EditScribe: Non-Visual Image Editing with Natural Language Verification Loops

0

Sign in to get full access
Overview
- Proposes a system called EditScribe that enables non-visual image editing using natural language verification loops
- Designed to support accessibility for users with visual impairments or low vision
- Uses generative AI models to enable blind and low-vision users to author and edit visual content
Plain English Explanation
EditScribe: Non-Visual Image Editing with Natural Language Verification Loops introduces a novel approach to make image editing accessible for users with visual impairments. The key idea is to enable these users to author and manipulate visual content through natural language interactions, rather than relying on visual cues.
At the core of the system is a generative AI model that can understand textual descriptions of images and make corresponding edits. Users describe the changes they want to make, and the system updates the image accordingly. Crucially, there is a "verification loop" where the system describes the updated image, and the user can confirm whether it matches their intent. This back-and-forth allows visually impaired users to iteratively refine the image until they are satisfied.
The researchers developed EditScribe to expand accessibility and empower creativity for users who may have traditionally been excluded from visual authoring tools. By enabling non-visual image editing, the system opens up new possibilities for blind and low-vision individuals to express themselves through visual media.
Technical Explanation
EditScribe: Non-Visual Image Editing with Natural Language Verification Loops presents a novel system for enabling non-visual image editing using natural language interactions. The core idea is to leverage generative AI models to allow users to describe desired changes to an image, and then have the system update the image accordingly.
The system architecture consists of several key components:
- A language model that can understand textual descriptions of images and generate natural language responses
- A vision-language model that can translate between textual descriptions and visual representations
- An image editing model that can make targeted changes to images based on textual instructions
Users interact with the system by providing a natural language description of the changes they want to make to an image. The language model processes this input, and the vision-language model translates it into visual updates. The edited image is then passed through the language model again, which generates a textual description of the updated image. This description is presented to the user, who can then confirm whether it matches their intended changes. This verification loop continues until the user is satisfied with the result.
The researchers evaluated EditScribe through a series of user studies, demonstrating its effectiveness in enabling non-visual image editing and its potential to expand accessibility and creative expression for users with visual impairments.
Critical Analysis
The EditScribe paper presents a novel and promising approach to making image editing accessible for users with visual impairments. The key strength of the system is its ability to enable non-visual interactions through natural language, which is a more intuitive and inclusive interface compared to traditional visual-centric tools.
One potential limitation is the accuracy and reliability of the underlying AI models, particularly the vision-language translation and image editing components. While the authors report promising results, these models may not always perform flawlessly, which could lead to frustration or unexpected outcomes for users. Ongoing research and refinement of these technologies will be crucial for ensuring a seamless and reliable user experience.
Additionally, the paper does not address the broader implications of such a system, such as potential biases in the language or vision models, or the ethical considerations around the use of generative AI for content creation. These are important issues that warrant further exploration and discussion.
Overall, EditScribe represents an exciting step forward in expanding accessibility and creative possibilities for users with visual impairments. However, continued research, development, and consideration of the broader implications will be essential to fully realize the potential of this approach.
Conclusion
EditScribe: Non-Visual Image Editing with Natural Language Verification Loops introduces a novel system that enables users with visual impairments to author and edit visual content through natural language interactions. By leveraging generative AI models, the system allows blind and low-vision individuals to describe the changes they want to make to an image, and then iteratively refine the result through a verification loop.
This work represents an important step towards making visual authoring tools more accessible and inclusive. By empowering users with visual impairments to express themselves through visual media, EditScribe has the potential to unlock new creative possibilities and foster greater participation in visual arts and communication. As the underlying technologies continue to evolve, the impact of such systems could extend far beyond accessibility, influencing the way we all interact with and create visual content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EditScribe: Non-Visual Image Editing with Natural Language Verification Loops
Ruei-Che Chang, Yuxuan Liu, Lotus Zhang, Anhong Guo
Image editing is an iterative process that requires precise visual evaluation and manipulation for the output to match the editing intent. However, current image editing tools do not provide accessible interaction nor sufficient feedback for blind and low vision individuals to achieve this level of control. To address this, we developed EditScribe, a prototype system that makes image editing accessible using natural language verification loops powered by large multimodal models. Using EditScribe, the user first comprehends the image content through initial general and object descriptions, then specifies edit actions using open-ended natural language prompts. EditScribe performs the image edit, and provides four types of verification feedback for the user to verify the performed edit, including a summary of visual changes, AI judgement, and updated general and object descriptions. The user can ask follow-up questions to clarify and probe into the edits or verification feedback, before performing another edit. In a study with ten blind or low-vision users, we found that EditScribe supported participants to perform and verify image edit actions non-visually. We observed different prompting strategies from participants, and their perceptions on the various types of verification feedback. Finally, we discuss the implications of leveraging natural language verification loops to make visual authoring non-visually accessible.
Read more8/14/2024

0
Empowering Visual Creativity: A Vision-Language Assistant to Image Editing Recommendations
Tiancheng Shen, Jun Hao Liew, Long Mai, Lu Qi, Jiashi Feng, Jiaya Jia
Advances in text-based image generation and editing have revolutionized content creation, enabling users to create impressive content from imaginative text prompts. However, existing methods are not designed to work well with the oversimplified prompts that are often encountered in typical scenarios when users start their editing with only vague or abstract purposes in mind. Those scenarios demand elaborate ideation efforts from the users to bridge the gap between such vague starting points and the detailed creative ideas needed to depict the desired results. In this paper, we introduce the task of Image Editing Recommendation (IER). This task aims to automatically generate diverse creative editing instructions from an input image and a simple prompt representing the users' under-specified editing purpose. To this end, we introduce Creativity-Vision Language Assistant~(Creativity-VLA), a multimodal framework designed specifically for edit-instruction generation. We train Creativity-VLA on our edit-instruction dataset specifically curated for IER. We further enhance our model with a novel 'token-for-localization' mechanism, enabling it to support both global and local editing operations. Our experimental results demonstrate the effectiveness of ours{} in suggesting instructions that not only contain engaging creative elements but also maintain high relevance to both the input image and the user's initial hint.
Read more6/4/2024
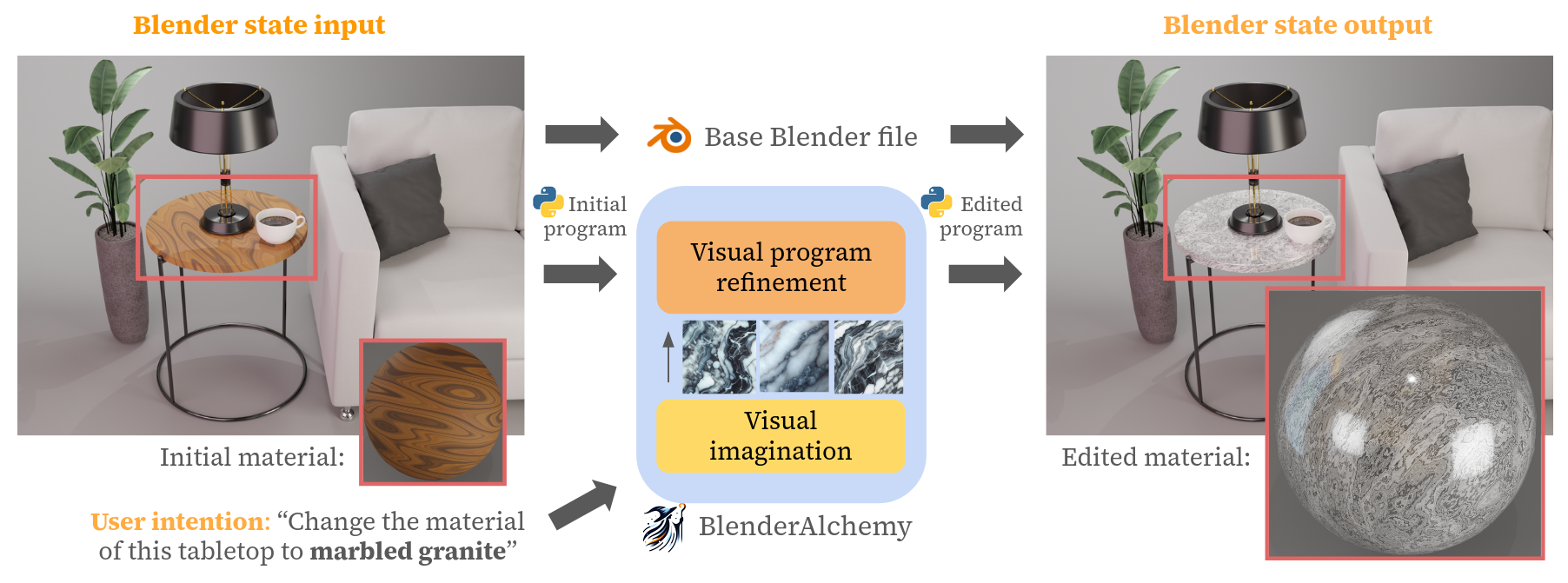
1
BlenderAlchemy: Editing 3D Graphics with Vision-Language Models
Ian Huang, Guandao Yang, Leonidas Guibas
Graphics design is important for various applications, including movie production and game design. To create a high-quality scene, designers usually need to spend hours in software like Blender, in which they might need to interleave and repeat operations, such as connecting material nodes, hundreds of times. Moreover, slightly different design goals may require completely different sequences, making automation difficult. In this paper, we propose a system that leverages Vision-Language Models (VLMs), like GPT-4V, to intelligently search the design action space to arrive at an answer that can satisfy a user's intent. Specifically, we design a vision-based edit generator and state evaluator to work together to find the correct sequence of actions to achieve the goal. Inspired by the role of visual imagination in the human design process, we supplement the visual reasoning capabilities of VLMs with imagined reference images from image-generation models, providing visual grounding of abstract language descriptions. In this paper, we provide empirical evidence suggesting our system can produce simple but tedious Blender editing sequences for tasks such as editing procedural materials from text and/or reference images, as well as adjusting lighting configurations for product renderings in complex scenes.
Read more5/24/2024

0
WorldScribe: Towards Context-Aware Live Visual Descriptions
Ruei-Che Chang, Yuxuan Liu, Anhong Guo
Automated live visual descriptions can aid blind people in understanding their surroundings with autonomy and independence. However, providing descriptions that are rich, contextual, and just-in-time has been a long-standing challenge in accessibility. In this work, we develop WorldScribe, a system that generates automated live real-world visual descriptions that are customizable and adaptive to users' contexts: (i) WorldScribe's descriptions are tailored to users' intents and prioritized based on semantic relevance. (ii) WorldScribe is adaptive to visual contexts, e.g., providing consecutively succinct descriptions for dynamic scenes, while presenting longer and detailed ones for stable settings. (iii) WorldScribe is adaptive to sound contexts, e.g., increasing volume in noisy environments, or pausing when conversations start. Powered by a suite of vision, language, and sound recognition models, WorldScribe introduces a description generation pipeline that balances the tradeoffs between their richness and latency to support real-time use. The design of WorldScribe is informed by prior work on providing visual descriptions and a formative study with blind participants. Our user study and subsequent pipeline evaluation show that WorldScribe can provide real-time and fairly accurate visual descriptions to facilitate environment understanding that is adaptive and customized to users' contexts. Finally, we discuss the implications and further steps toward making live visual descriptions more context-aware and humanized.
Read more8/14/2024