DVMSR: Distillated Vision Mamba for Efficient Super-Resolution
2405.03008
0
0
👀
Abstract
Efficient Image Super-Resolution (SR) aims to accelerate SR network inference by minimizing computational complexity and network parameters while preserving performance. Existing state-of-the-art Efficient Image Super-Resolution methods are based on convolutional neural networks. Few attempts have been made with Mamba to harness its long-range modeling capability and efficient computational complexity, which have shown impressive performance on high-level vision tasks. In this paper, we propose DVMSR, a novel lightweight Image SR network that incorporates Vision Mamba and a distillation strategy. The network of DVMSR consists of three modules: feature extraction convolution, multiple stacked Residual State Space Blocks (RSSBs), and a reconstruction module. Specifically, the deep feature extraction module is composed of several residual state space blocks (RSSB), each of which has several Vision Mamba Moudles(ViMM) together with a residual connection. To achieve efficiency improvement while maintaining comparable performance, we employ a distillation strategy to the vision Mamba network for superior performance. Specifically, we leverage the rich representation knowledge of teacher network as additional supervision for the output of lightweight student networks. Extensive experiments have demonstrated that our proposed DVMSR can outperform state-of-the-art efficient SR methods in terms of model parameters while maintaining the performance of both PSNR and SSIM. The source code is available at https://github.com/nathan66666/DVMSR.git
Create account to get full access
Overview
- Proposes a novel lightweight Image Super-Resolution (SR) network called DVMSR that combines Vision Mamba and a distillation strategy
- Claims DVMSR can outperform state-of-the-art efficient SR methods in terms of model parameters while maintaining performance
- Leverages the long-range modeling capability and efficient computational complexity of Vision Mamba, which has shown impressive performance on high-level vision tasks
Plain English Explanation
The paper introduces a new efficient image super-resolution method called DVMSR. Super-resolution is the process of increasing the resolution and detail of an image. DVMSR aims to do this in a computationally efficient way, meaning it can run quickly on devices with limited resources.
DVMSR is built on two key ideas: Vision Mamba and a distillation strategy. Vision Mamba is a neural network architecture that has shown impressive performance on high-level vision tasks like image classification. It has the ability to model long-range relationships in images efficiently.
The distillation strategy means that DVMSR learns from a more powerful "teacher" model, allowing it to achieve high performance despite being a lightweight "student" model. This allows DVMSR to be fast and efficient while still producing high-quality super-resolved images.
The authors claim that DVMSR outperforms other efficient super-resolution methods in terms of model size and speed, while maintaining comparable image quality. This could be useful for applying super-resolution on devices with limited computing power, like smartphones or embedded systems.
Technical Explanation
The DVMSR network consists of three main modules: feature extraction, multiple stacked Residual State Space Blocks (RSSBs), and a reconstruction module. The feature extraction module uses several RSSBs, each of which contains Vision Mamba Modules (ViMMs) along with residual connections.
To achieve efficiency while maintaining performance, the authors employ a distillation strategy. They leverage the "rich representation knowledge" of a more powerful teacher network to provide additional supervision for the lightweight student DVMSR network. This allows DVMSR to learn an effective model for super-resolution despite its small size.
Extensive experiments showed that DVMSR outperforms other state-of-the-art efficient super-resolution methods in terms of model parameters, while achieving comparable PSNR (peak signal-to-noise ratio) and SSIM (structural similarity index) performance metrics.
Critical Analysis
The paper provides a thorough technical explanation of the DVMSR architecture and its training process. However, it does not go into much detail about the specific trade-offs or limitations of the approach.
For example, it's not clear how the distillation process is implemented or how the teacher and student networks are trained together. The authors also don't discuss the potential downsides of relying on Vision Mamba, such as whether its long-range modeling capabilities are truly necessary for super-resolution or if they come at the cost of increased complexity.
Additionally, the paper only evaluates DVMSR on standard super-resolution benchmarks. It would be helpful to see how the method performs on real-world applications or edge-case scenarios where efficiency and speed are critical.
Overall, the research appears promising, but more analysis of the method's strengths, weaknesses, and use cases would help readers better understand its practical implications and potential for further development.
Conclusion
This paper proposes a novel lightweight Image Super-Resolution (SR) network called DVMSR that combines the long-range modeling capabilities of Vision Mamba with a distillation strategy. DVMSR is able to outperform other efficient SR methods in terms of model size while maintaining comparable image quality.
The key innovation is the use of Vision Mamba modules and a distillation approach, which allows DVMSR to learn an effective super-resolution model despite its small size. This could make the method useful for deploying high-quality super-resolution on resource-constrained devices like smartphones or embedded systems.
While the technical details are well-explained, the paper could benefit from a more in-depth analysis of the method's trade-offs, limitations, and potential real-world applications. Overall, the research represents an interesting advance in the field of efficient image super-resolution.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution
Yi Xiao, Qiangqiang Yuan, Kui Jiang, Yuzeng Chen, Qiang Zhang, Chia-Wen Lin
0
0
Recent progress in remote sensing image (RSI) super-resolution (SR) has exhibited remarkable performance using deep neural networks, e.g., Convolutional Neural Networks and Transformers. However, existing SR methods often suffer from either a limited receptive field or quadratic computational overhead, resulting in sub-optimal global representation and unacceptable computational costs in large-scale RSI. To alleviate these issues, we develop the first attempt to integrate the Vision State Space Model (Mamba) for RSI-SR, which specializes in processing large-scale RSI by capturing long-range dependency with linear complexity. To achieve better SR reconstruction, building upon Mamba, we devise a Frequency-assisted Mamba framework, dubbed FMSR, to explore the spatial and frequent correlations. In particular, our FMSR features a multi-level fusion architecture equipped with the Frequency Selection Module (FSM), Vision State Space Module (VSSM), and Hybrid Gate Module (HGM) to grasp their merits for effective spatial-frequency fusion. Recognizing that global and local dependencies are complementary and both beneficial for SR, we further recalibrate these multi-level features for accurate feature fusion via learnable scaling adaptors. Extensive experiments on AID, DOTA, and DIOR benchmarks demonstrate that our FMSR outperforms state-of-the-art Transformer-based methods HAT-L in terms of PSNR by 0.11 dB on average, while consuming only 28.05% and 19.08% of its memory consumption and complexity, respectively.
5/9/2024
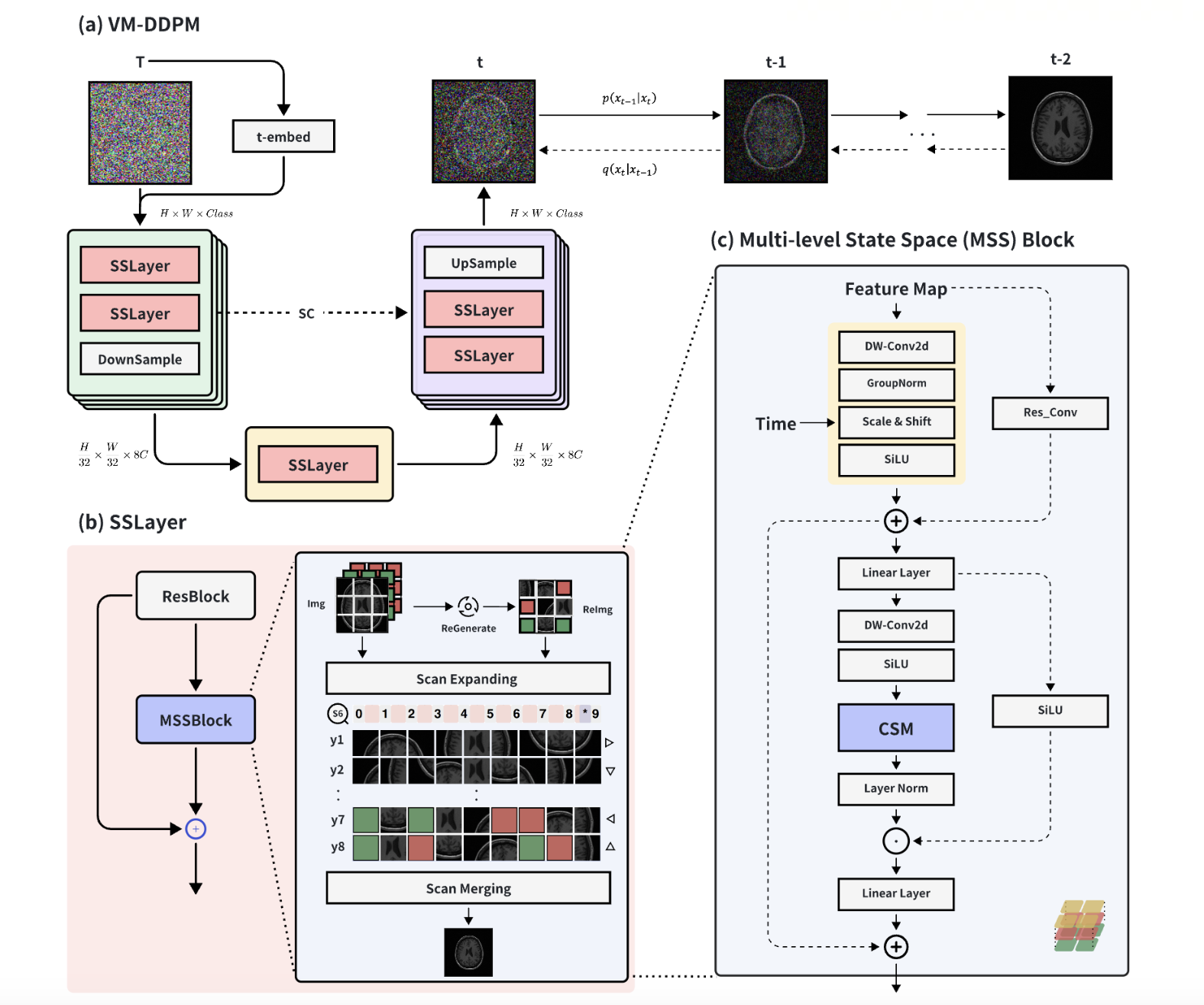
VM-DDPM: Vision Mamba Diffusion for Medical Image Synthesis
Zhihan Ju, Wanting Zhou
0
0
In the realm of smart healthcare, researchers enhance the scale and diversity of medical datasets through medical image synthesis. However, existing methods are limited by CNN local perception and Transformer quadratic complexity, making it difficult to balance structural texture consistency. To this end, we propose the Vision Mamba DDPM (VM-DDPM) based on State Space Model (SSM), fully combining CNN local perception and SSM global modeling capabilities, while maintaining linear computational complexity. Specifically, we designed a multi-level feature extraction module called Multi-level State Space Block (MSSBlock), and a basic unit of encoder-decoder structure called State Space Layer (SSLayer) for medical pathological images. Besides, we designed a simple, Plug-and-Play, zero-parameter Sequence Regeneration strategy for the Cross-Scan Module (CSM), which enabled the S6 module to fully perceive the spatial features of the 2D image and stimulate the generalization potential of the model. To our best knowledge, this is the first medical image synthesis model based on the SSM-CNN hybrid architecture. Our experimental evaluation on three datasets of different scales, i.e., ACDC, BraTS2018, and ChestXRay, as well as qualitative evaluation by radiologists, demonstrate that VM-DDPM achieves state-of-the-art performance.
5/10/2024
📈
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
Yuheng Shi, Minjing Dong, Chang Xu
0
0
Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at url{https://github.com/YuHengsss/MSVMamba}.
5/24/2024
🖼️
FusionMamba: Efficient Image Fusion with State Space Model
Siran Peng, Xiangyu Zhu, Haoyu Deng, Zhen Lei, Liang-Jian Deng
0
0
Image fusion aims to generate a high-resolution multi/hyper-spectral image by combining a high-resolution image with limited spectral information and a low-resolution image with abundant spectral data. Current deep learning (DL)-based methods for image fusion primarily rely on CNNs or Transformers to extract features and merge different types of data. While CNNs are efficient, their receptive fields are limited, restricting their capacity to capture global context. Conversely, Transformers excel at learning global information but are hindered by their quadratic complexity. Fortunately, recent advancements in the State Space Model (SSM), particularly Mamba, offer a promising solution to this issue by enabling global awareness with linear complexity. However, there have been few attempts to explore the potential of the SSM in information fusion, which is a crucial ability in domains like image fusion. Therefore, we propose FusionMamba, an innovative method for efficient image fusion. Our contributions mainly focus on two aspects. Firstly, recognizing that images from different sources possess distinct properties, we incorporate Mamba blocks into two U-shaped networks, presenting a novel architecture that extracts spatial and spectral features in an efficient, independent, and hierarchical manner. Secondly, to effectively combine spatial and spectral information, we extend the Mamba block to accommodate dual inputs. This expansion leads to the creation of a new module called the FusionMamba block, which outperforms existing fusion techniques such as concatenation and cross-attention. We conduct a series of experiments on five datasets related to three image fusion tasks. The quantitative and qualitative evaluation results demonstrate that our method achieves SOTA performance, underscoring the superiority of FusionMamba. The code is available at https://github.com/PSRben/FusionMamba.
5/14/2024