Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
2403.19962
0
0
Abstract
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores methods to enhance the general agent capabilities of low-parameter large language models (LLMs) through tuning and multi-branch reasoning.
- The researchers investigate techniques to improve the performance of smaller LLMs on a variety of tasks, addressing the challenge of developing capable agents with limited computational resources.
- The paper presents a novel approach that combines model tuning and a multi-branch reasoning architecture to boost the general agent capabilities of low-parameter LLMs.
Plain English Explanation
Large language models (LLMs) have demonstrated impressive capabilities across a wide range of tasks, from language generation to task completion. However, these powerful models often require significant computational resources, making them challenging to deploy in resource-constrained environments.
This paper explores strategies to enhance the general agent capabilities of smaller, low-parameter LLMs. The researchers propose a novel approach that combines model tuning and a multi-branch reasoning architecture to boost the performance of these more compact models.
The key idea is to leverage targeted fine-tuning and a multi-branch reasoning system to expand the capabilities of low-parameter LLMs. By customizing the models for specific tasks and incorporating parallel reasoning pathways, the researchers aim to unlock the potential of these smaller, more efficient models, making them better suited for real-world applications with limited computational resources.
Technical Explanation
The paper presents a two-pronged approach to enhancing the general agent capabilities of low-parameter LLMs. First, the researchers employ targeted fine-tuning techniques to adapt the models for specific tasks or domains, allowing them to perform better on those tasks compared to their pre-trained counterparts.
Additionally, the researchers introduce a multi-branch reasoning architecture, where the LLM's outputs are fed into multiple specialized reasoning branches. Each branch is responsible for a particular aspect of the task, such as reasoning about game dynamics or [evaluating the reasoning behavior of the agent. By combining the outputs of these parallel branches, the model can make more informed and nuanced decisions, enhancing its overall capabilities.
The paper also explores the coordination aspects of these multi-branch reasoning systems, investigating how the various branches can work together effectively to solve complex problems.
Critical Analysis
The paper presents a well-designed approach to improving the general agent capabilities of low-parameter LLMs, addressing an important challenge in the field of AI and machine learning. The combination of targeted fine-tuning and multi-branch reasoning appears to be a promising strategy for unlocking the potential of smaller, more efficient models.
However, the paper acknowledges some limitations of the proposed approach. The researchers note that the performance gains achieved through their methods may be task-specific, and the optimal configuration of the multi-branch reasoning system may vary depending on the problem domain. Additionally, the paper suggests that further research is needed to fully understand the nuances of the multi-branch reasoning architecture and its impact on agent coordination and decision-making.
It would be valuable for future studies to explore the scalability of this approach, investigating how well it can be applied to a wider range of tasks and domains. Researchers may also want to consider the potential tradeoffs between the increased complexity of the multi-branch reasoning system and the overall computational efficiency of the low-parameter LLM.
Conclusion
This paper presents a novel approach to enhancing the general agent capabilities of low-parameter LLMs, addressing a critical challenge in the field of AI. By combining targeted fine-tuning and a multi-branch reasoning architecture, the researchers have developed a strategy to unlock the potential of smaller, more efficient language models, making them better suited for real-world applications with limited computational resources.
The insights and techniques discussed in this paper have the potential to contribute to the ongoing efforts to develop capable and versatile AI agents that can operate effectively in a wide range of settings, regardless of the available computational power. As the demand for energy-efficient and cost-effective AI solutions continues to grow, this research could pave the way for more accessible and impactful AI applications across various industries and domains.
Related Papers
Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
Gawon Choi, Hyemin Ahn
0
0
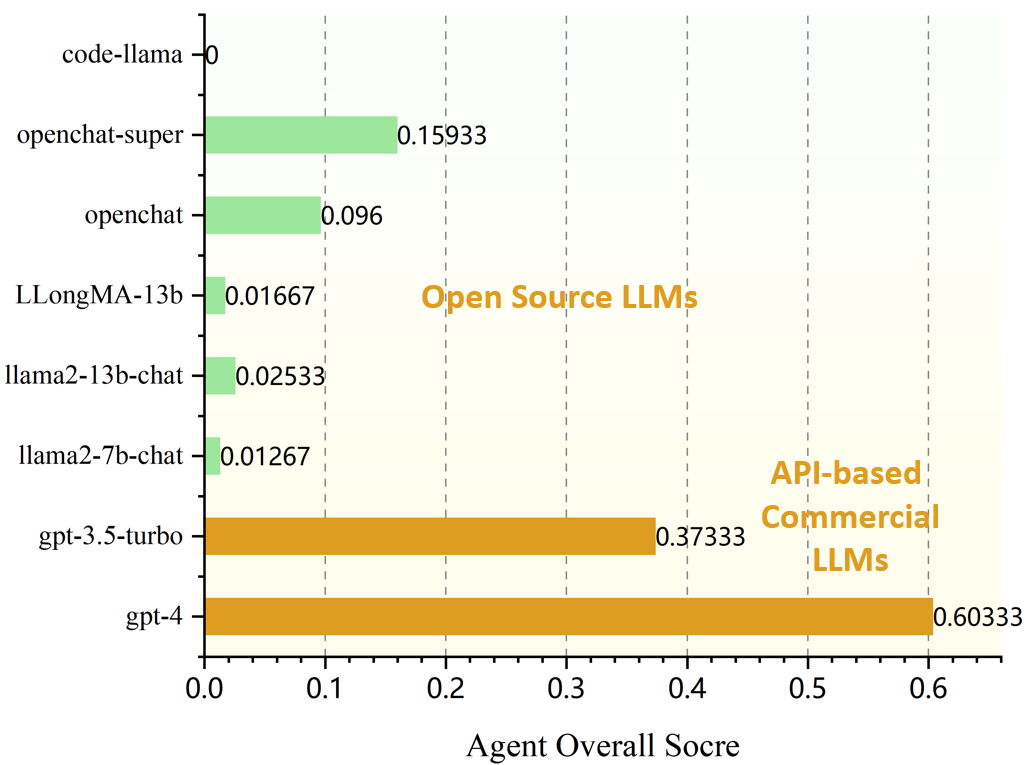
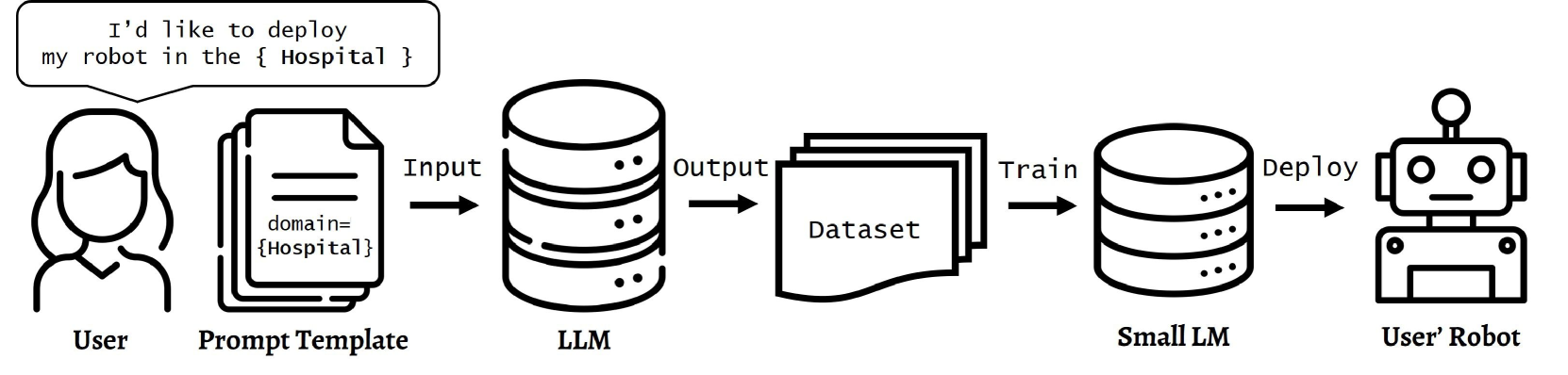
In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning
4/8/2024
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
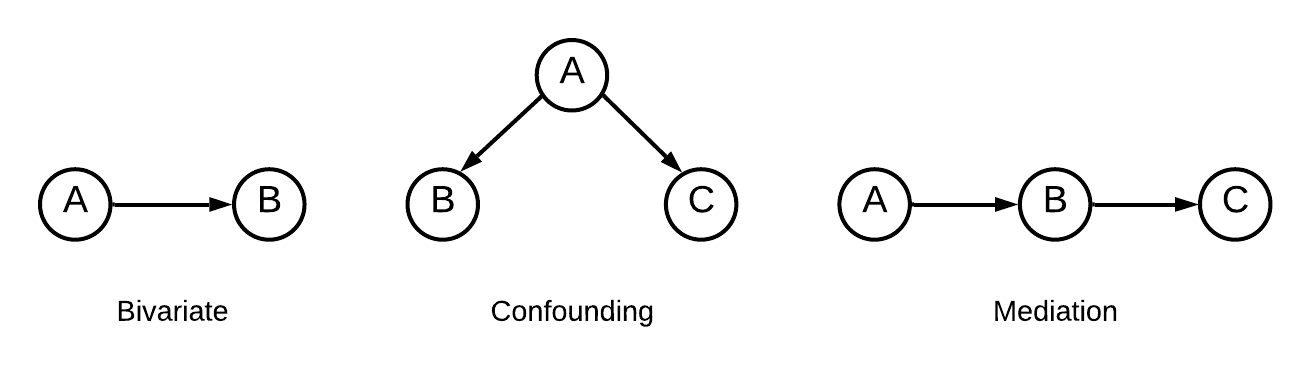
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
0
0
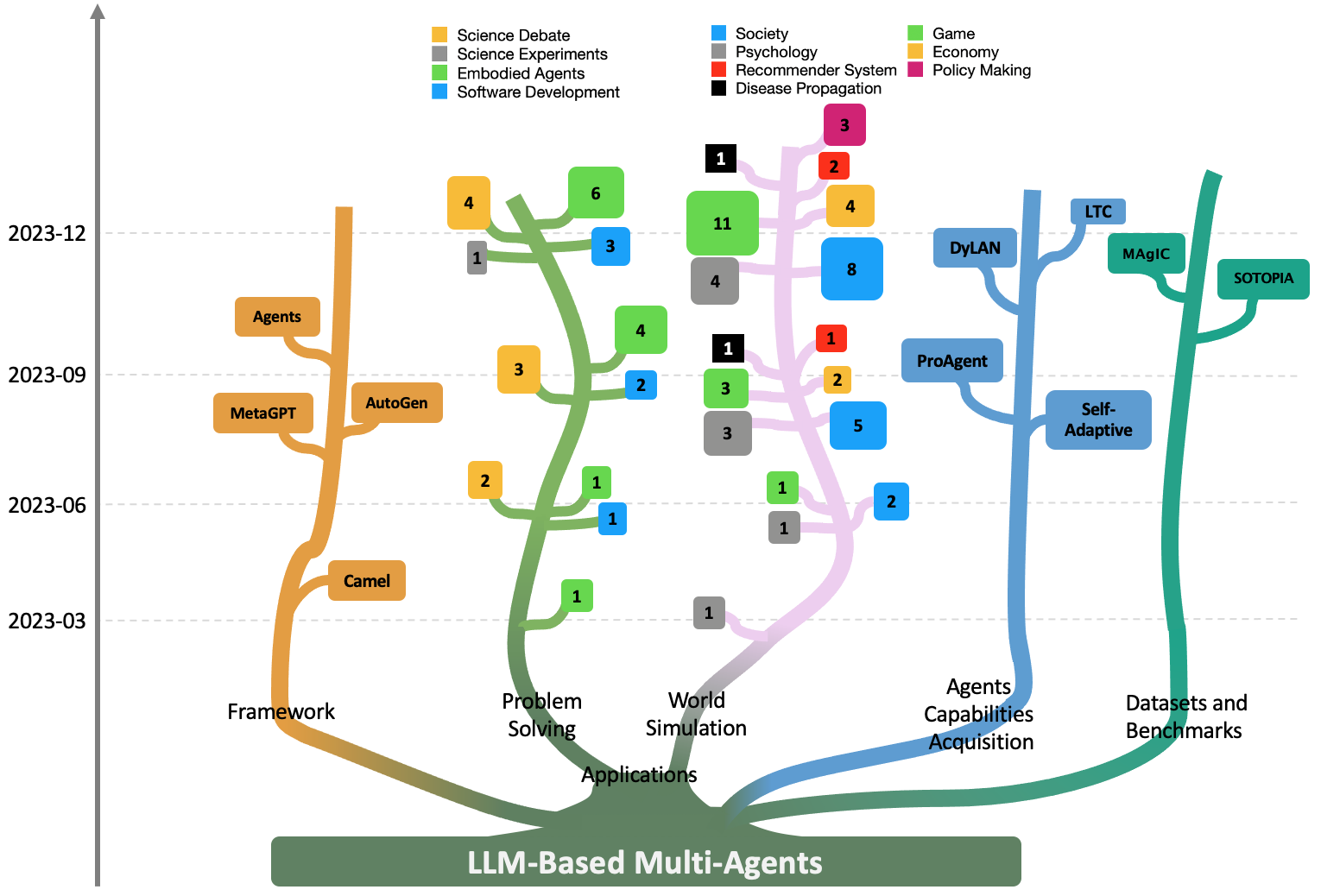
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
4/22/2024
💬
Improving the Capabilities of Large Language Model Based Marketing Analytics Copilots With Semantic Search And Fine-Tuning
Yilin Gao, Sai Kumar Arava, Yancheng Li, James W. Snyder Jr
0
0
Artificial intelligence (AI) is widely deployed to solve problems related to marketing attribution and budget optimization. However, AI models can be quite complex, and it can be difficult to understand model workings and insights without extensive implementation teams. In principle, recently developed large language models (LLMs), like GPT-4, can be deployed to provide marketing insights, reducing the time and effort required to make critical decisions. In practice, there are substantial challenges that need to be overcome to reliably use such models. We focus on domain-specific question-answering, SQL generation needed for data retrieval, and tabular analysis and show how a combination of semantic search, prompt engineering, and fine-tuning can be applied to dramatically improve the ability of LLMs to execute these tasks accurately. We compare both proprietary models, like GPT-4, and open-source models, like Llama-2-70b, as well as various embedding methods. These models are tested on sample use cases specific to marketing mix modeling and attribution.
4/23/2024