Dynamic importance learning using fisher information gain for nonlinear system identification
2406.05395
0
0
🐍
Abstract
The Fisher Information Matrix (FIM) provides a way for quantifying the information content of an observable random variable concerning unknown parameters within a model that characterizes the variable. When parameters in a model are directly linked to individual features, the diagonal elements of the FIM can signify the relative importance of each feature. However, in scenarios where feature interactions may exist, a comprehensive exploration of the full FIM is necessary rather than focusing solely on its diagonal elements. This paper presents an end-to-end black box system identification approach that integrates the FIM into the training process to gain insights into dynamic importance and overall model structure. A decision module is added to the first layer of the network to determine the relevance scores using the entire FIM as input. The forward propagation is then performed on element-wise multiplication of inputs and relevance scores. Simulation results demonstrate that the proposed methodology effectively captures various types of interactions between dynamics, outperforming existing methods limited to polynomial interactions. Moreover, the effectiveness of this novel approach is confirmed through its application in identifying a real-world industrial system, specifically the PH neutralization process.
Create account to get full access
Overview
- This paper presents a novel approach to system identification that integrates the Fisher Information Matrix (FIM) into the training process to gain insights into dynamic importance and overall model structure.
- The proposed method adds a decision module to the first layer of the network to determine relevance scores using the entire FIM as input, and then performs forward propagation on the element-wise multiplication of inputs and relevance scores.
- The effectiveness of this approach is demonstrated through simulation results and its application to a real-world industrial system, the PH neutralization process.
Plain English Explanation
The Fisher Information Matrix (FIM) is a way to measure how much information an observable random variable contains about the unknown parameters in a model that describes that variable. When the parameters in a model are directly linked to individual features, the diagonal elements of the FIM can indicate the relative importance of each feature. However, in cases where feature interactions may exist, a more comprehensive analysis of the full FIM is necessary, rather than just focusing on the diagonal elements.
In this paper, the researchers present a new approach to system identification that integrates the FIM into the training process. They add a "decision module" to the first layer of the neural network, which uses the entire FIM as input to determine the relevance scores for each feature. The network then performs forward propagation while multiplying the inputs by these relevance scores. This allows the system to capture various types of interactions between the dynamic features, which existing methods limited to polynomial interactions may miss.
The researchers demonstrate the effectiveness of their approach through simulation results and by applying it to a real-world industrial system, the PH neutralization process. This [novel approach to [object Object] in supervised learning] can provide valuable insights into the importance and interactions of different features in a model.
Technical Explanation
The core of the proposed methodology is the integration of the Fisher Information Matrix (FIM) into the training process of a black box system identification model. The FIM is a way to quantify the information content of an observable random variable with respect to the unknown parameters in a model.
The researchers add a "decision module" to the first layer of the neural network, which takes the entire FIM as input and determines relevance scores for each feature. These relevance scores are then used to perform element-wise multiplication with the network inputs during forward propagation. This allows the model to capture various types of feature interactions, going beyond the limitations of existing methods that focus only on polynomial interactions.
The effectiveness of this approach is demonstrated through both simulation results and its application to a real-world industrial system, the PH neutralization process. The simulation results show that the proposed methodology outperforms existing methods in capturing various types of interactions between dynamic features.
Furthermore, the application to the PH neutralization process, a complex real-world system, confirms the practical utility of this [novel approach to [object Object]] in system identification.
Critical Analysis
The paper presents a promising approach to system identification that leverages the Fisher Information Matrix to gain insights into the importance and interactions of different features. The researchers have demonstrated the effectiveness of their method through simulation results and a real-world industrial application.
One potential limitation of the approach is that it may be computationally intensive, as the decision module requires the computation of the full FIM. This could be a concern for larger, more complex models. The researchers acknowledge this in the paper and suggest that [object Object] could be explored as a way to address this issue.
Additionally, the paper does not provide a detailed analysis of the limitations or potential biases of the FIM-based approach. For example, the FIM can be sensitive to the choice of parametrization, which could impact the reliability of the relevance scores computed by the decision module.
Overall, the proposed methodology is a valuable contribution to the field of system identification, as it offers a novel way to [object Object] within complex models. Further research exploring the computational efficiency and robustness of the approach would be beneficial to fully assess its potential and limitations.
Conclusion
This paper presents an end-to-end black box system identification approach that integrates the Fisher Information Matrix (FIM) into the training process to gain insights into dynamic importance and overall model structure. The proposed method adds a decision module to the first layer of the network to determine relevance scores using the entire FIM as input, and then performs forward propagation on the element-wise multiplication of inputs and relevance scores.
The effectiveness of this novel approach is demonstrated through simulation results and its application to a real-world industrial system, the PH neutralization process. This integration of the FIM into the training process allows the model to capture various types of feature interactions, going beyond the limitations of existing methods.
The research presented in this paper represents an important step forward in [object Object] within complex models, and could have significant implications for the field of system identification and the development of more robust and interpretable machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
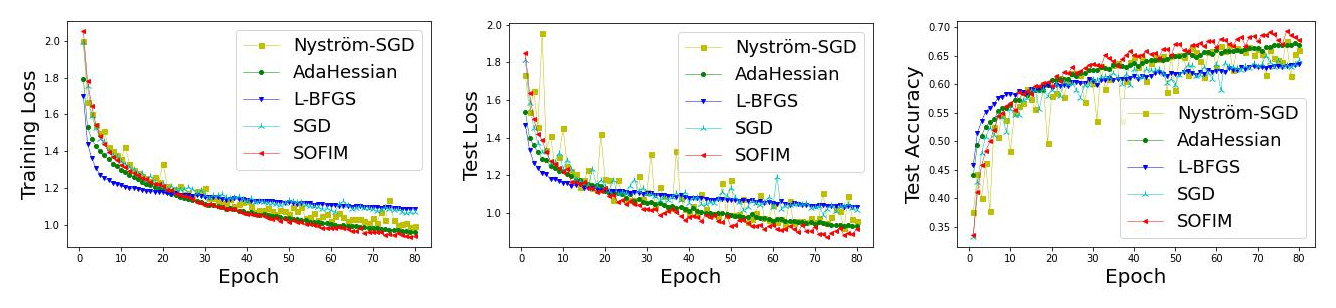
SOFIM: Stochastic Optimization Using Regularized Fisher Information Matrix
Mrinmay Sen, A. K. Qin, Gayathri C, Raghu Kishore N, Yen-Wei Chen, Balasubramanian Raman
0
0
This paper introduces a new stochastic optimization method based on the regularized Fisher information matrix (FIM), named SOFIM, which can efficiently utilize the FIM to approximate the Hessian matrix for finding Newton's gradient update in large-scale stochastic optimization of machine learning models. It can be viewed as a variant of natural gradient descent, where the challenge of storing and calculating the full FIM is addressed through making use of the regularized FIM and directly finding the gradient update direction via Sherman-Morrison matrix inversion. Additionally, like the popular Adam method, SOFIM uses the first moment of the gradient to address the issue of non-stationary objectives across mini-batches due to heterogeneous data. The utilization of the regularized FIM and Sherman-Morrison matrix inversion leads to the improved convergence rate with the same space and time complexities as stochastic gradient descent (SGD) with momentum. The extensive experiments on training deep learning models using several benchmark image classification datasets demonstrate that the proposed SOFIM outperforms SGD with momentum and several state-of-the-art Newton optimization methods in term of the convergence speed for achieving the pre-specified objectives of training and test losses as well as test accuracy.
5/2/2024

Tradeoffs of Diagonal Fisher Information Matrix Estimators
Alexander Soen, Ke Sun
0
0
The Fisher information matrix characterizes the local geometry in the parameter space of neural networks. It elucidates insightful theories and useful tools to understand and optimize neural networks. Given its high computational cost, practitioners often use random estimators and evaluate only the diagonal entries. We examine two such estimators, whose accuracy and sample complexity depend on their associated variances. We derive bounds of the variances and instantiate them in regression and classification networks. We navigate trade-offs of both estimators based on analytical and numerical studies. We find that the variance quantities depend on the non-linearity with respect to different parameter groups and should not be neglected when estimating the Fisher information.
4/4/2024
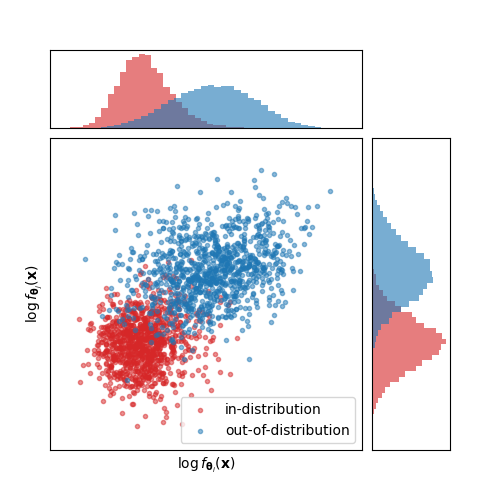
Approximations to the Fisher Information Metric of Deep Generative Models for Out-Of-Distribution Detection
Sam Dauncey, Chris Holmes, Christopher Williams, Fabian Falck
0
0
Likelihood-based deep generative models such as score-based diffusion models and variational autoencoders are state-of-the-art machine learning models approximating high-dimensional distributions of data such as images, text, or audio. One of many downstream tasks they can be naturally applied to is out-of-distribution (OOD) detection. However, seminal work by Nalisnick et al. which we reproduce showed that deep generative models consistently infer higher log-likelihoods for OOD data than data they were trained on, marking an open problem. In this work, we analyse using the gradient of a data point with respect to the parameters of the deep generative model for OOD detection, based on the simple intuition that OOD data should have larger gradient norms than training data. We formalise measuring the size of the gradient as approximating the Fisher information metric. We show that the Fisher information matrix (FIM) has large absolute diagonal values, motivating the use of chi-square distributed, layer-wise gradient norms as features. We combine these features to make a simple, model-agnostic and hyperparameter-free method for OOD detection which estimates the joint density of the layer-wise gradient norms for a given data point. We find that these layer-wise gradient norms are weakly correlated, rendering their combined usage informative, and prove that the layer-wise gradient norms satisfy the principle of (data representation) invariance. Our empirical results indicate that this method outperforms the Typicality test for most deep generative models and image dataset pairings.
5/28/2024

Unveiling the Dynamics of Information Interplay in Supervised Learning
Kun Song, Zhiquan Tan, Bochao Zou, Huimin Ma, Weiran Huang
0
0
In this paper, we use matrix information theory as an analytical tool to analyze the dynamics of the information interplay between data representations and classification head vectors in the supervised learning process. Specifically, inspired by the theory of Neural Collapse, we introduce matrix mutual information ratio (MIR) and matrix entropy difference ratio (HDR) to assess the interactions of data representation and class classification heads in supervised learning, and we determine the theoretical optimal values for MIR and HDR when Neural Collapse happens. Our experiments show that MIR and HDR can effectively explain many phenomena occurring in neural networks, for example, the standard supervised training dynamics, linear mode connectivity, and the performance of label smoothing and pruning. Additionally, we use MIR and HDR to gain insights into the dynamics of grokking, which is an intriguing phenomenon observed in supervised training, where the model demonstrates generalization capabilities long after it has learned to fit the training data. Furthermore, we introduce MIR and HDR as loss terms in supervised and semi-supervised learning to optimize the information interactions among samples and classification heads. The empirical results provide evidence of the method's effectiveness, demonstrating that the utilization of MIR and HDR not only aids in comprehending the dynamics throughout the training process but can also enhances the training procedure itself.
6/7/2024