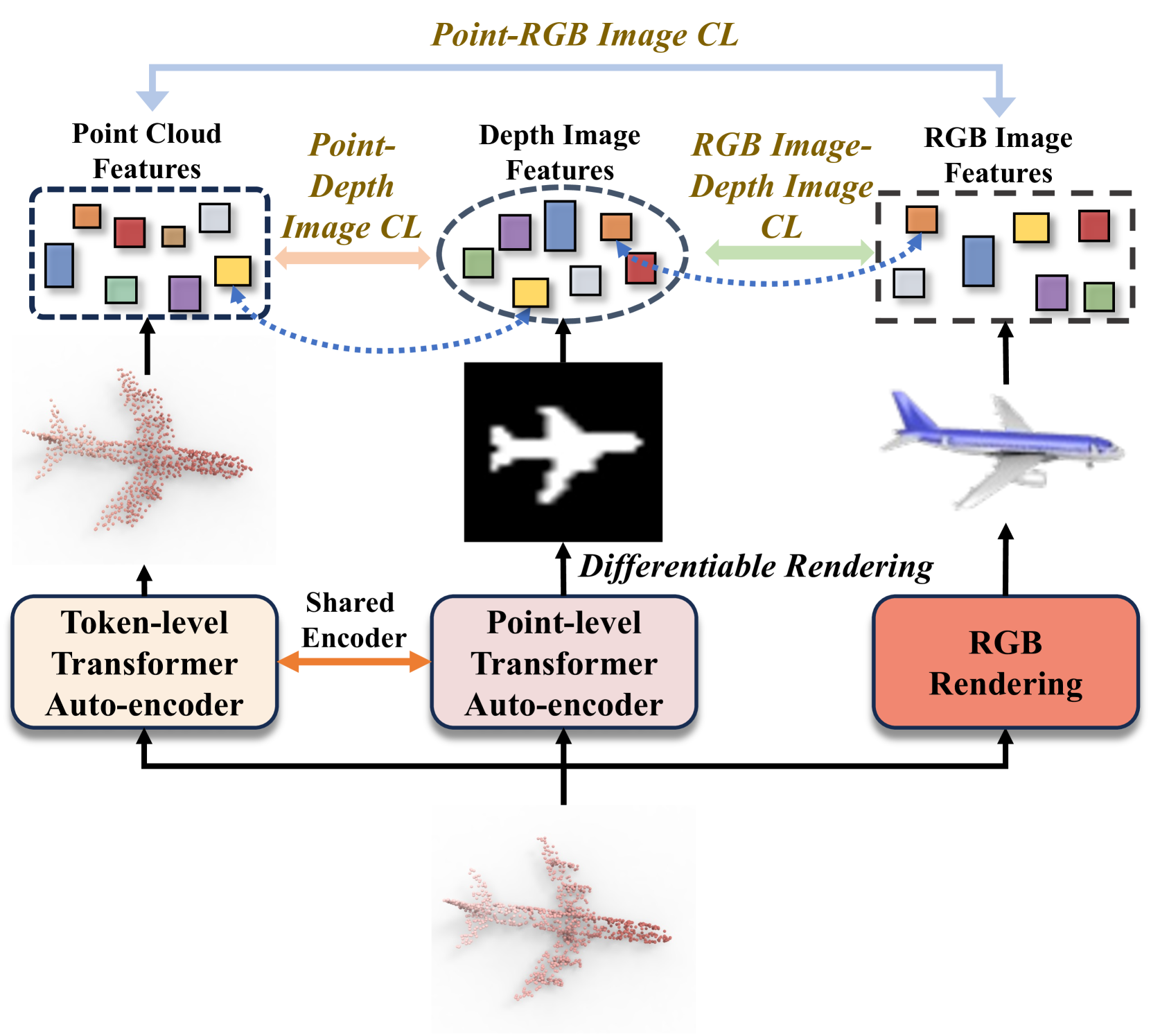
0
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
Read more4/23/2024