EAGLE: Eigen Aggregation Learning for Object-Centric Unsupervised Semantic Segmentation
2403.01482
0
0

Abstract
Semantic segmentation has innately relied on extensive pixel-level annotated data, leading to the emergence of unsupervised methodologies. Among them, leveraging self-supervised Vision Transformers for unsupervised semantic segmentation (USS) has been making steady progress with expressive deep features. Yet, for semantically segmenting images with complex objects, a predominant challenge remains: the lack of explicit object-level semantic encoding in patch-level features. This technical limitation often leads to inadequate segmentation of complex objects with diverse structures. To address this gap, we present a novel approach, EAGLE, which emphasizes object-centric representation learning for unsupervised semantic segmentation. Specifically, we introduce EiCue, a spectral technique providing semantic and structural cues through an eigenbasis derived from the semantic similarity matrix of deep image features and color affinity from an image. Further, by incorporating our object-centric contrastive loss with EiCue, we guide our model to learn object-level representations with intra- and inter-image object-feature consistency, thereby enhancing semantic accuracy. Extensive experiments on COCO-Stuff, Cityscapes, and Potsdam-3 datasets demonstrate the state-of-the-art USS results of EAGLE with accurate and consistent semantic segmentation across complex scenes.
Create account to get full access
Introduction
Related Work
Methods
Experiments
Conclusion
A. Additional Material: Project Page & Presentation Video
B. Additional Evaluation Results
Additional Experiments
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
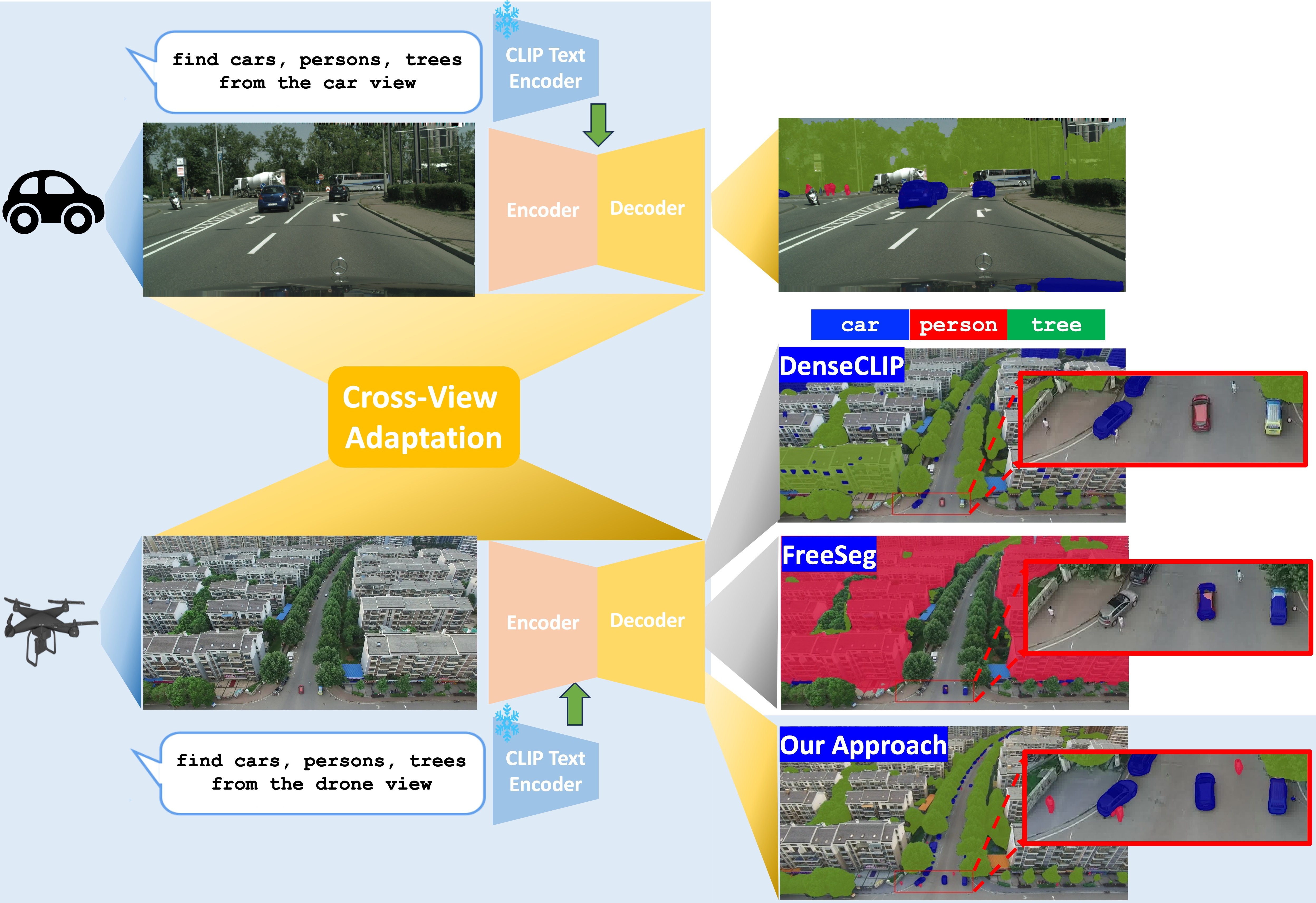
EAGLE: Efficient Adaptive Geometry-based Learning in Cross-view Understanding
Thanh-Dat Truong, Utsav Prabhu, Dongyi Wang, Bhiksha Raj, Susan Gauch, Jeyamkondan Subbiah, Khoa Luu
0
0
Unsupervised Domain Adaptation has been an efficient approach to transferring the semantic segmentation model across data distributions. Meanwhile, the recent Open-vocabulary Semantic Scene understanding based on large-scale vision language models is effective in open-set settings because it can learn diverse concepts and categories. However, these prior methods fail to generalize across different camera views due to the lack of cross-view geometric modeling. At present, there are limited studies analyzing cross-view learning. To address this problem, we introduce a novel Unsupervised Cross-view Adaptation Learning approach to modeling the geometric structural change across views in Semantic Scene Understanding. First, we introduce a novel Cross-view Geometric Constraint on Unpaired Data to model structural changes in images and segmentation masks across cameras. Second, we present a new Geodesic Flow-based Correlation Metric to efficiently measure the geometric structural changes across camera views. Third, we introduce a novel view-condition prompting mechanism to enhance the view-information modeling of the open-vocabulary segmentation network in cross-view adaptation learning. The experiments on different cross-view adaptation benchmarks have shown the effectiveness of our approach in cross-view modeling, demonstrating that we achieve State-of-the-Art (SOTA) performance compared to prior unsupervised domain adaptation and open-vocabulary semantic segmentation methods.
6/4/2024
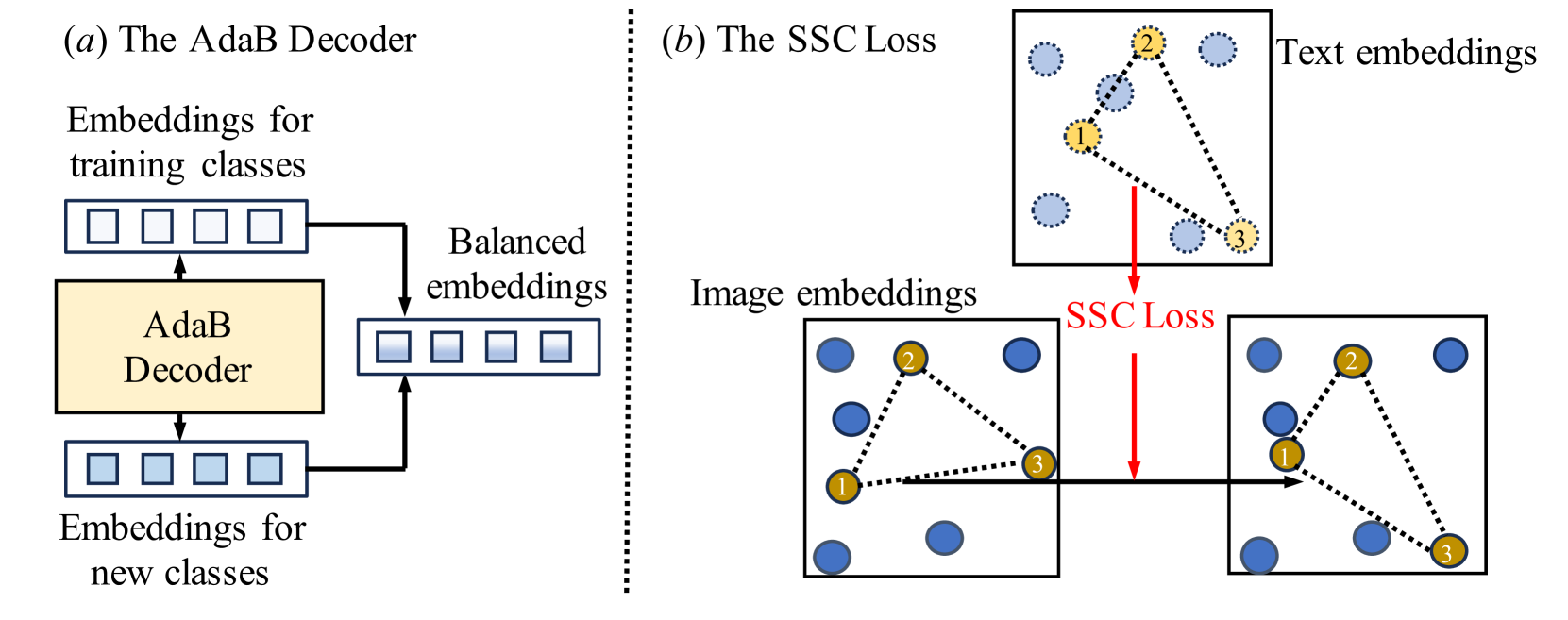
Open-Vocabulary Semantic Segmentation with Image Embedding Balancing
Xiangheng Shan, Dongyue Wu, Guilin Zhu, Yuanjie Shao, Nong Sang, Changxin Gao
0
0
Open-vocabulary semantic segmentation is a challenging task, which requires the model to output semantic masks of an image beyond a close-set vocabulary. Although many efforts have been made to utilize powerful CLIP models to accomplish this task, they are still easily overfitting to training classes due to the natural gaps in semantic information between training and new classes. To overcome this challenge, we propose a novel framework for openvocabulary semantic segmentation called EBSeg, incorporating an Adaptively Balanced Decoder (AdaB Decoder) and a Semantic Structure Consistency loss (SSC Loss). The AdaB Decoder is designed to generate different image embeddings for both training and new classes. Subsequently, these two types of embeddings are adaptively balanced to fully exploit their ability to recognize training classes and generalization ability for new classes. To learn a consistent semantic structure from CLIP, the SSC Loss aligns the inter-classes affinity in the image feature space with that in the text feature space of CLIP, thereby improving the generalization ability of our model. Furthermore, we employ a frozen SAM image encoder to complement the spatial information that CLIP features lack due to the low training image resolution and image-level supervision inherent in CLIP. Extensive experiments conducted across various benchmarks demonstrate that the proposed EBSeg outperforms the state-of-the-art methods. Our code and trained models will be here: https://github.com/slonetime/EBSeg.
6/17/2024
🌿
Decoding Natural Images from EEG for Object Recognition
Yonghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun Wang, Xiaorong Gao
0
0
Electroencephalography (EEG) signals, known for convenient non-invasive acquisition but low signal-to-noise ratio, have recently gained substantial attention due to the potential to decode natural images. This paper presents a self-supervised framework to demonstrate the feasibility of learning image representations from EEG signals, particularly for object recognition. The framework utilizes image and EEG encoders to extract features from paired image stimuli and EEG responses. Contrastive learning aligns these two modalities by constraining their similarity. With the framework, we attain significantly above-chance results on a comprehensive EEG-image dataset, achieving a top-1 accuracy of 15.6% and a top-5 accuracy of 42.8% in challenging 200-way zero-shot tasks. Moreover, we perform extensive experiments to explore the biological plausibility by resolving the temporal, spatial, spectral, and semantic aspects of EEG signals. Besides, we introduce attention modules to capture spatial correlations, providing implicit evidence of the brain activity perceived from EEG data. These findings yield valuable insights for neural decoding and brain-computer interfaces in real-world scenarios. The code will be released on https://github.com/eeyhsong/NICE-EEG.
4/5/2024
⚙️
Learning Object Semantic Similarity with Self-Supervision
Arthur Aubret, Timothy Schaumloffel, Gemma Roig, Jochen Triesch
0
0
Humans judge the similarity of two objects not just based on their visual appearance but also based on their semantic relatedness. However, it remains unclear how humans learn about semantic relationships between objects and categories. One important source of semantic knowledge is that semantically related objects frequently co-occur in the same context. For instance, forks and plates are perceived as similar, at least in part, because they are often experienced together in a ``kitchen or ``eating'' context. Here, we investigate whether a bio-inspired learning principle exploiting such co-occurrence statistics suffices to learn a semantically structured object representation {em de novo} from raw visual or combined visual and linguistic input. To this end, we simulate temporal sequences of visual experience by binding together short video clips of real-world scenes showing objects in different contexts. A bio-inspired neural network model aligns close-in-time visual representations while also aligning visual and category label representations to simulate visuo-language alignment. Our results show that our model clusters object representations based on their context, e.g. kitchen or bedroom, in particular in high-level layers of the network, akin to humans. In contrast, lower-level layers tend to better reflect object identity or category. To achieve this, the model exploits two distinct strategies: the visuo-language alignment ensures that different objects of the same category are represented similarly, whereas the temporal alignment leverages that objects from the same context are frequently seen in succession to make their representations more similar. Overall, our work suggests temporal and visuo-language alignment as plausible computational principles for explaining the origins of certain forms of semantic knowledge in humans.
5/9/2024