Effective Adapter for Face Recognition in the Wild
2312.01734
0
0
👁️
Abstract
In this paper, we tackle the challenge of face recognition in the wild, where images often suffer from low quality and real-world distortions. Traditional heuristic approaches-either training models directly on these degraded images or their enhanced counterparts using face restoration techniques-have proven ineffective, primarily due to the degradation of facial features and the discrepancy in image domains. To overcome these issues, we propose an effective adapter for augmenting existing face recognition models trained on high-quality facial datasets. The key of our adapter is to process both the unrefined and enhanced images using two similar structures, one fixed and the other trainable. Such design can confer two benefits. First, the dual-input system minimizes the domain gap while providing varied perspectives for the face recognition model, where the enhanced image can be regarded as a complex non-linear transformation of the original one by the restoration model. Second, both two similar structures can be initialized by the pre-trained models without dropping the past knowledge. The extensive experiments in zero-shot settings show the effectiveness of our method by surpassing baselines of about 3%, 4%, and 7% in three datasets. Our code will be publicly available.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Tackles the challenge of face recognition in the wild, where images often suffer from low quality and real-world distortions
- Traditional approaches of training models directly on degraded images or using face restoration techniques have proven ineffective
- Proposes an effective adapter for augmenting existing face recognition models trained on high-quality facial datasets
Plain English Explanation
The paper addresses the problem of face recognition in real-world situations where the images used may be of low quality or distorted. Traditional methods, such as training models directly on these low-quality images or enhancing them using face restoration techniques, have not been effective. This is mainly due to the degradation of facial features and the differences between the enhanced images and the original ones.
To overcome these issues, the paper introduces an adapter that can be used to improve existing face recognition models that were trained on high-quality facial datasets. The key idea is to process both the original low-quality images and the enhanced versions using two similar structures, one fixed and the other trainable.
This dual-input system has two main benefits. First, it helps minimize the gap between the original and enhanced images, as the enhanced version can be seen as a complex non-linear transformation of the original by the restoration model. Second, both the fixed and trainable structures can be initialized using pre-trained models, allowing the system to retain the knowledge learned from the high-quality datasets.
The experiments show that this approach outperforms the baselines by a significant margin (around 3%, 4%, and 7% in three different datasets) in a zero-shot setting, where the model is tested on images it has not seen during training.
Technical Explanation
The paper proposes an adapter that can be used to augment existing face recognition models trained on high-quality facial datasets. The key idea is to process both the original low-quality images and the enhanced versions using two similar structures, one fixed and the other trainable.
The fixed structure is initialized using a pre-trained face recognition model, while the trainable structure is initialized using a pre-trained image restoration model that can enhance the low-quality images. The outputs of these two structures are then concatenated and fed into a final face recognition module.
This dual-input system has several advantages. First, it helps minimize the domain gap between the original and enhanced images, as the enhanced version can be seen as a complex non-linear transformation of the original by the restoration model. Second, both the fixed and trainable structures can be initialized using pre-trained models, allowing the system to retain the knowledge learned from the high-quality datasets.
The extensive experiments in a zero-shot setting show that this approach outperforms the baselines by a significant margin (around 3%, 4%, and 7% in three different datasets). The authors also mention that their code will be publicly available.
Critical Analysis
The paper presents a novel and promising approach to address the challenge of face recognition in the wild. The use of a dual-input system that processes both the original low-quality images and their enhanced counterparts is an interesting solution to the domain gap issue.
However, the paper does not provide much detail on the specific image restoration model used or its performance characteristics. Additionally, the paper does not explore the potential limitations of this approach, such as the computational overhead of running two separate models or the impact of the restoration model's own errors on the final face recognition performance.
It would also be valuable to see how this approach compares to more recent diffusion-based or dynamic pre-training techniques for improving face recognition in the wild. A more in-depth discussion of the potential real-world implications and limitations of the proposed method would help readers evaluate its overall significance and potential for further development.
Conclusion
This paper presents an effective adapter for augmenting existing face recognition models to improve their performance on low-quality and distorted images in the wild. By processing both the original and enhanced images using a dual-input system, the method helps to minimize the domain gap and leverage the knowledge from pre-trained models.
The extensive experiments demonstrate the effectiveness of this approach, outperforming the baselines by a significant margin in zero-shot settings. While the paper could benefit from more detailed analysis and comparisons to other state-of-the-art methods, the proposed adapter represents a promising step forward in addressing the challenge of face recognition in real-world, unconstrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Face2Face: Label-driven Facial Retouching Restoration
Guanhua Zhao, Yu Gu, Xuhan Sheng, Yujie Hu, Jian Zhang
0
0
With the popularity of social media platforms such as Instagram and TikTok, and the widespread availability and convenience of retouching tools, an increasing number of individuals are utilizing these tools to beautify their facial photographs. This poses challenges for fields that place high demands on the authenticity of photographs, such as identity verification and social media. By altering facial images, users can easily create deceptive images, leading to the dissemination of false information. This may pose challenges to the reliability of identity verification systems and social media, and even lead to online fraud. To address this issue, some work has proposed makeup removal methods, but they still lack the ability to restore images involving geometric deformations caused by retouching. To tackle the problem of facial retouching restoration, we propose a framework, dubbed Face2Face, which consists of three components: a facial retouching detector, an image restoration model named FaceR, and a color correction module called Hierarchical Adaptive Instance Normalization (H-AdaIN). Firstly, the facial retouching detector predicts a retouching label containing three integers, indicating the retouching methods and their corresponding degrees. Then FaceR restores the retouched image based on the predicted retouching label. Finally, H-AdaIN is applied to address the issue of color shift arising from diffusion models. Extensive experiments demonstrate the effectiveness of our framework and each module.
4/23/2024
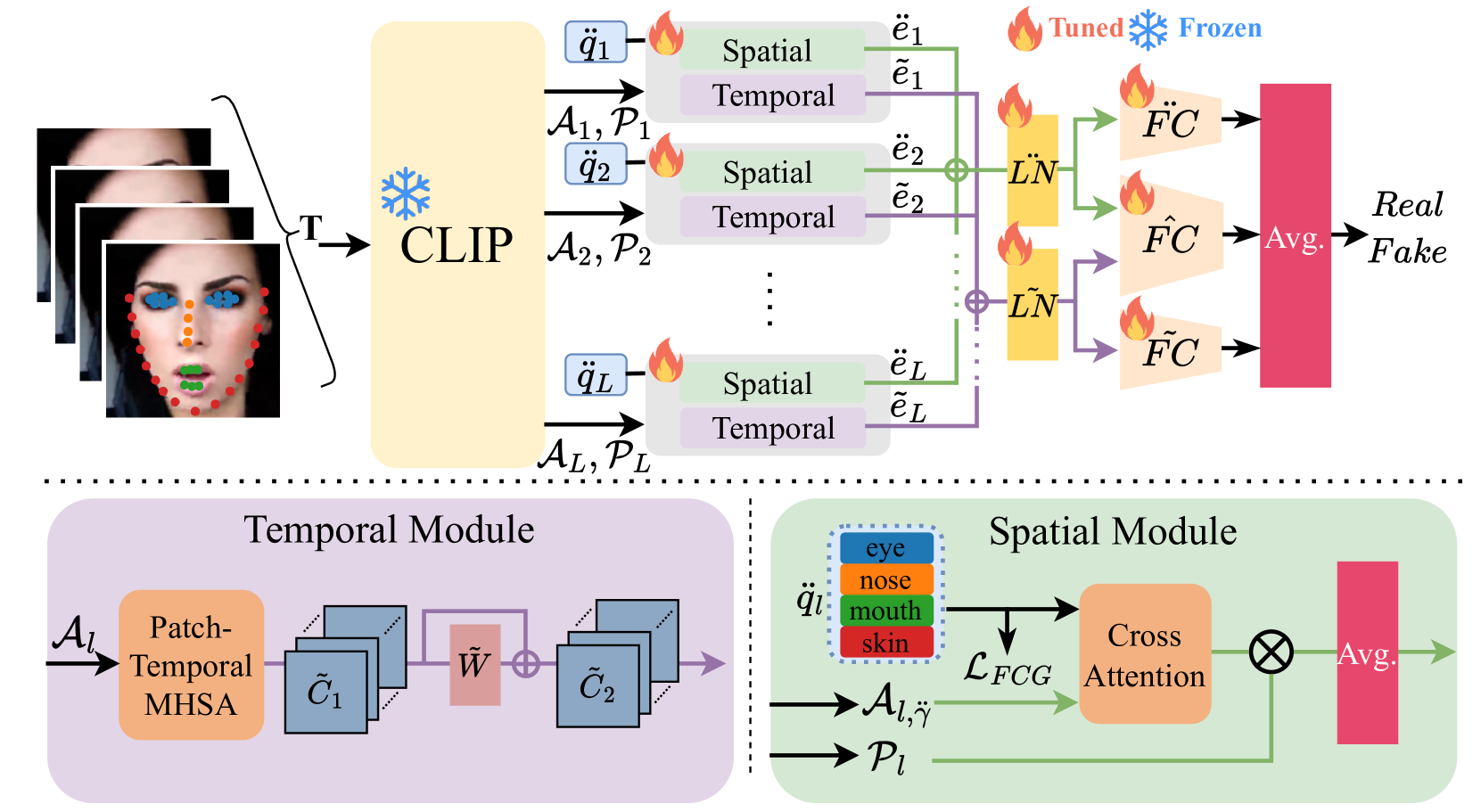
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
0
0
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting rich information encoded inside the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to guidencourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvementsuccess even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especiallytablishing a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
4/9/2024
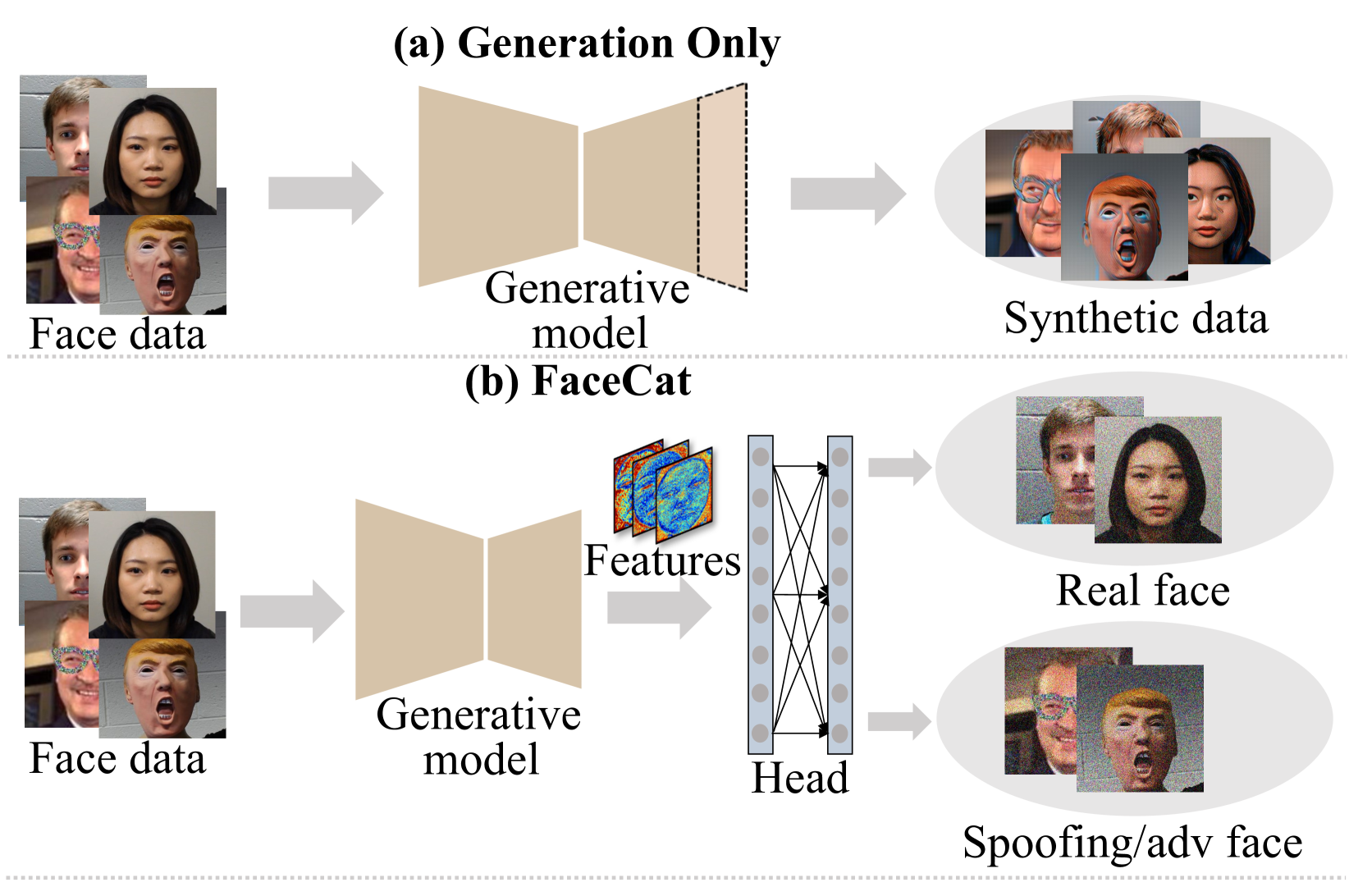
FaceCat: Enhancing Face Recognition Security with a Unified Generative Model Framework
Jiawei Chen, Xiao Yang, Yinpeng Dong, Hang Su, Jianteng Peng, Zhaoxia Yin
0
0
Face anti-spoofing (FAS) and adversarial detection (FAD) have been regarded as critical technologies to ensure the safety of face recognition systems. As a consequence of their limited practicality and generalization, some existing methods aim to devise a framework capable of concurrently detecting both threats to address the challenge. Nevertheless, these methods still encounter challenges of insufficient generalization and suboptimal robustness, potentially owing to the inherent drawback of discriminative models. Motivated by the rich structural and detailed features of face generative models, we propose FaceCat which utilizes the face generative model as a pre-trained model to improve the performance of FAS and FAD. Specifically, FaceCat elaborately designs a hierarchical fusion mechanism to capture rich face semantic features of the generative model. These features then serve as a robust foundation for a lightweight head, designed to execute FAS and FAD tasks simultaneously. As relying solely on single-modality data often leads to suboptimal performance, we further propose a novel text-guided multi-modal alignment strategy that utilizes text prompts to enrich feature representation, thereby enhancing performance. For fair evaluations, we build a comprehensive protocol with a wide range of 28 attack types to benchmark the performance. Extensive experiments validate the effectiveness of FaceCat generalizes significantly better and obtains excellent robustness against input transformations.
4/16/2024

CAT: Contrastive Adapter Training for Personalized Image Generation
Jae Wan Park, Sang Hyun Park, Jun Young Koh, Junha Lee, Min Song
0
0
The emergence of various adapters, including Low-Rank Adaptation (LoRA) applied from the field of natural language processing, has allowed diffusion models to personalize image generation at a low cost. However, due to the various challenges including limited datasets and shortage of regularization and computation resources, adapter training often results in unsatisfactory outcomes, leading to the corruption of the backbone model's prior knowledge. One of the well known phenomena is the loss of diversity in object generation, especially within the same class which leads to generating almost identical objects with minor variations. This poses challenges in generation capabilities. To solve this issue, we present Contrastive Adapter Training (CAT), a simple yet effective strategy to enhance adapter training through the application of CAT loss. Our approach facilitates the preservation of the base model's original knowledge when the model initiates adapters. Furthermore, we introduce the Knowledge Preservation Score (KPS) to evaluate CAT's ability to keep the former information. We qualitatively and quantitatively compare CAT's improvement. Finally, we mention the possibility of CAT in the aspects of multi-concept adapter and optimization.
4/12/2024