Effective Large Language Model Adaptation for Improved Grounding and Citation Generation
2311.09533
0
0
💬
Abstract
Large language models (LLMs) have achieved remarkable advancements in natural language understanding and generation. However, one major issue towards their widespread deployment in the real world is that they can generate hallucinated answers that are not factual. Towards this end, this paper focuses on improving LLMs by grounding their responses in retrieved passages and by providing citations. We propose a new framework, AGREE, Adaptation for GRounding EnhancEment, that improves the grounding from a holistic perspective. Our framework tunes LLMs to selfground the claims in their responses and provide accurate citations to retrieved documents. This tuning on top of the pre-trained LLMs requires well-grounded responses (with citations) for paired queries, for which we introduce a method that can automatically construct such data from unlabeled queries. The selfgrounding capability of tuned LLMs further grants them a test-time adaptation (TTA) capability that can actively retrieve passages to support the claims that have not been grounded, which iteratively improves the responses of LLMs. Across five datasets and two LLMs, our results show that the proposed tuningbased AGREE framework generates superior grounded responses with more accurate citations compared to prompting-based approaches and post-hoc citing-based approaches
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have made remarkable progress in natural language understanding and generation, but can sometimes generate inaccurate or "hallucinated" information.
- This paper proposes a new framework called AGREE (Adaptation for Grounding Enhancement) to improve the grounding of LLM responses in retrieved passages and provide accurate citations.
- AGREE tunes pre-trained LLMs to self-ground their claims and provide citations, using a method to automatically construct well-grounded response data from unlabeled queries.
- The self-grounding capability also allows the tuned LLMs to actively retrieve passages to support claims during inference, iteratively improving the responses.
Plain English Explanation
Large language models (LLMs) are AI systems that are very good at understanding and generating human language. They have become incredibly advanced in recent years, able to do things like answer questions, summarize texts, and even write creative stories.
However, one major issue with these LLMs is that they can sometimes provide information that is not completely accurate or factual. Essentially, they can "hallucinate" answers that sound plausible but are not grounded in real-world knowledge.
This research paper proposes a new approach, called AGREE, to help address this problem. The key idea is to train the LLMs to "ground" their responses - that is, to back up the claims they make by citing specific sources or passages of information.
The AGREE framework does this in a few ways. First, it tunes the pre-trained LLMs to self-ground their responses, meaning the models learn to automatically provide citations to support what they're saying. This is done by training the models on a dataset of questions paired with well-grounded answers that cite relevant sources.
Second, the AGREE-tuned LLMs gain the ability to actively retrieve additional passages during inference to further support any claims that weren't initially well-grounded. This allows the models to iteratively improve their responses by finding more evidence to back them up.
The researchers tested this AGREE approach across several different datasets and language models, and found that it led to significantly more grounded and accurate responses compared to other methods. This is an important step towards making LLMs more reliable and trustworthy for real-world applications.
Technical Explanation
The key components of the AGREE framework are:
-
Tuning pre-trained LLMs: The researchers fine-tune pre-trained LLMs to generate responses that are grounded in retrieved passages and provide accurate citations. This is done by training the models on a dataset of query-answer pairs where the answers are well-grounded and cite relevant sources.
-
Automated dataset construction: Since manually creating a large dataset of grounded query-answer pairs is labor-intensive, the researchers introduce a method to automatically construct such a dataset from unlabeled queries. This involves retrieving relevant passages from a document corpus and pairing them with the original queries.
-
Test-time adaptation (TTA): The tuned LLMs gain the ability to actively retrieve additional passages during inference to further ground claims that were not initially well-supported. This iterative process of retrieving passages and updating the response continues until the model is satisfied with the grounding.
The researchers evaluated AGREE on five different datasets covering a range of topics, using both the GPT-3 and T5 language models. Compared to baseline approaches that rely solely on prompting or post-hoc citing, AGREE demonstrated superior performance in generating responses that are grounded in cited passages.
Critical Analysis
The paper addresses an important limitation of current LLMs - their tendency to hallucinate ungrounded information. The AGREE framework provides a comprehensive solution to improve the grounding and trustworthiness of LLM responses.
One potential limitation is that the automated dataset construction method may introduce some noise or errors into the training data. The researchers acknowledge this and suggest further investigation into more robust data generation techniques.
Additionally, the test-time adaptation (TTA) capability, while powerful, adds computational overhead during inference. The tradeoffs between response quality and inference speed would be an interesting area for further study.
Finally, the paper focuses on textual grounding, but real-world applications may require grounding in other modalities like images or structured data. Extending AGREE to handle multimodal grounding could be a fruitful direction for future research.
Conclusion
This paper presents a significant advance in making large language models more reliable and trustworthy. By training LLMs to self-ground their responses and provide accurate citations, the AGREE framework addresses a critical limitation of current LLMs. The ability to iteratively retrieve supporting evidence further enhances the grounding and credibility of the models' outputs.
As LLMs become more ubiquitous in real-world applications, techniques like AGREE will be essential to ensure the information they provide is factual and well-supported. This research is an important step towards developing AI systems that are more transparent, accountable, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Groundedness in Retrieval-augmented Long-form Generation: An Empirical Study
Alessandro Stolfo
0
0
We present an empirical study of groundedness in long-form question answering (LFQA) by retrieval-augmented large language models (LLMs). In particular, we evaluate whether every generated sentence is grounded in the retrieved documents or the model's pre-training data. Across 3 datasets and 4 model families, our findings reveal that a significant fraction of generated sentences are consistently ungrounded, even when those sentences contain correct ground-truth answers. Additionally, we examine the impacts of factors such as model size, decoding strategy, and instruction tuning on groundedness. Our results show that while larger models tend to ground their outputs more effectively, a significant portion of correct answers remains compromised by hallucinations. This study provides novel insights into the groundedness challenges in LFQA and underscores the necessity for more robust mechanisms in LLMs to mitigate the generation of ungrounded content.
4/11/2024
💬
Grounding Gaps in Language Model Generations
Omar Shaikh, Kristina Gligori'c, Ashna Khetan, Matthias Gerstgrasser, Diyi Yang, Dan Jurafsky
0
0
Effective conversation requires common ground: a shared understanding between the participants. Common ground, however, does not emerge spontaneously in conversation. Speakers and listeners work together to both identify and construct a shared basis while avoiding misunderstanding. To accomplish grounding, humans rely on a range of dialogue acts, like clarification (What do you mean?) and acknowledgment (I understand.). However, it is unclear whether large language models (LLMs) generate text that reflects human grounding. To this end, we curate a set of grounding acts and propose corresponding metrics that quantify attempted grounding. We study whether LLM generations contain grounding acts, simulating turn-taking from several dialogue datasets and comparing results to humans. We find that -- compared to humans -- LLMs generate language with less conversational grounding, instead generating text that appears to simply presume common ground. To understand the roots of the identified grounding gap, we examine the role of instruction tuning and preference optimization, finding that training on contemporary preference data leads to a reduction in generated grounding acts. Altogether, we highlight the need for more research investigating conversational grounding in human-AI interaction.
4/4/2024
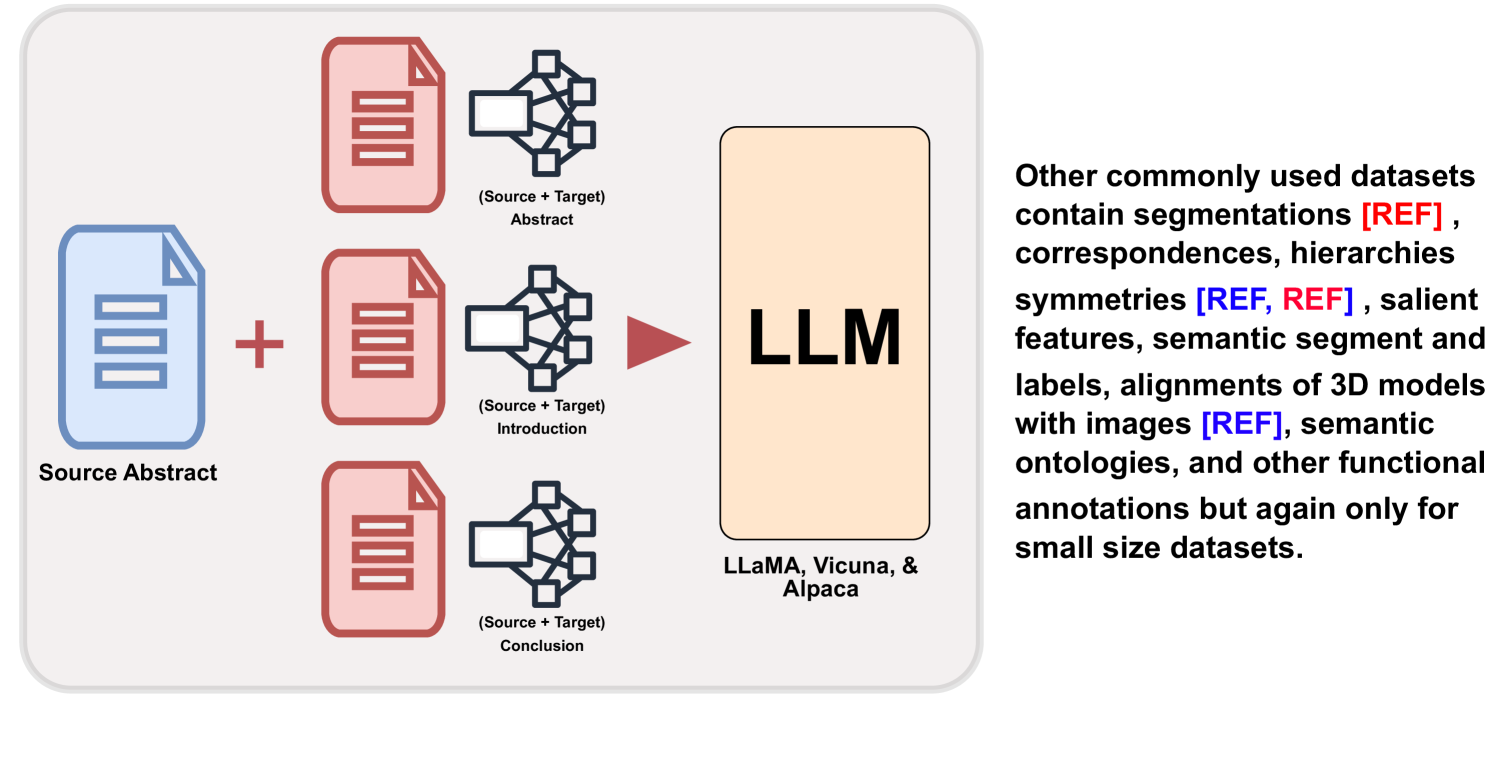
Context-Enhanced Language Models for Generating Multi-Paper Citations
Avinash Anand, Kritarth Prasad, Ujjwal Goel, Mohit Gupta, Naman Lal, Astha Verma, Rajiv Ratn Shah
0
0
Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
4/23/2024
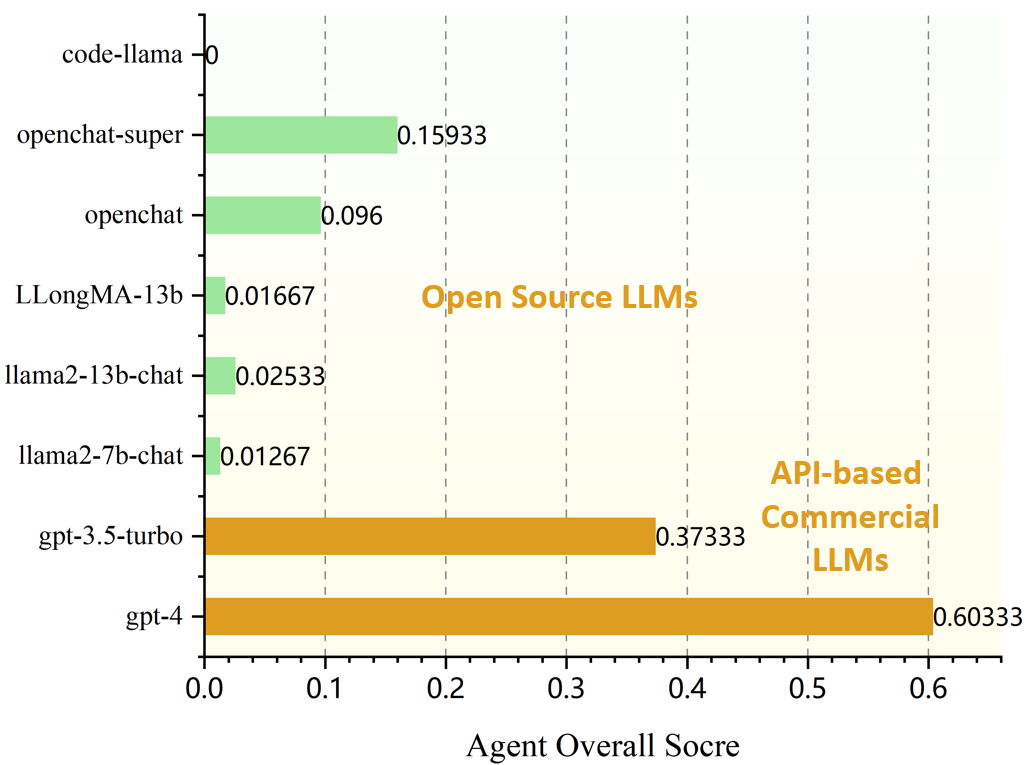
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
0
0
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
4/1/2024