Effective Adaptive Mutation Rates for Program Synthesis

0
Sign in to get full access
Overview
- This paper investigates the use of adaptive mutation rates in genetic programming for program synthesis tasks.
- The authors propose a new mutation strategy called "Uniform Addition by Mutation and Deletion" (UAMD) that adjusts the mutation rate dynamically based on the performance of different mutation operators.
- They compare UAMD to other mutation strategies, including a fixed mutation rate and an adaptive mutation rate using multi-armed bandits, on a variety of program synthesis benchmarks.
Plain English Explanation
The paper is focused on improving the way genetic programming algorithms, which are inspired by natural evolution, can be used to automatically generate computer programs that solve specific tasks. One key aspect of these algorithms is the mutation process, where small changes are introduced to the programs to explore new possibilities.
The authors recognized that having a fixed mutation rate may not be optimal, as the best rate can vary depending on the problem being solved. So they developed a new approach called "Uniform Addition by Mutation and Deletion" (UAMD) that dynamically adjusts the mutation rate based on how well the different mutation operators are performing.
The idea is that UAMD can better balance exploration (trying new things) and exploitation (sticking with what's working) compared to using a fixed mutation rate or a simpler adaptive approach. The authors tested this on a variety of program synthesis tasks, like generating short programs to solve math problems or control simple robots, and found that UAMD outperformed the other mutation strategies.
Technical Explanation
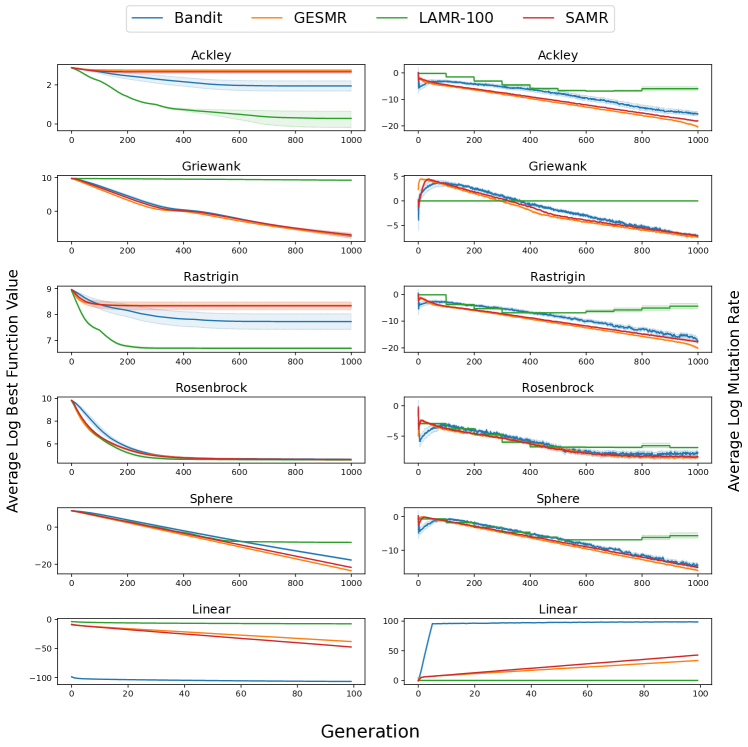
The paper introduces a new mutation strategy called "Uniform Addition by Mutation and Deletion" (UAMD) for use in genetic programming algorithms. UAMD adaptively adjusts the mutation rate during the search process based on the performance of different mutation operators using a multi-armed bandit approach.
Specifically, UAMD maintains a set of mutation operators, each with an associated weight that determines the probability of that operator being selected. The weights are updated using the upper confidence bound (UCB) algorithm, a well-known multi-armed bandit strategy, to allocate more trials to the most successful mutation operators.
In contrast to previous adaptive mutation approaches that focused on adjusting the overall mutation rate, UAMD independently adjusts the probabilities of the individual mutation operators. This allows the algorithm to dynamically balance exploration (trying new operators) and exploitation (relying on proven operators) throughout the search.
The authors evaluate UAMD on a diverse set of program synthesis benchmarks, including symbolic regression, robot control, and math problem solving tasks. They compare UAMD to both fixed mutation rate and other adaptive mutation rate approaches, including a simple multi-armed bandit scheme.
The results show that UAMD consistently outperforms the other mutation strategies, demonstrating the benefits of its adaptive and operator-level mutation rate adjustments. The authors provide insights into the behavior of UAMD and discuss the implications of their findings for the design of effective genetic programming systems.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the UAMD mutation strategy, with a strong theoretical foundation and a comprehensive set of experiments. The authors acknowledge several limitations of their work, such as the need to further investigate the performance of UAMD on larger and more complex program synthesis tasks.
One potential concern is the computational overhead associated with maintaining and updating the multi-armed bandit for the different mutation operators. While the authors show that UAMD outperforms the other strategies, the added complexity may limit its practical applicability, especially for resource-constrained environments.
Additionally, the paper does not address potential biases or assumptions in the program synthesis benchmarks used. It would be valuable to explore the robustness of UAMD's performance across a wider range of problem domains and task characteristics.
Further research could also investigate the synergies between UAMD and other genetic programming techniques, such as efficient evolutionary algorithms with dynamic mutation rates, mutation bias learning, or unit-aware genetic programming. Combining these approaches may lead to even more effective program synthesis capabilities.
Conclusion
This paper presents an innovative adaptive mutation strategy called UAMD that dynamically adjusts the probabilities of individual mutation operators in genetic programming algorithms. The authors demonstrate the effectiveness of UAMD on a variety of program synthesis tasks, outperforming both fixed mutation rate and simpler adaptive mutation approaches.
The key insights from this research are the benefits of operator-level adaptation and the ability of UAMD to balance exploration and exploitation during the search process. These findings have important implications for the design of efficient and robust genetic programming systems, which are widely used for automatic program generation, symbolic regression, and other challenging optimization problems.
While the paper highlights some limitations and areas for further investigation, the UAMD approach represents a significant advancement in the field of genetic programming and provides a solid foundation for future work in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Effective Adaptive Mutation Rates for Program Synthesis
Andrew Ni, Lee Spector
The problem-solving performance of many evolutionary algorithms, including genetic programming systems used for program synthesis, depends on the values of hyperparameters including mutation rates. The mutation method used to produce some of the best results to date on software synthesis benchmark problems, Uniform Mutation by Addition and Deletion (UMAD), adds new genes into a genome at a predetermined rate and then deletes genes at a rate that balances the addition rate, producing no size change on average. While UMAD with a predetermined addition rate outperforms many other mutation and crossover schemes, we do not expect a single rate to be optimal across all problems or all generations within one run of an evolutionary system. However, many current adaptive mutation schemes such as self-adaptive mutation rates suffer from pathologies like the vanishing mutation rate problem, in which the mutation rate quickly decays to zero. We propose an adaptive bandit-based scheme that addresses this problem and essentially removes the need to specify a mutation rate. Although the proposed scheme itself introduces hyperparameters, we either set these to good values or ensemble them in a reasonable range. Results on software synthesis and symbolic regression problems validate the effectiveness of our approach.
Read more6/26/2024
🔍
0
A Flexible Evolutionary Algorithm With Dynamic Mutation Rate Archive
Martin S. Krejca, Carsten Witt
We propose a new, flexible approach for dynamically maintaining successful mutation rates in evolutionary algorithms using $k$-bit flip mutations. The algorithm adds successful mutation rates to an archive of promising rates that are favored in subsequent steps. Rates expire when their number of unsuccessful trials has exceeded a threshold, while rates currently not present in the archive can enter it in two ways: (i) via user-defined minimum selection probabilities for rates combined with a successful step or (ii) via a stagnation detection mechanism increasing the value for a promising rate after the current bit-flip neighborhood has been explored with high probability. For the minimum selection probabilities, we suggest different options, including heavy-tailed distributions. We conduct rigorous runtime analysis of the flexible evolutionary algorithm on the OneMax and Jump functions, on general unimodal functions, on minimum spanning trees, and on a class of hurdle-like functions with varying hurdle width that benefit particularly from the archive of promising mutation rates. In all cases, the runtime bounds are close to or even outperform the best known results for both stagnation detection and heavy-tailed mutations.
Read more4/8/2024
📉
0
Mutation-Bias Learning in Games
Johann Bauer, Sheldon West, Eduardo Alonso, Mark Broom
We present two variants of a multi-agent reinforcement learning algorithm based on evolutionary game theoretic considerations. The intentional simplicity of one variant enables us to prove results on its relationship to a system of ordinary differential equations of replicator-mutator dynamics type, allowing us to present proofs on the algorithm's convergence conditions in various settings via its ODE counterpart. The more complicated variant enables comparisons to Q-learning based algorithms. We compare both variants experimentally to WoLF-PHC and frequency-adjusted Q-learning on a range of settings, illustrating cases of increasing dimensionality where our variants preserve convergence in contrast to more complicated algorithms. The availability of analytic results provides a degree of transferability of results as compared to purely empirical case studies, illustrating the general utility of a dynamical systems perspective on multi-agent reinforcement learning when addressing questions of convergence and reliable generalisation.
Read more5/29/2024
↗️
0
The Inefficiency of Genetic Programming for Symbolic Regression -- Extended Version
Gabriel Kronberger, Fabricio Olivetti de Franca, Harry Desmond, Deaglan J. Bartlett, Lukas Kammerer
We analyse the search behaviour of genetic programming for symbolic regression in practically relevant but limited settings, allowing exhaustive enumeration of all solutions. This enables us to quantify the success probability of finding the best possible expressions, and to compare the search efficiency of genetic programming to random search in the space of semantically unique expressions. This analysis is made possible by improved algorithms for equality saturation, which we use to improve the Exhaustive Symbolic Regression algorithm; this produces the set of semantically unique expression structures, orders of magnitude smaller than the full symbolic regression search space. We compare the efficiency of random search in the set of unique expressions and genetic programming. For our experiments we use two real-world datasets where symbolic regression has been used to produce well-fitting univariate expressions: the Nikuradse dataset of flow in rough pipes and the Radial Acceleration Relation of galaxy dynamics. The results show that genetic programming in such limited settings explores only a small fraction of all unique expressions, and evaluates expressions repeatedly that are congruent to already visited expressions.
Read more4/29/2024