Dynamic Pre-training: Towards Efficient and Scalable All-in-One Image Restoration
2404.02154
0
1
Abstract
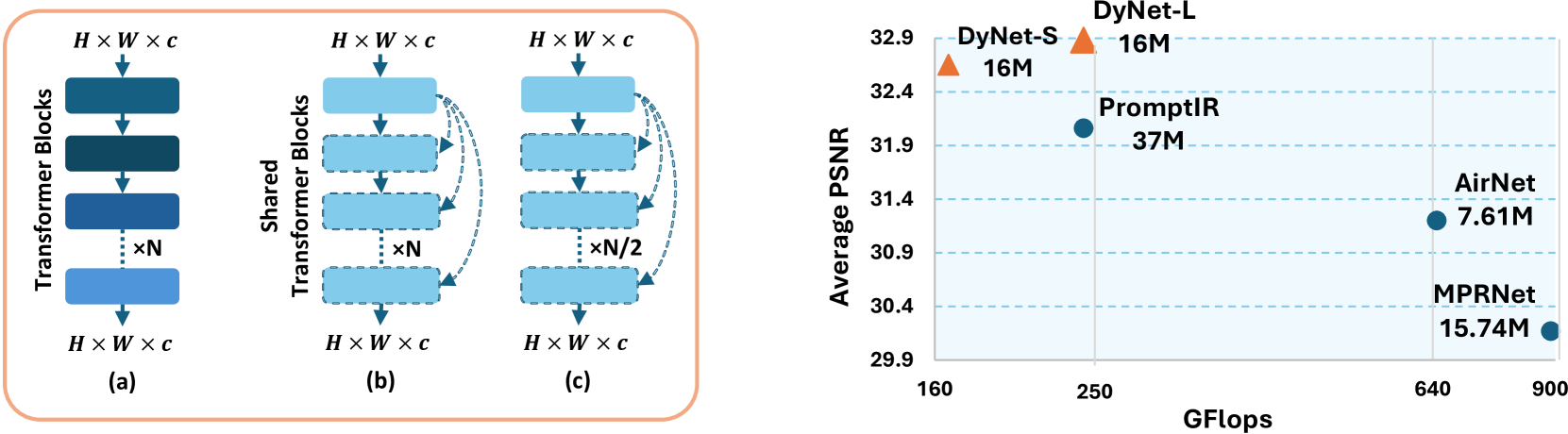
All-in-one image restoration tackles different types of degradations with a unified model instead of having task-specific, non-generic models for each degradation. The requirement to tackle multiple degradations using the same model can lead to high-complexity designs with fixed configuration that lack the adaptability to more efficient alternatives. We propose DyNet, a dynamic family of networks designed in an encoder-decoder style for all-in-one image restoration tasks. Our DyNet can seamlessly switch between its bulkier and lightweight variants, thereby offering flexibility for efficient model deployment with a single round of training. This seamless switching is enabled by our weights-sharing mechanism, forming the core of our architecture and facilitating the reuse of initialized module weights. Further, to establish robust weights initialization, we introduce a dynamic pre-training strategy that trains variants of the proposed DyNet concurrently, thereby achieving a 50% reduction in GPU hours. To tackle the unavailability of large-scale dataset required in pre-training, we curate a high-quality, high-resolution image dataset named Million-IRD having 2M image samples. We validate our DyNet for image denoising, deraining, and dehazing in all-in-one setting, achieving state-of-the-art results with 31.34% reduction in GFlops and a 56.75% reduction in parameters compared to baseline models. The source codes and trained models are available at https://github.com/akshaydudhane16/DyNet.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel approach called "Dynamic Pre-training" for efficient and scalable all-in-one image restoration.
- The core idea is to train a single model that can handle multiple image restoration tasks, rather than using separate models for each task.
- The authors demonstrate that their approach outperforms state-of-the-art methods across a range of image restoration benchmarks.
Plain English Explanation
The paper introduces a new technique called "Dynamic Pre-training" that aims to make image restoration more efficient and practical. Image restoration is the process of improving the quality of degraded or corrupted images, such as removing noise, enhancing resolution, or fixing other issues.
Traditionally, researchers have developed separate models for each type of image restoration task, like denoising or super-resolution. This can be time-consuming and resource-intensive, as it requires training and maintaining many different models.
The key insight of the Dynamic Pre-training approach is to train a single, versatile model that can handle multiple image restoration tasks. This "all-in-one" model is pre-trained on a diverse dataset of corrupted and cleaned image pairs, which allows it to learn the underlying principles of image restoration.
When applying the model to a specific task, such as deblurring or inpainting, the authors show that it can quickly adapt and achieve state-of-the-art performance, without requiring extensive task-specific fine-tuning. This makes the model more efficient and scalable compared to traditional approaches.
The authors demonstrate the effectiveness of their Dynamic Pre-training technique on a range of image restoration benchmarks, showing that it outperforms existing methods. This suggests that their approach could be a valuable tool for efficiently improving image quality in various real-world applications.
Technical Explanation
The paper introduces a novel "Dynamic Pre-training" framework for efficient and scalable all-in-one image restoration. The core idea is to train a single model that can handle multiple image restoration tasks, rather than using separate models for each task.
The authors first pre-train their model on a diverse dataset of corrupted and cleaned image pairs, covering a wide range of degradation types and restoration tasks. This pre-training phase allows the model to learn the underlying principles of image restoration in a task-agnostic manner.
When applying the model to a specific restoration task, the authors use a "dynamic adaptation" mechanism that quickly adapts the pre-trained model to the target task. This adaptation involves a lightweight fine-tuning process that updates a small number of task-specific parameters, without modifying the core model weights.
The authors evaluate their Dynamic Pre-training approach on various image restoration benchmarks, including denoising, super-resolution, deblurring, and inpainting. They demonstrate that their all-in-one model outperforms state-of-the-art task-specific models across these tasks, while requiring significantly less training time and computational resources.
Critical Analysis
The paper presents a compelling approach to address the challenges of efficiency and scalability in image restoration. By training a single, versatile model that can adapt to multiple tasks, the authors show how to reduce the development and maintenance costs associated with traditional task-specific models.
However, the paper does not delve into the potential limitations or caveats of their Dynamic Pre-training framework. For example, it is unclear how the model's performance scales as the number of restoration tasks increases, or how it handles tasks that may require more specialized architectures or training regimes.
Additionally, the authors' experiments focus on relatively standard image restoration benchmarks, but it would be valuable to understand the model's performance on more real-world, noisy, and diverse image data. Further research could explore the model's robustness and generalization capabilities in more challenging scenarios.
Nevertheless, the paper's core contribution of an efficient and scalable all-in-one image restoration model is a promising step forward in the field. By reducing the complexity and resource requirements of image restoration systems, the Dynamic Pre-training approach could have significant practical implications for a wide range of applications, from computational photography to medical imaging.
Conclusion
The paper presents a novel "Dynamic Pre-training" framework that enables efficient and scalable all-in-one image restoration. By training a single model that can adapt to multiple restoration tasks, the authors demonstrate a significant improvement in performance and resource efficiency compared to traditional task-specific models.
The authors' approach has the potential to streamline the development and deployment of image restoration systems, making them more accessible and practical for real-world applications. While the paper does not address all possible limitations, the core ideas and results suggest that Dynamic Pre-training could be a valuable contribution to the field of image restoration and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CRNet: A Detail-Preserving Network for Unified Image Restoration and Enhancement Task
Kangzhen Yang, Tao Hu, Kexin Dai, Genggeng Chen, Yu Cao, Wei Dong, Peng Wu, Yanning Zhang, Qingsen Yan
0
0
In real-world scenarios, images captured often suffer from blurring, noise, and other forms of image degradation, and due to sensor limitations, people usually can only obtain low dynamic range images. To achieve high-quality images, researchers have attempted various image restoration and enhancement operations on photographs, including denoising, deblurring, and high dynamic range imaging. However, merely performing a single type of image enhancement still cannot yield satisfactory images. In this paper, to deal with the challenge above, we propose the Composite Refinement Network (CRNet) to address this issue using multiple exposure images. By fully integrating information-rich multiple exposure inputs, CRNet can perform unified image restoration and enhancement. To improve the quality of image details, CRNet explicitly separates and strengthens high and low-frequency information through pooling layers, using specially designed Multi-Branch Blocks for effective fusion of these frequencies. To increase the receptive field and fully integrate input features, CRNet employs the High-Frequency Enhancement Module, which includes large kernel convolutions and an inverted bottleneck ConvFFN. Our model secured third place in the first track of the Bracketing Image Restoration and Enhancement Challenge, surpassing previous SOTA models in both testing metrics and visual quality.
4/23/2024
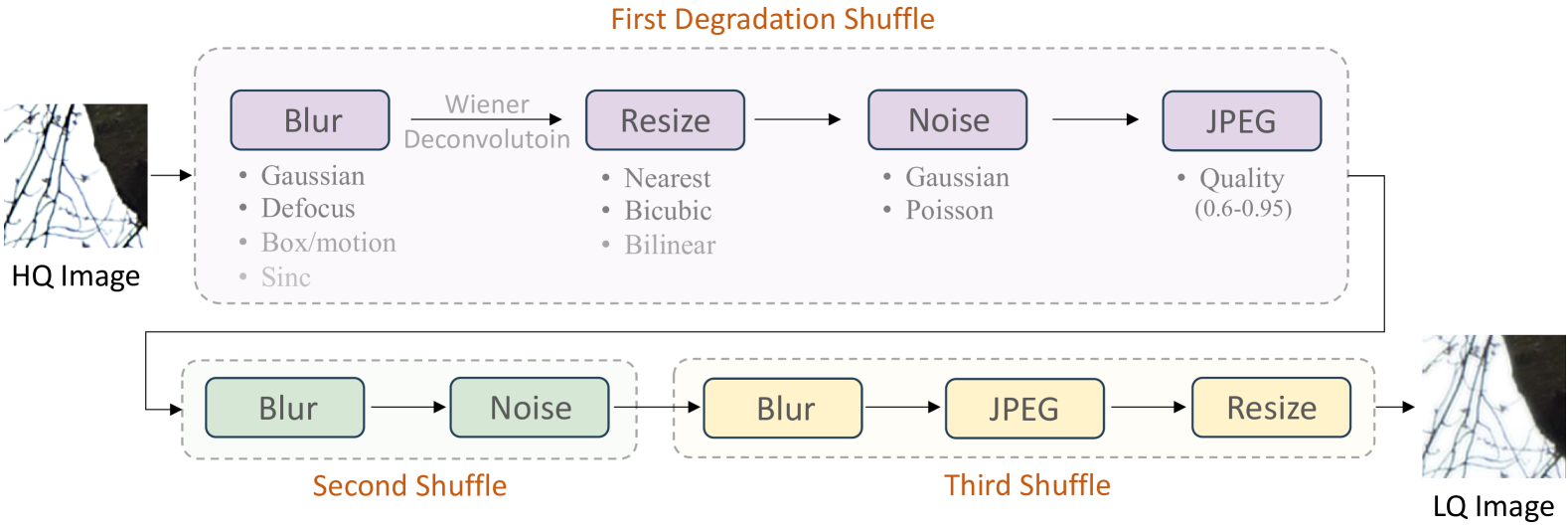
Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sjolund, Thomas B. Schon
0
0
Though diffusion models have been successfully applied to various image restoration (IR) tasks, their performance is sensitive to the choice of training datasets. Typically, diffusion models trained in specific datasets fail to recover images that have out-of-distribution degradations. To address this problem, this work leverages a capable vision-language model and a synthetic degradation pipeline to learn image restoration in the wild (wild IR). More specifically, all low-quality images are simulated with a synthetic degradation pipeline that contains multiple common degradations such as blur, resize, noise, and JPEG compression. Then we introduce robust training for a degradation-aware CLIP model to extract enriched image content features to assist high-quality image restoration. Our base diffusion model is the image restoration SDE (IR-SDE). Built upon it, we further present a posterior sampling strategy for fast noise-free image generation. We evaluate our model on both synthetic and real-world degradation datasets. Moreover, experiments on the unified image restoration task illustrate that the proposed posterior sampling improves image generation quality for various degradations.
4/16/2024
Empowering Image Recovery_ A Multi-Attention Approach
Juan Wen, Yawei Li, Chao Zhang, Weiyan Hou, Radu Timofte, Luc Van Gool
0
0
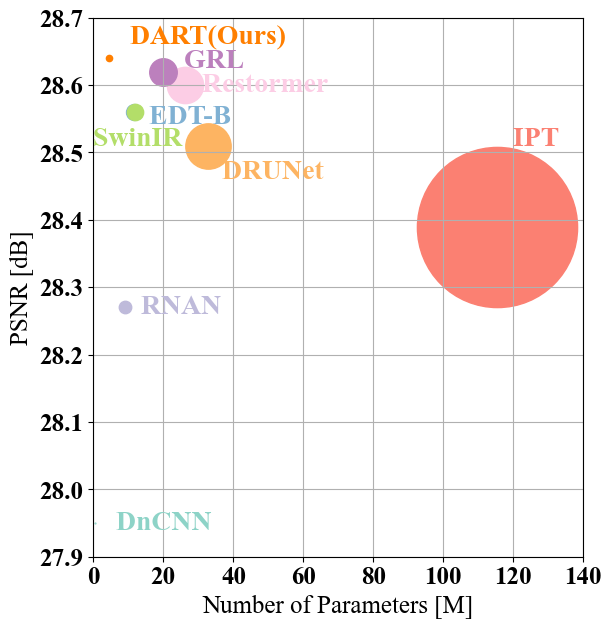
We propose Diverse Restormer (DART), a novel image restoration method that effectively integrates information from various sources (long sequences, local and global regions, feature dimensions, and positional dimensions) to address restoration challenges. While Transformer models have demonstrated excellent performance in image restoration due to their self-attention mechanism, they face limitations in complex scenarios. Leveraging recent advancements in Transformers and various attention mechanisms, our method utilizes customized attention mechanisms to enhance overall performance. DART, our novel network architecture, employs windowed attention to mimic the selective focusing mechanism of human eyes. By dynamically adjusting receptive fields, it optimally captures the fundamental features crucial for image resolution reconstruction. Efficiency and performance balance are achieved through the LongIR attention mechanism for long sequence image restoration. Integration of attention mechanisms across feature and positional dimensions further enhances the recovery of fine details. Evaluation across five restoration tasks consistently positions DART at the forefront. Upon acceptance, we commit to providing publicly accessible code and models to ensure reproducibility and facilitate further research.
4/10/2024
One-Shot Image Restoration
Deborah Pereg
0
0
Image restoration, or inverse problems in image processing, has long been an extensively studied topic. In recent years supervised learning approaches have become a popular strategy attempting to tackle this task. Unfortunately, most supervised learning-based methods are highly demanding in terms of computational resources and training data (sample complexity). In addition, trained models are sensitive to domain changes, such as varying acquisition systems, signal sampling rates, resolution and contrast. In this work, we try to answer a fundamental question: Can supervised learning models generalize well solely by learning from one image or even part of an image? If so, then what is the minimal amount of patches required to achieve acceptable generalization? To this end, we focus on an efficient patch-based learning framework that requires a single image input-output pair for training. Experimental results demonstrate the applicability, robustness and computational efficiency of the proposed approach for supervised image deblurring and super-resolution. Our results showcase significant improvement of learning models' sample efficiency, generalization and time complexity, that can hopefully be leveraged for future real-time applications, and applied to other signals and modalities.
4/29/2024