Du-IN: Discrete units-guided mask modeling for decoding speech from Intracranial Neural signals
2405.11459
0
0
Abstract
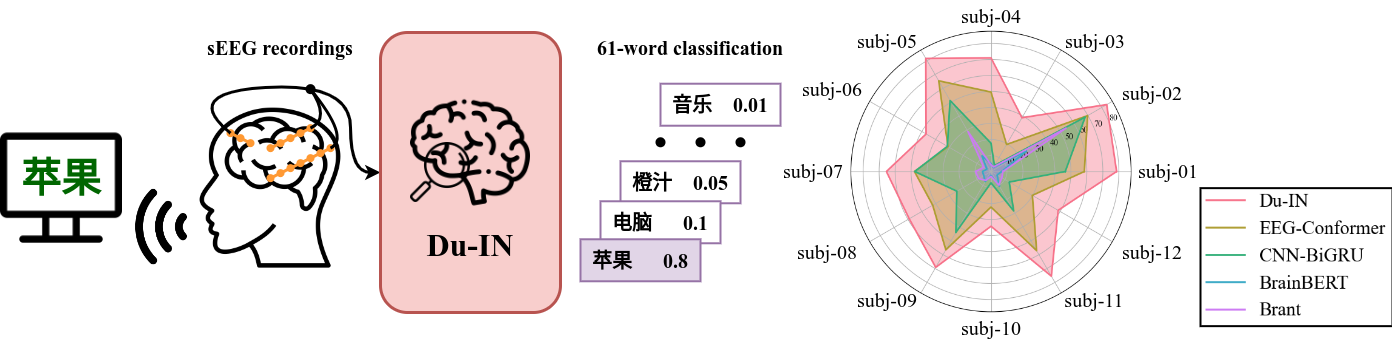
Invasive brain-computer interfaces have garnered significant attention due to their high performance. The current intracranial stereoElectroEncephaloGraphy (sEEG) foundation models typically build univariate representations based on a single channel. Some of them further use Transformer to model the relationship among channels. However, due to the locality and specificity of brain computation, their performance on more difficult tasks, e.g., speech decoding, which demands intricate processing in specific brain regions, is yet to be fully investigated. We hypothesize that building multi-variate representations within certain brain regions can better capture the specific neural processing. To explore this hypothesis, we collect a well-annotated Chinese word-reading sEEG dataset, targeting language-related brain networks, over 12 subjects. Leveraging this benchmark dataset, we developed the Du-IN model that can extract contextual embeddings from specific brain regions through discrete codebook-guided mask modeling. Our model achieves SOTA performance on the downstream 61-word classification task, surpassing all baseline models. Model comparison and ablation analysis reveal that our design choices, including (i) multi-variate representation by fusing channels in vSMC and STG regions and (ii) self-supervision by discrete codebook-guided mask modeling, significantly contribute to these performances. Collectively, our approach, inspired by neuroscience findings, capitalizing on multi-variate neural representation from specific brain regions, is suitable for invasive brain modeling. It marks a promising neuro-inspired AI approach in BCI.
Create account to get full access
Overview
- This paper introduces a novel method called "Du-IN" for decoding speech from intracranial neural signals.
- The method uses a discrete units-guided mask modeling approach to improve speech decoding performance.
- The authors demonstrate the effectiveness of their approach on a real-world dataset of intracranial neural recordings during speech production.
Plain English Explanation
The paper describes a new technique for translating brain signals into speech. The researchers used a machine learning approach that focuses on specific "units" or patterns in the brain data, rather than trying to decode the entire brain signal at once.
The key idea is to use these discrete units as a guide to help the model figure out which parts of the brain signal are most relevant for speech. This "mask modeling" technique allows the model to focus on the important information and ignore the irrelevant noise in the brain data.
The authors show that this approach outperforms previous methods for decoding speech from brain signals, particularly on a real-world dataset of people speaking out loud while their brain activity was recorded. By honing in on the most informative brain patterns, the Du-IN method is able to more accurately translate brain signals into the corresponding speech.
This is an important advance because being able to decode speech directly from the brain could have many applications, such as helping people with speech disabilities communicate more effectively. The authors' novel approach represents a step forward in this exciting area of brain-computer interface technology.
Technical Explanation
The paper introduces a novel method called "Du-IN" (Discrete units-guided mask modeling for decoding speech from Intracranial Neural signals) for decoding speech from intracranial neural recordings. The key innovation is the use of a discrete units-guided mask modeling approach.
Specifically, the authors first identify discrete neural units or patterns in the intracranial recordings that are correlated with different speech sounds. They then use these discrete units as a "mask" to guide the speech decoding model, focusing its attention on the most informative parts of the brain signal.
This mask modeling technique allows the model to selectively attend to the relevant neural patterns while ignoring irrelevant noise, leading to improved speech decoding performance compared to previous approaches. The authors evaluate their method on a real-world dataset of intracranial neural recordings collected during natural speech production.
The results demonstrate the effectiveness of the Du-IN approach, which outperforms baseline speech decoding models. The authors attribute this performance boost to the ability of the discrete units-guided mask modeling to capture the most salient neural representations for speech.
Critical Analysis
The Du-IN method represents an interesting and promising approach to decoding speech from intracranial neural signals. By focusing the model on the most informative neural patterns, the authors are able to achieve state-of-the-art performance on a real-world dataset.
However, the paper does not extensively explore the limitations of the approach or areas for future research. For example, it would be valuable to understand how the method might scale to larger or more diverse speech datasets, or how it compares to alternative neural decoding techniques like those used in Visual Decoding and Reconstruction via EEG Embeddings, Neuro-Vision to Language, or the SI-SD Sleep Interpreter.
Additionally, while the authors demonstrate the effectiveness of their approach, they do not delve into the interpretability or explainability of the discrete neural units that guide the mask modeling. Understanding the underlying neural mechanisms involved in speech production could lead to further insights and advancements in brain-computer interface technology, as seen in MindBridge and EEG2Text.
Overall, the Du-IN method represents a valuable contribution to the field of speech decoding from intracranial neural signals. With further research and refinement, this approach could have significant implications for assistive technologies and our understanding of the neural basis of speech production.
Conclusion
The Du-IN method introduced in this paper represents an innovative approach to decoding speech from intracranial neural signals. By leveraging discrete neural units as a guide for mask modeling, the authors are able to improve upon previous speech decoding techniques, demonstrating state-of-the-art performance on a real-world dataset.
This work has important implications for the development of brain-computer interface technologies that could assist individuals with speech disabilities or other communication challenges. Additionally, the insights gained from the discrete neural units identified by the model could lead to a deeper understanding of the neural mechanisms underlying speech production.
While the paper does not extensively explore the limitations or areas for future research, the Du-IN method represents a promising step forward in the field of neural speech decoding. With further refinement and exploration, this approach could have significant impacts on the lives of those with speech impairments and our broader understanding of the relationship between brain activity and speech.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Quanying Liu
0
0
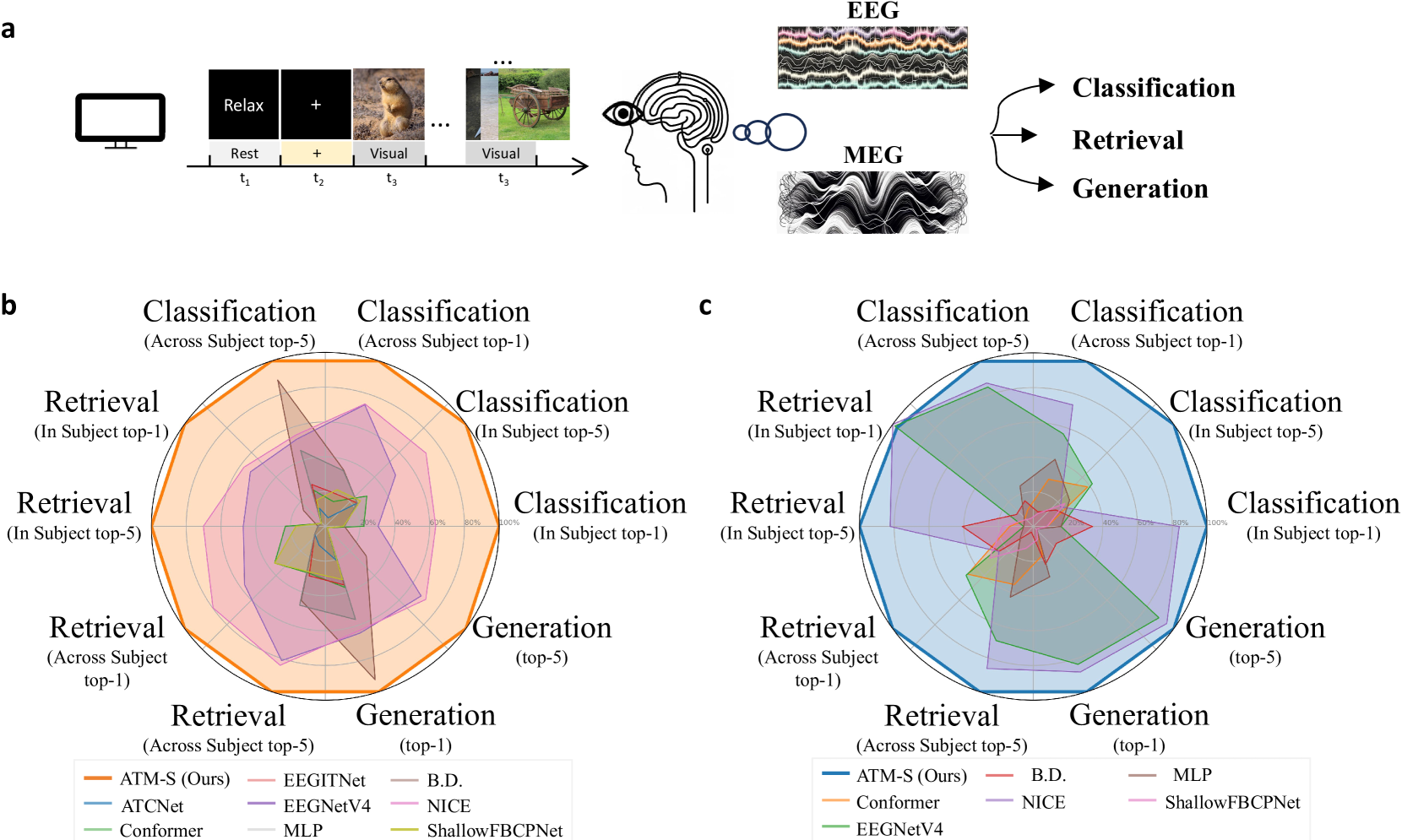
How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
4/8/2024

NeuSpeech: Decode Neural signal as Speech
Yiqian Yang, Yiqun Duan, Qiang Zhang, Hyejeong Jo, Jinni Zhou, Won Hee Lee, Renjing Xu, Hui Xiong
0
0
Decoding language from brain dynamics is an important open direction in the realm of brain-computer interface (BCI), especially considering the rapid growth of large language models. Compared to invasive-based signals which require electrode implantation surgery, non-invasive neural signals (e.g. EEG, MEG) have attracted increasing attention considering their safety and generality. However, the exploration is not adequate in three aspects: 1) previous methods mainly focus on EEG but none of the previous works address this problem on MEG with better signal quality; 2) prior works have predominantly used $``teacher-forcing$ during generative decoding, which is impractical; 3) prior works are mostly $``BART-based$ not fully auto-regressive, which performs better in other sequence tasks. In this paper, we explore the brain-to-text translation of MEG signals in a speech-decoding formation. Here we are the first to investigate a cross-attention-based ``whisper model for generating text directly from MEG signals without teacher forcing. Our model achieves impressive BLEU-1 scores of 60.30 and 52.89 without pretraining $&$ teacher-forcing on two major datasets ($textit{GWilliams}$ and $textit{Schoffelen}$). This paper conducts a comprehensive review to understand how speech decoding formation performs on the neural decoding tasks, including pretraining initialization, training $&$ evaluation set splitting, augmentation, and scaling law. Code is available at https://github.com/NeuSpeech/NeuSpeech1$.
6/4/2024
🖼️
Neuro-Vision to Language: Image Reconstruction and Interaction via Non-invasive Brain Recordings
Guobin Shen, Dongcheng Zhao, Xiang He, Linghao Feng, Yiting Dong, Jihang Wang, Qian Zhang, Yi Zeng
0
0
Decoding non-invasive brain recordings is pivotal for advancing our understanding of human cognition but faces challenges due to individual differences and complex neural signal representations. Traditional methods often require customized models and extensive trials, lacking interpretability in visual reconstruction tasks. Our framework integrates 3D brain structures with visual semantics using a Vision Transformer 3D. This unified feature extractor efficiently aligns fMRI features with multiple levels of visual embeddings, eliminating the need for subject-specific models and allowing extraction from single-trial data. The extractor consolidates multi-level visual features into one network, simplifying integration with Large Language Models (LLMs). Additionally, we have enhanced the fMRI dataset with diverse fMRI-image-related textual data to support multimodal large model development. Integrating with LLMs enhances decoding capabilities, enabling tasks such as brain captioning, complex reasoning, concept localization, and visual reconstruction. Our approach demonstrates superior performance across these tasks, precisely identifying language-based concepts within brain signals, enhancing interpretability, and providing deeper insights into neural processes. These advances significantly broaden the applicability of non-invasive brain decoding in neuroscience and human-computer interaction, setting the stage for advanced brain-computer interfaces and cognitive models.
5/24/2024

Revealing Vision-Language Integration in the Brain with Multimodal Networks
Vighnesh Subramaniam, Colin Conwell, Christopher Wang, Gabriel Kreiman, Boris Katz, Ignacio Cases, Andrei Barbu
0
0
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
6/21/2024