Revealing Vision-Language Integration in the Brain with Multimodal Networks

0

Sign in to get full access
Overview
- This paper explores how the brain integrates vision and language information using multimodal neural networks.
- The researchers developed a novel approach to reveal the neural mechanisms underlying this integration by leveraging the representational power of multimodal models.
- They conducted experiments to investigate how vision and language information are processed and combined in the brain, providing insights into the fundamental nature of human cognition.
Plain English Explanation
The human brain has a remarkable ability to combine information from different senses, such as sight and sound, to create a unified understanding of the world around us. This process, known as multimodal integration, is a crucial aspect of human cognition and perception.
In this research paper, the authors set out to uncover how the brain integrates visual and language information using advanced multimodal neural networks. By training these models on large datasets of images and text, the researchers were able to gain insights into the underlying neural mechanisms that allow us to seamlessly combine what we see and what we hear or read.
The key idea is that the representations learned by these multimodal models can serve as a proxy for understanding how the brain processes and integrates different types of information. By analyzing the internal workings of the models, the researchers were able to shed light on the dynamic and complex process of vision-language integration in the human brain.
Overall, this research provides valuable insights into the fundamental nature of human cognition and perception, with potential implications for fields ranging from cognitive neuroscience to the development of more human-like artificial intelligence.
Technical Explanation
The researchers leveraged the representational power of multimodal neural networks to investigate the neural mechanisms underlying the integration of vision and language information in the human brain. They trained these models on large datasets of images and text, and then analyzed the internal representations learned by the models to gain insights into the dynamic and complex process of vision-language integration.
The key to their approach was the use of
The experiments conducted in this study demonstrated that the multimodal models were able to capture key aspects of the brain's vision-language integration process, suggesting that these models can serve as powerful tools for cognitive neuroscience research. The insights gained from this work may also have implications for the development of more human-like artificial intelligence, as they shed light on the complex interplay between different sensory modalities in human intelligence.
Critical Analysis
The research presented in this paper offers a novel and promising approach to understanding the neural mechanisms underlying vision-language integration in the human brain. By leveraging the representational power of multimodal neural networks, the researchers were able to gain valuable insights that complement traditional neuroscientific methods.
However, it's important to note that the findings of this study are based on the performance of the multimodal models, which may not fully capture the complexity of the human brain. While the researchers made efforts to validate their approach, there are still potential limitations and caveats that should be considered.
For example, the paper does not address the role of individual differences in brain structure and function, which may influence the way vision and language information are integrated. Additionally, the experiments were conducted using specific datasets and model architectures, and it's unclear how the results would generalize to other contexts or settings.
Further research is needed to explore the robustness and generalizability of the findings, as well as to investigate the potential applications of this approach in fields such as cognitive neuroscience and artificial intelligence. By continuing to push the boundaries of our understanding of human cognition and perception, this line of research has the potential to contribute to advancements in our knowledge of the brain and the development of more human-like AI systems.
Conclusion
This research paper presents a novel approach to revealing the neural mechanisms underlying the integration of vision and language information in the human brain. By leveraging the representational power of multimodal neural networks, the researchers were able to gain valuable insights into the dynamic and complex process of vision-language integration.
The findings of this study have the potential to contribute to our understanding of the fundamental nature of human cognition and perception, with implications for fields ranging from cognitive neuroscience to the development of more human-like artificial intelligence. As researchers continue to explore the complex interplay between different sensory modalities, this line of research may unlock new insights into the inner workings of the human brain and pave the way for advancements in our understanding of multimodal integration and its role in intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Vighnesh Subramaniam, Colin Conwell, Christopher Wang, Gabriel Kreiman, Boris Katz, Ignacio Cases, Andrei Barbu
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
Read more6/21/2024
⚙️
0
Modelling Multimodal Integration in Human Concept Processing with Vision-and-Language Models
Anna Bavaresco, Marianne de Heer Kloots, Sandro Pezzelle, Raquel Fern'andez
Representations from deep neural networks (DNNs) have proven remarkably predictive of neural activity involved in both visual and linguistic processing. Despite these successes, most studies to date concern unimodal DNNs, encoding either visual or textual input but not both. Yet, there is growing evidence that human meaning representations integrate linguistic and sensory-motor information. Here we investigate whether the integration of multimodal information operated by current vision-and-language DNN models (VLMs) leads to representations that are more aligned with human brain activity than those obtained by language-only and vision-only DNNs. We focus on fMRI responses recorded while participants read concept words in the context of either a full sentence or an accompanying picture. Our results reveal that VLM representations correlate more strongly than language- and vision-only DNNs with activations in brain areas functionally related to language processing. A comparison between different types of visuo-linguistic architectures shows that recent generative VLMs tend to be less brain-aligned than previous architectures with lower performance on downstream applications. Moreover, through an additional analysis comparing brain vs. behavioural alignment across multiple VLMs, we show that -- with one remarkable exception -- representations that strongly align with behavioural judgments do not correlate highly with brain responses. This indicates that brain similarity does not go hand in hand with behavioural similarity, and vice versa.
Read more7/26/2024
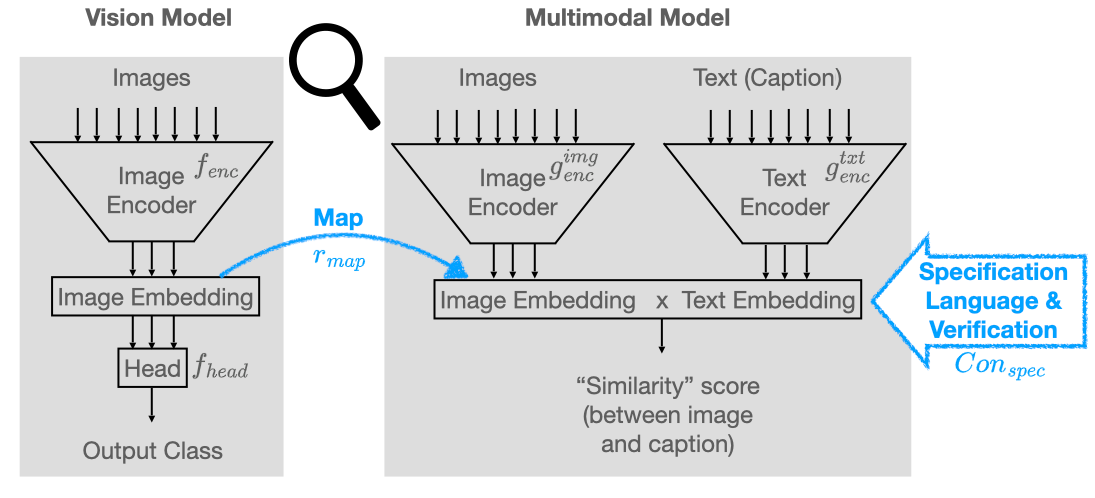
0
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
Read more4/12/2024

1
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-language models and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
Read more4/26/2024