Decoding Natural Images from EEG for Object Recognition
2308.13234
0
0
🌿
Abstract
Electroencephalography (EEG) signals, known for convenient non-invasive acquisition but low signal-to-noise ratio, have recently gained substantial attention due to the potential to decode natural images. This paper presents a self-supervised framework to demonstrate the feasibility of learning image representations from EEG signals, particularly for object recognition. The framework utilizes image and EEG encoders to extract features from paired image stimuli and EEG responses. Contrastive learning aligns these two modalities by constraining their similarity. With the framework, we attain significantly above-chance results on a comprehensive EEG-image dataset, achieving a top-1 accuracy of 15.6% and a top-5 accuracy of 42.8% in challenging 200-way zero-shot tasks. Moreover, we perform extensive experiments to explore the biological plausibility by resolving the temporal, spatial, spectral, and semantic aspects of EEG signals. Besides, we introduce attention modules to capture spatial correlations, providing implicit evidence of the brain activity perceived from EEG data. These findings yield valuable insights for neural decoding and brain-computer interfaces in real-world scenarios. The code will be released on https://github.com/eeyhsong/NICE-EEG.
Create account to get full access
Overview
- This paper explores the feasibility of learning image representations from electroencephalography (EEG) signals, which are brain activity recordings.
- The researchers developed a self-supervised framework that uses image and EEG encoders to extract features from paired image stimuli and EEG responses, aligning them through contrastive learning.
- The framework achieves significantly above-chance results on a challenging 200-way zero-shot object recognition task using EEG data.
- The paper also investigates the biological plausibility of the approach by analyzing the temporal, spatial, spectral, and semantic aspects of the EEG signals.
- Attention modules are introduced to capture spatial correlations, providing insights into the brain activity perceived from the EEG data.
Plain English Explanation
Electroencephalography (EEG) is a technique that measures electrical activity in the brain. While EEG signals can be collected non-invasively, they often have a low signal-to-noise ratio, meaning the brain activity recordings can be noisy and difficult to interpret.
However, this paper demonstrates that it is possible to learn image representations from EEG signals, particularly for the task of object recognition. The researchers developed a self-supervised framework that uses two separate neural networks: one to extract features from images, and another to extract features from the corresponding EEG signals.
By training these networks to align the features from the images and EEG signals, the framework is able to recognize objects in images based solely on the brain activity recorded by the EEG. In a challenging task with 200 different objects, the framework achieved a top-1 accuracy of 15.6% and a top-5 accuracy of 42.8%, which is significantly better than chance.
The researchers also explored the biological plausibility of their approach by analyzing different aspects of the EEG signals, such as their temporal, spatial, and spectral characteristics. They found that attention modules, which capture spatial correlations, can provide insights into the brain activity perceived from the EEG data.
These findings have important implications for neural decoding and brain-computer interfaces, which aim to translate brain signals into useful information or commands. The ability to extract meaningful representations from noisy EEG data could lead to improved applications in areas like assistive technology and brain-controlled devices.
Technical Explanation
The paper presents a self-supervised framework for learning image representations from EEG signals. The framework consists of two main components: an image encoder and an EEG encoder. The image encoder extracts visual features from the input images, while the EEG encoder extracts features from the corresponding EEG responses.
The key aspect of the framework is the use of contrastive learning to align the features extracted from the two modalities (images and EEG signals). This is done by constraining the similarity between the image and EEG features, encouraging the network to learn representations that capture the relationship between the visual information and the underlying brain activity.
Through extensive experiments, the researchers demonstrate that this self-supervised framework can achieve significantly above-chance performance on a challenging 200-way zero-shot object recognition task using only EEG data. Specifically, they report a top-1 accuracy of 15.6% and a top-5 accuracy of 42.8%.
To further explore the biological plausibility of their approach, the researchers analyze the temporal, spatial, spectral, and semantic aspects of the EEG signals. They find that attention modules, which capture spatial correlations, can provide implicit evidence of the brain activity perceived from the EEG data.
These findings contribute to the understanding of neural decoding and the potential of EEG-based brain-computer interfaces, which could have real-world applications in areas such as assistive technology and brain-controlled devices.
Critical Analysis
The paper presents a novel and promising approach for learning image representations from EEG signals. However, it is important to consider some of the caveats and limitations of the research.
One potential limitation is the relatively low performance of the framework on the 200-way zero-shot object recognition task, with a top-1 accuracy of only 15.6%. While this is significantly better than chance, it still leaves room for improvement, especially for practical applications that may require higher accuracy.
Additionally, the paper does not provide a detailed analysis of the specific types of visual information that can be reliably decoded from the EEG signals. Further research is needed to understand the types of visual features and semantic concepts that can be effectively extracted from the brain activity recordings.
The biological plausibility analysis, while informative, could be expanded to include a deeper exploration of the underlying neural mechanisms and their relationship to the observed EEG patterns. Incorporating more neuroscientific insights could strengthen the theoretical foundations of the approach.
Finally, the paper does not address potential issues related to individual differences in brain activity or the generalizability of the framework to diverse populations. Addressing these concerns could enhance the practical applicability of the proposed methods.
Overall, the paper presents an exciting step forward in the field of neural decoding and brain-computer interfaces. However, continued research and refinement will be necessary to fully realize the potential of using EEG signals for image representation learning and other real-world applications.
Conclusion
This paper demonstrates the feasibility of learning image representations from electroencephalography (EEG) signals, a non-invasive brain activity recording technique. The researchers developed a self-supervised framework that aligns features extracted from images and their corresponding EEG responses, enabling significantly above-chance performance on a challenging object recognition task.
The findings provide valuable insights into the potential of using EEG signals for neural decoding and brain-computer interfaces, with possible applications in assistive technology and brain-controlled devices. The paper's exploration of the biological plausibility of the approach, including the analysis of temporal, spatial, and spectral aspects of the EEG signals, offers a deeper understanding of the underlying neural mechanisms.
While the current performance is promising, further research is needed to improve the accuracy and generalizability of the framework, as well as to address the potential limitations and caveats identified in the critical analysis. Nonetheless, this work represents an important step forward in the field of visual decoding and reconstruction using EEG-based embeddings, paving the way for enhanced Alzheimer's disease detection using PSG signals and other innovative applications of brain-computer interfaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Quanying Liu
0
0
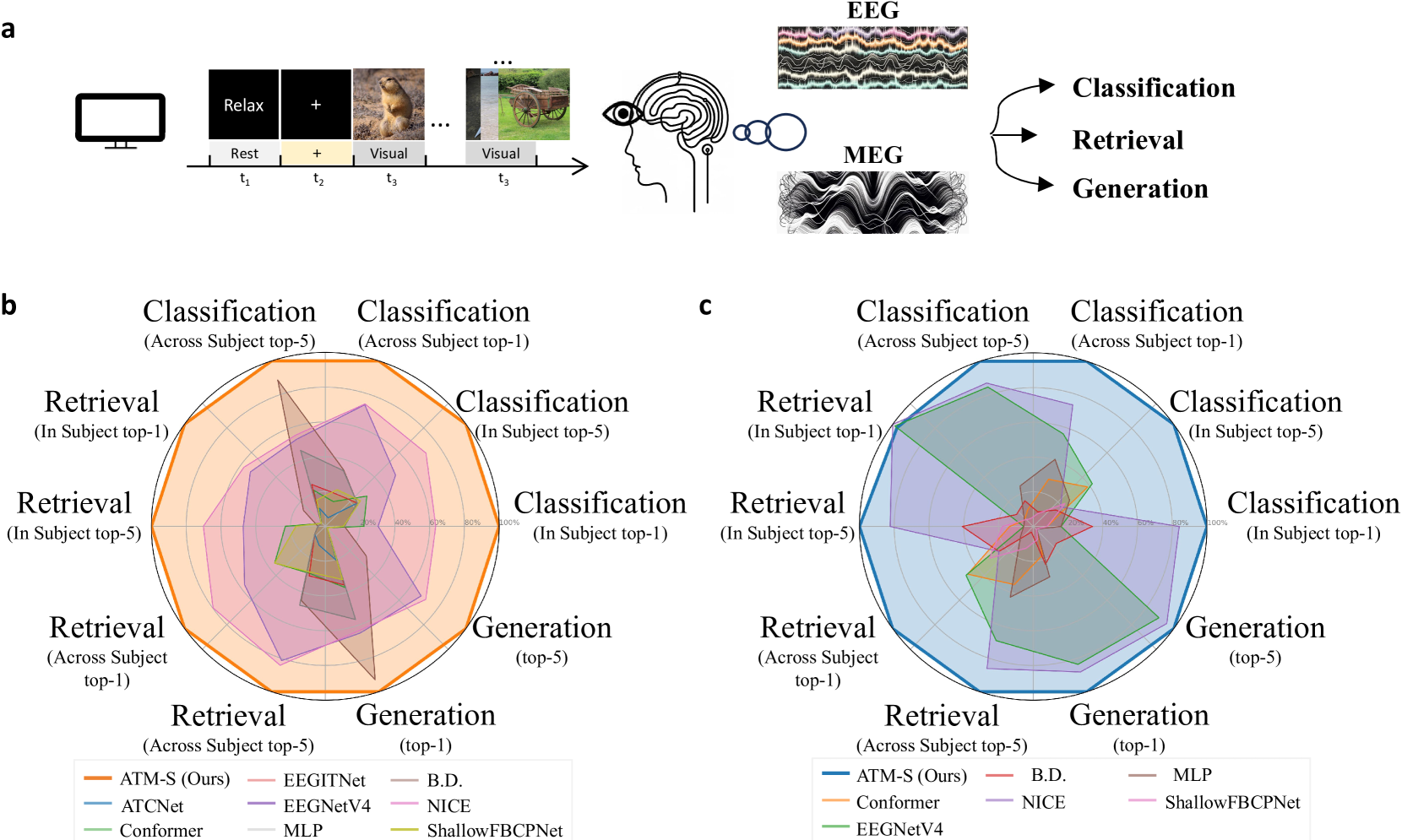
How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
4/8/2024
Mind's Eye: Image Recognition by EEG via Multimodal Similarity-Keeping Contrastive Learning
Chi-Sheng Chen, Chun-Shu Wei
0
0
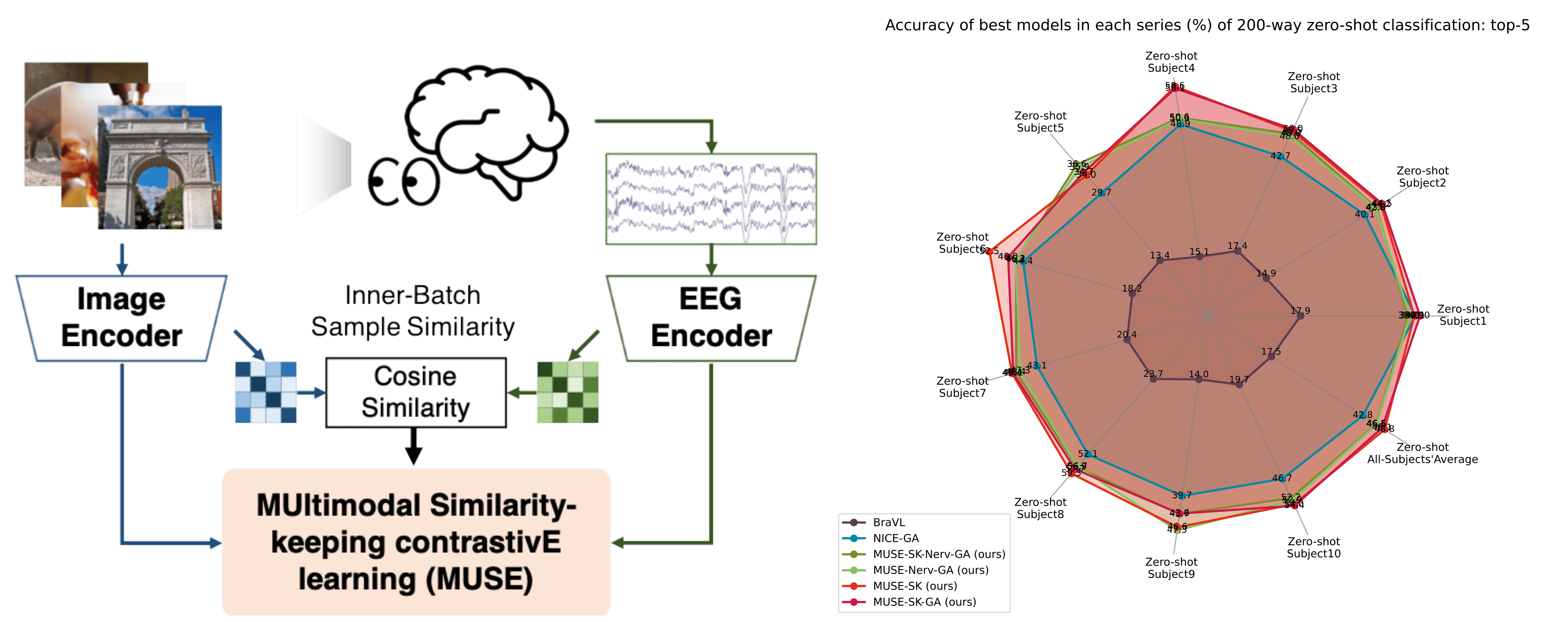
Decoding images from non-invasive electroencephalographic (EEG) signals has been a grand challenge in understanding how the human brain process visual information in real-world scenarios. To cope with the issues of signal-to-noise ratio and nonstationarity, this paper introduces a MUltimodal Similarity-keeping contrastivE learning (MUSE) framework for zero-shot EEG-based image classification. We develop a series of multivariate time-series encoders tailored for EEG signals and assess the efficacy of regularized contrastive EEG-Image pretraining using an extensive visual EEG dataset. Our method achieves state-of-the-art performance, with a top-1 accuracy of 19.3% and a top-5 accuracy of 48.8% in 200-way zero-shot image classification. Furthermore, we visualize neural patterns via model interpretation, shedding light on the visual processing dynamics in the human brain. The code repository for this work is available at: https://github.com/ChiShengChen/MUSE_EEG.
6/26/2024

EEG-ImageNet: An Electroencephalogram Dataset and Benchmarks with Image Visual Stimuli of Multi-Granularity Labels
Shuqi Zhu, Ziyi Ye, Qingyao Ai, Yiqun Liu
0
0
Identifying and reconstructing what we see from brain activity gives us a special insight into investigating how the biological visual system represents the world. While recent efforts have achieved high-performance image classification and high-quality image reconstruction from brain signals collected by Functional Magnetic Resonance Imaging (fMRI) or magnetoencephalogram (MEG), the expensiveness and bulkiness of these devices make relevant applications difficult to generalize to practical applications. On the other hand, Electroencephalography (EEG), despite its advantages of ease of use, cost-efficiency, high temporal resolution, and non-invasive nature, has not been fully explored in relevant studies due to the lack of comprehensive datasets. To address this gap, we introduce EEG-ImageNet, a novel EEG dataset comprising recordings from 16 subjects exposed to 4000 images selected from the ImageNet dataset. EEG-ImageNet consists of 5 times EEG-image pairs larger than existing similar EEG benchmarks. EEG-ImageNet is collected with image stimuli of multi-granularity labels, i.e., 40 images with coarse-grained labels and 40 with fine-grained labels. Based on it, we establish benchmarks for object classification and image reconstruction. Experiments with several commonly used models show that the best models can achieve object classification with accuracy around 60% and image reconstruction with two-way identification around 64%. These results demonstrate the dataset's potential to advance EEG-based visual brain-computer interfaces, understand the visual perception of biological systems, and provide potential applications in improving machine visual models.
6/12/2024
🖼️
Enhancing EEG-to-Text Decoding through Transferable Representations from Pre-trained Contrastive EEG-Text Masked Autoencoder
Jiaqi Wang, Zhenxi Song, Zhengyu Ma, Xipeng Qiu, Min Zhang, Zhiguo Zhang
0
0
Reconstructing natural language from non-invasive electroencephalography (EEG) holds great promise as a language decoding technology for brain-computer interfaces (BCIs). However, EEG-based language decoding is still in its nascent stages, facing several technical issues such as: 1) Absence of a hybrid strategy that can effectively integrate cross-modality (between EEG and text) self-learning with intra-modality self-reconstruction of EEG features or textual sequences; 2) Under-utilization of large language models (LLMs) to enhance EEG-based language decoding. To address above issues, we propose the Contrastive EEG-Text Masked Autoencoder (CET-MAE), a novel model that orchestrates compound self-supervised learning across and within EEG and text through a dedicated multi-stream encoder. Furthermore, we develop a framework called E2T-PTR (EEG-to-Text decoding using Pretrained Transferable Representations), which leverages pre-trained modules alongside the EEG stream from CET-MAE and further enables an LLM (specifically BART) to decode text from EEG sequences. Comprehensive experiments conducted on the popular text-evoked EEG database, ZuCo, demonstrate the superiority of E2T-PTR, which outperforms the state-of-the-art in ROUGE-1 F1 and BLEU-4 scores by 8.34% and 32.21%, respectively. These results indicate significant advancements in the field and underscores the proposed framework's potential to enable more powerful and widespread BCI applications.
6/11/2024