Tradeoffs of Diagonal Fisher Information Matrix Estimators
2402.05379
0
0

Abstract
The Fisher information matrix characterizes the local geometry in the parameter space of neural networks. It elucidates insightful theories and useful tools to understand and optimize neural networks. Given its high computational cost, practitioners often use random estimators and evaluate only the diagonal entries. We examine two such estimators, whose accuracy and sample complexity depend on their associated variances. We derive bounds of the variances and instantiate them in regression and classification networks. We navigate trade-offs of both estimators based on analytical and numerical studies. We find that the variance quantities depend on the non-linearity with respect to different parameter groups and should not be neglected when estimating the Fisher information.
Create account to get full access
Overview
- Examines the tradeoffs of different methods for estimating the diagonal of the Fisher Information Matrix (FIM), a key metric in machine learning and optimization
- Provides a theoretical analysis of the variance of diagonal FIM estimators under different assumptions
- Discusses the practical implications of these results for training machine learning models
Plain English Explanation
This paper explores the pros and cons of different ways to estimate a specific mathematical quantity called the diagonal of the Fisher Information Matrix (FIM). The FIM is an important concept in machine learning and optimization, as it helps quantify how sensitive a model's performance is to changes in its parameters.
The authors show that there are several different methods that can be used to estimate the diagonal of the FIM, each with their own advantages and disadvantages. For example, some methods may be more accurate but require more computational power, while others are faster but less precise. The paper provides a clear, jargon-free explanation of these tradeoffs.
Understanding these tradeoffs is important for practitioners who are training machine learning models, as the choice of FIM estimation method can impact the efficiency and effectiveness of the training process. The insights from this paper could help researchers and engineers make more informed decisions about which FIM estimation approach to use in their work.
Technical Explanation
The paper analyzes the variance of different diagonal FIM estimators, which are used to approximate the full Fisher Information Matrix (FIM) in machine learning applications. This is important because the FIM is a key quantity in optimization algorithms, generalization bounds, and other aspects of model training.
The authors consider several different estimators of the diagonal FIM, including the standard sample covariance, the Hutchinson estimator, and the Gaussian estimator. They derive theoretical expressions for the variance of these estimators under different assumptions, such as the distribution of the model parameters and the underlying data generating process.
The results show that there are fundamental tradeoffs between the computational cost, statistical efficiency, and robustness of these different diagonal FIM estimators. For example, the sample covariance estimator is computationally efficient but has high variance, while the Hutchinson estimator has lower variance but is more computationally intensive. The paper discusses how these tradeoffs should inform the choice of FIM estimation method in practice.
Critical Analysis
The paper provides a thorough theoretical analysis of diagonal FIM estimators, but there are a few potential limitations to consider. First, the analysis assumes that the model parameters and data follow certain distributional assumptions, which may not always hold in practice. It would be interesting to see how robust the results are to violations of these assumptions.
Additionally, the paper focuses on the variance of the estimators, but does not explicitly consider other important factors like bias and mean squared error. A more comprehensive analysis of the statistical properties of these estimators could provide additional insights.
Finally, the paper does not directly compare the performance of these diagonal FIM estimators in the context of actual machine learning tasks. Empirical studies evaluating how the choice of FIM estimation method affects model training and performance would be a valuable complement to the theoretical analysis.
Conclusion
This paper provides a detailed theoretical analysis of the tradeoffs involved in estimating the diagonal of the Fisher Information Matrix (FIM), a key quantity in machine learning optimization and generalization. The results show that there are fundamental tradeoffs between the computational cost, statistical efficiency, and robustness of different diagonal FIM estimators.
These insights could help practitioners make more informed choices about which FIM estimation method to use when training machine learning models, potentially leading to more efficient and effective optimization procedures. While the analysis is thorough, there are a few potential limitations and areas for further research, such as examining the impact of distributional assumptions and evaluating the estimators' performance on actual machine learning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
Dynamic importance learning using fisher information gain for nonlinear system identification
Vahid MohammadZadeh Eivaghi, Mahdi Aliyari Shoorehdeli
0
0
The Fisher Information Matrix (FIM) provides a way for quantifying the information content of an observable random variable concerning unknown parameters within a model that characterizes the variable. When parameters in a model are directly linked to individual features, the diagonal elements of the FIM can signify the relative importance of each feature. However, in scenarios where feature interactions may exist, a comprehensive exploration of the full FIM is necessary rather than focusing solely on its diagonal elements. This paper presents an end-to-end black box system identification approach that integrates the FIM into the training process to gain insights into dynamic importance and overall model structure. A decision module is added to the first layer of the network to determine the relevance scores using the entire FIM as input. The forward propagation is then performed on element-wise multiplication of inputs and relevance scores. Simulation results demonstrate that the proposed methodology effectively captures various types of interactions between dynamics, outperforming existing methods limited to polynomial interactions. Moreover, the effectiveness of this novel approach is confirmed through its application in identifying a real-world industrial system, specifically the PH neutralization process.
6/11/2024
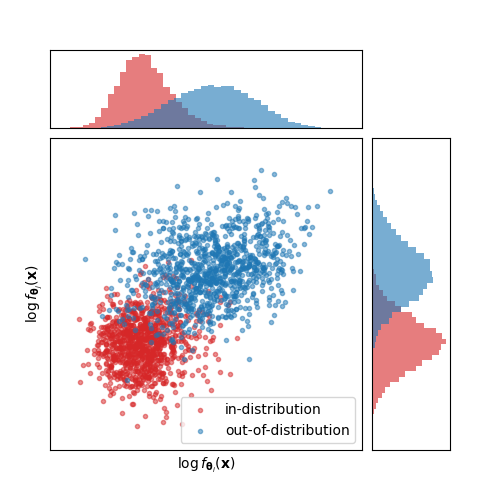
Approximations to the Fisher Information Metric of Deep Generative Models for Out-Of-Distribution Detection
Sam Dauncey, Chris Holmes, Christopher Williams, Fabian Falck
0
0
Likelihood-based deep generative models such as score-based diffusion models and variational autoencoders are state-of-the-art machine learning models approximating high-dimensional distributions of data such as images, text, or audio. One of many downstream tasks they can be naturally applied to is out-of-distribution (OOD) detection. However, seminal work by Nalisnick et al. which we reproduce showed that deep generative models consistently infer higher log-likelihoods for OOD data than data they were trained on, marking an open problem. In this work, we analyse using the gradient of a data point with respect to the parameters of the deep generative model for OOD detection, based on the simple intuition that OOD data should have larger gradient norms than training data. We formalise measuring the size of the gradient as approximating the Fisher information metric. We show that the Fisher information matrix (FIM) has large absolute diagonal values, motivating the use of chi-square distributed, layer-wise gradient norms as features. We combine these features to make a simple, model-agnostic and hyperparameter-free method for OOD detection which estimates the joint density of the layer-wise gradient norms for a given data point. We find that these layer-wise gradient norms are weakly correlated, rendering their combined usage informative, and prove that the layer-wise gradient norms satisfy the principle of (data representation) invariance. Our empirical results indicate that this method outperforms the Typicality test for most deep generative models and image dataset pairings.
5/28/2024

AdaFisher: Adaptive Second Order Optimization via Fisher Information
Damien Martins Gomes, Yanlei Zhang, Eugene Belilovsky, Guy Wolf, Mahdi S. Hosseini
0
0
First-order optimization methods are currently the mainstream in training deep neural networks (DNNs). Optimizers like Adam incorporate limited curvature information by employing the diagonal matrix preconditioning of the stochastic gradient during the training. Despite their widespread, second-order optimization algorithms exhibit superior convergence properties compared to their first-order counterparts e.g. Adam and SGD. However, their practicality in training DNNs are still limited due to increased per-iteration computations and suboptimal accuracy compared to the first order methods. We present AdaFisher--an adaptive second-order optimizer that leverages a block-diagonal approximation to the Fisher information matrix for adaptive gradient preconditioning. AdaFisher aims to bridge the gap between enhanced convergence capabilities and computational efficiency in second-order optimization framework for training DNNs. Despite the slow pace of second-order optimizers, we showcase that AdaFisher can be reliably adopted for image classification, language modelling and stand out for its stability and robustness in hyperparameter tuning. We demonstrate that AdaFisher outperforms the SOTA optimizers in terms of both accuracy and convergence speed. Code available from href{https://github.com/AtlasAnalyticsLab/AdaFisher}{https://github.com/AtlasAnalyticsLab/AdaFisher}
5/28/2024
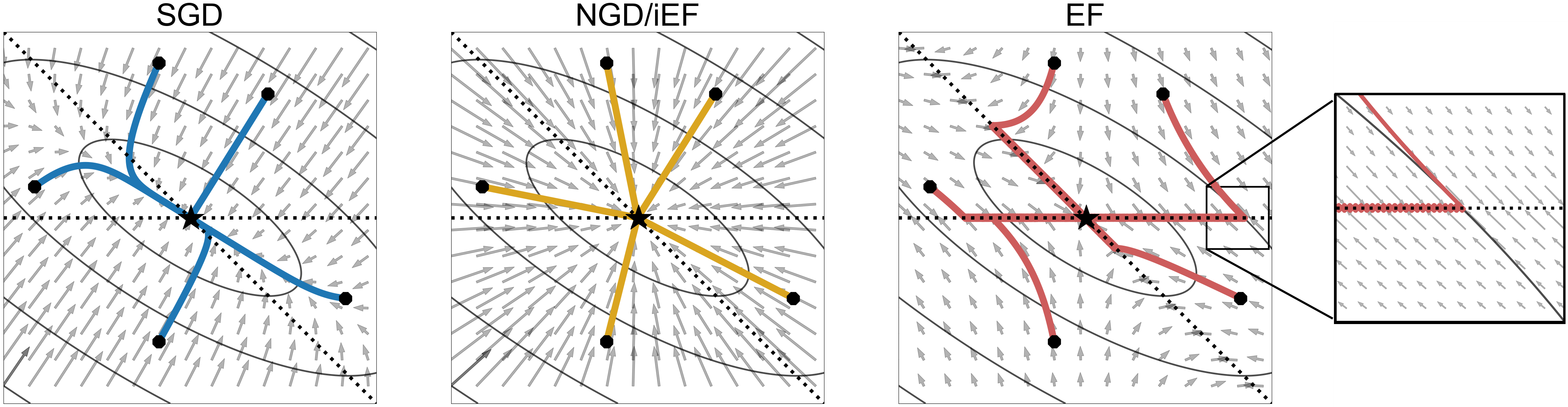
An Improved Empirical Fisher Approximation for Natural Gradient Descent
Xiaodong Wu, Wenyi Yu, Chao Zhang, Philip Woodland
0
0
Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper first investigates the inversely-scaled projection issue of EF, which is shown to be a major cause of the poor empirical approximation quality. An improved empirical Fisher (iEF) method, motivated as a generalised NGD method from a loss reduction perspective, is proposed to address this issue, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for majority of the tasks, even when compared with well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to the exact Natural Gradient updates than both EF and the more expensive sampled Fisher (SF). Further investigation also shows that the superior approximation quality of iEF is robust to damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence ability and stronger robustness to choice of damping.
6/11/2024