Effective and Efficient Conversation Retrieval for Dialogue State Tracking with Implicit Text Summaries

0

Sign in to get full access
Overview
- This paper presents a method for improving dialogue state tracking (DST) by using efficient retrieval of relevant conversation history.
- The authors propose using implicit text summaries of conversation history to enhance the performance of large language models (LLMs) in DST tasks.
- The approach aims to make DST more effective and efficient by selectively retrieving the most relevant past conversations to inform the model's predictions.
Plain English Explanation
The paper focuses on a key challenge in dialogue systems - tracking the state of a conversation over time. As people chat, the context and intent behind their messages can shift, and a dialogue system needs to understand this evolving state to provide helpful and coherent responses.
The authors recognized that large language models, while powerful, can struggle to fully leverage the full history of a conversation when making their predictions. To address this, they developed a method that efficiently retrieves the most relevant past conversations and provides concise summaries of their key points.
By giving the language model access to this distilled conversational history, it is better able to understand the current context and deliver more accurate dialogue state tracking. Imagine you're having a complex discussion, and the AI assistant can quickly recall the important points you've already covered, rather than forcing you to reexplain everything. This allows the conversation to flow more naturally.
The authors tested their approach on standard dialogue datasets and found it improved the performance of the language model compared to simply using the full conversation history. This suggests their retrieval and summarization technique is an effective way to make dialogue systems both more accurate and more efficient.
Technical Explanation
The core of the authors' approach is a two-stage process for enhancing LLM-based dialogue state tracking (DST):
-
Conversation Retrieval: They develop a retrieval model that can efficiently identify the most relevant past conversations to inform the current DST task. This is done by encoding the current dialogue context and past conversations into compact representations, and then efficiently matching them to select the top-k most relevant prior dialogs.
-
Implicit Text Summaries: For each retrieved conversation, the authors generate a short, implicit summary that captures the key points, rather than providing the full dialog history. This concise summary is then concatenated with the current context and fed into the LLM-based DST model.
The authors evaluate their approach on standard DST benchmarks, including MultiWOZ and SGD, and show that it outperforms using the full conversation history alone. They attribute this improvement to the LLM being better able to focus on the most salient information when making its predictions.
Critical Analysis
The authors acknowledge that their retrieval-based approach adds some computational overhead compared to using the full dialog history. However, they demonstrate that the gains in DST performance outweigh this cost, making the technique an effective and efficient solution.
One potential limitation is that the quality of the implicit summaries relies on the performance of the summarization model. If this component produces low-quality or misleading summaries, it could negatively impact the downstream DST results. The authors do not provide a deep analysis of the summarization model's capabilities and failure modes.
Additionally, the experiments are conducted on established benchmark datasets, which may not fully capture the complexity and diversity of real-world conversational scenarios. Further testing on more varied and challenging dialogue data could help validate the broader applicability of the approach.
Overall, the paper presents a promising direction for enhancing LLM-based dialogue systems by selectively retrieving and summarizing relevant context. With continued research and refinement, techniques like this could lead to more natural and effective conversational AI assistants.
Conclusion
This paper introduces an innovative approach to improving dialogue state tracking by leveraging efficient retrieval and summarization of past conversations. By giving large language models access to distilled, relevant context, the authors demonstrate measurable gains in DST performance compared to using the full dialog history.
The core ideas of selectively retrieving and summarizing conversational data have the potential to significantly enhance the capabilities of dialogue systems, making them more accurate, responsive, and natural to interact with. As language models continue to advance, techniques like this could play a key role in unlocking the full potential of conversational AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Effective and Efficient Conversation Retrieval for Dialogue State Tracking with Implicit Text Summaries
Seanie Lee, Jianpeng Cheng, Joris Driesen, Alexandru Coca, Anders Johannsen
Few-shot dialogue state tracking (DST) with Large Language Models (LLM) relies on an effective and efficient conversation retriever to find similar in-context examples for prompt learning. Previous works use raw dialogue context as search keys and queries, and a retriever is fine-tuned with annotated dialogues to achieve superior performance. However, the approach is less suited for scaling to new domains or new annotation languages, where fine-tuning data is unavailable. To address this problem, we handle the task of conversation retrieval based on text summaries of the conversations. A LLM-based conversation summarizer is adopted for query and key generation, which enables effective maximum inner product search. To avoid the extra inference cost brought by LLM-based conversation summarization, we further distill a light-weight conversation encoder which produces query embeddings without decoding summaries for test conversations. We validate our retrieval approach on MultiWOZ datasets with GPT-Neo-2.7B and LLaMA-7B/30B. The experimental results show a significant improvement over relevant baselines in real few-shot DST settings.
Read more4/4/2024

0
ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval
Kelong Mao, Chenlong Deng, Haonan Chen, Fengran Mo, Zheng Liu, Tetsuya Sakai, Zhicheng Dou
Conversational search requires accurate interpretation of user intent from complex multi-turn contexts. This paper presents ChatRetriever, which inherits the strong generalization capability of large language models to robustly represent complex conversational sessions for dense retrieval. To achieve this, we propose a simple and effective dual-learning approach that adapts LLM for retrieval via contrastive learning while enhancing the complex session understanding through masked instruction tuning on high-quality conversational instruction tuning data. Extensive experiments on five conversational search benchmarks demonstrate that ChatRetriever substantially outperforms existing conversational dense retrievers, achieving state-of-the-art performance on par with LLM-based rewriting approaches. Furthermore, ChatRetriever exhibits superior robustness in handling diverse conversational contexts. Our work highlights the potential of adapting LLMs for retrieval with complex inputs like conversational search sessions and proposes an effective approach to advance this research direction.
Read more4/23/2024
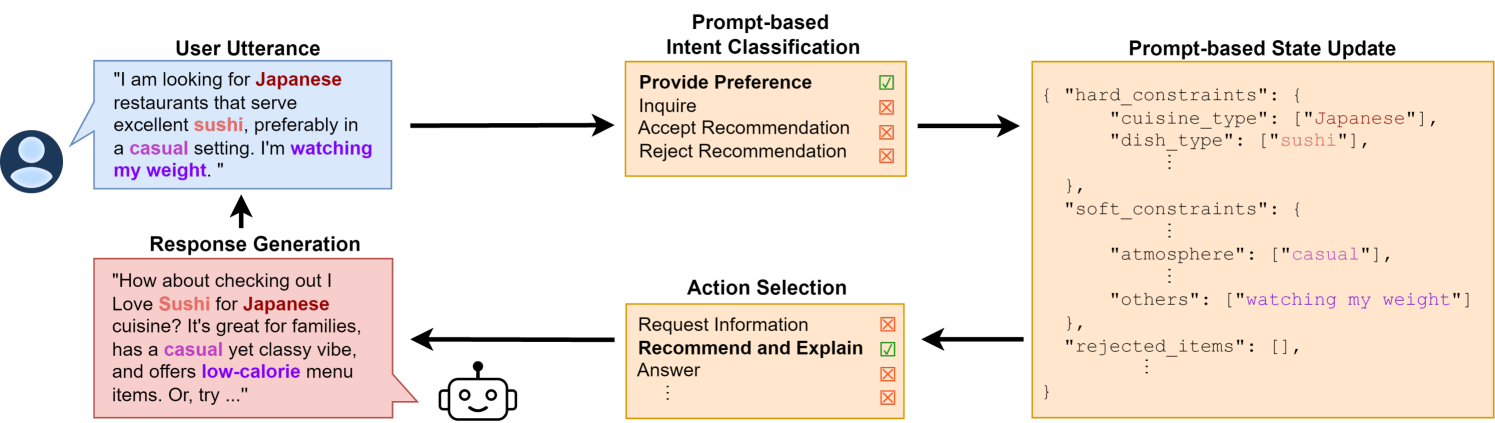
0
Retrieval-Augmented Conversational Recommendation with Prompt-based Semi-Structured Natural Language State Tracking
Sara Kemper, Justin Cui, Kai Dicarlantonio, Kathy Lin, Danjie Tang, Anton Korikov, Scott Sanner
Conversational recommendation (ConvRec) systems must understand rich and diverse natural language (NL) expressions of user preferences and intents, often communicated in an indirect manner (e.g., I'm watching my weight). Such complex utterances make retrieving relevant items challenging, especially if only using often incomplete or out-of-date metadata. Fortunately, many domains feature rich item reviews that cover standard metadata categories and offer complex opinions that might match a user's interests (e.g., classy joint for a date). However, only recently have large language models (LLMs) let us unlock the commonsense connections between user preference utterances and complex language in user-generated reviews. Further, LLMs enable novel paradigms for semi-structured dialogue state tracking, complex intent and preference understanding, and generating recommendations, explanations, and question answers. We thus introduce a novel technology RA-Rec, a Retrieval-Augmented, LLM-driven dialogue state tracking system for ConvRec, showcased with a video, open source GitHub repository, and interactive Google Colab notebook.
Read more6/4/2024
🖼️
0
Enhancing Dialogue State Tracking Models through LLM-backed User-Agents Simulation
Cheng Niu, Xingguang Wang, Xuxin Cheng, Juntong Song, Tong Zhang
Dialogue State Tracking (DST) is designed to monitor the evolving dialogue state in the conversations and plays a pivotal role in developing task-oriented dialogue systems. However, obtaining the annotated data for the DST task is usually a costly endeavor. In this paper, we focus on employing LLMs to generate dialogue data to reduce dialogue collection and annotation costs. Specifically, GPT-4 is used to simulate the user and agent interaction, generating thousands of dialogues annotated with DST labels. Then a two-stage fine-tuning on LLaMA 2 is performed on the generated data and the real data for the DST prediction. Experimental results on two public DST benchmarks show that with the generated dialogue data, our model performs better than the baseline trained solely on real data. In addition, our approach is also capable of adapting to the dynamic demands in real-world scenarios, generating dialogues in new domains swiftly. After replacing dialogue segments in any domain with the corresponding generated ones, the model achieves comparable performance to the model trained on real data.
Read more5/24/2024