Effective Subset Selection Through The Lens of Neural Network Pruning
2406.01086
0
0
Abstract
Having large amounts of annotated data significantly impacts the effectiveness of deep neural networks. However, the annotation task can be very expensive in some domains, such as medical data. Thus, it is important to select the data to be annotated wisely, which is known as the subset selection problem. We investigate the relationship between subset selection and neural network pruning, which is more widely studied, and establish a correspondence between them. Leveraging insights from network pruning, we propose utilizing the norm criterion of neural network features to improve subset selection methods. We empirically validate our proposed strategy on various networks and datasets, demonstrating enhanced accuracy. This shows the potential of employing pruning tools for subset selection.
Create account to get full access
Overview
- This paper explores the connection between neural network pruning and effective subset selection, a key challenge in machine learning.
- The authors propose a novel approach called Subspace Node Pruning that leverages the insights from neural network pruning to identify the most informative subset of features or samples.
- The paper also discusses related work in areas like robust data pruning, algorithm selection using neural networks, and layer pruning, highlighting the broader significance of this research.
Plain English Explanation
Neural networks are powerful machine learning models that can learn complex patterns in data. However, as these models become larger and more complex, it can be challenging to identify the most important features or data points that contribute the most to the model's performance. This is known as the "effective subset selection" problem.
The authors of this paper propose a new approach called Subspace Node Pruning that borrows insights from the field of neural network pruning. In neural network pruning, the goal is to remove unnecessary connections or nodes from a trained model to make it more efficient, without significantly impacting its performance. The authors realized that the techniques used for neural network pruning could also be applied to the problem of effective subset selection.
The key idea is to use the information gathered during the pruning process to identify the most important features or data points in the original dataset. By understanding which parts of the network are most essential for the model's performance, the researchers can select the corresponding features or data points that are the most informative for the task at hand.
This approach has several potential benefits. First, it can help improve the interpretability of machine learning models by highlighting the most relevant inputs. Second, it can lead to more efficient and effective models by focusing on the most important data. Finally, it may also have applications in other areas, such as robust data pruning, algorithm selection, and layer pruning, as discussed in the paper.
Overall, this research provides a novel perspective on the effective subset selection problem, leveraging the insights gained from the well-studied field of neural network pruning. By bridging these two areas, the authors have developed a promising new approach that could have far-reaching implications for the field of machine learning.
Technical Explanation
The paper introduces a novel technique called Subspace Node Pruning (SNP) that leverages insights from neural network pruning to address the effective subset selection problem. The key idea is to use the information gathered during the process of pruning a neural network to identify the most important features or data points in the original dataset.
The authors first provide an overview of related work in areas like robust data pruning, algorithm selection using neural networks, and layer pruning, highlighting the broader context and significance of this research.
The SNP approach works as follows:
- Train a neural network on the full dataset.
- Prune the trained network to identify the most important nodes and connections.
- Use the information gathered during the pruning process to select the most informative features or data points from the original dataset.
The authors demonstrate the effectiveness of SNP on a range of benchmark datasets and tasks, comparing its performance to other feature and sample selection methods. The results show that SNP can outperform these alternative approaches, particularly in scenarios where the dataset contains a large number of uninformative features or redundant samples.
The paper also discusses the potential limitations of the SNP approach, such as the sensitivity to the initial neural network architecture and the hyperparameters used during the pruning process. The authors suggest that further research is needed to better understand the theoretical underpinnings of the method and to explore its applications in other domains, such as large-scale dataset pruning.
Critical Analysis
The paper presents a compelling approach to the effective subset selection problem, leveraging insights from the well-studied field of neural network pruning. The authors' key insight – that the information gathered during the pruning process can be used to identify the most informative features or data points – is both novel and intuitively appealing.
One potential limitation of the SNP approach is its reliance on the initial neural network architecture and the specific pruning techniques used. The authors acknowledge this and suggest that further research is needed to better understand the theoretical foundations of the method and to explore its robustness to these design choices.
Additionally, while the paper demonstrates the effectiveness of SNP on a range of benchmark datasets, it would be interesting to see how the method performs on more complex, real-world datasets and tasks. This could help to further validate the approach and highlight any potential issues or limitations that may arise in more challenging scenarios.
Nevertheless, the paper makes a valuable contribution to the field of machine learning by bridging the gap between neural network pruning and effective subset selection. The authors have provided a novel and promising approach that could have far-reaching implications, as evidenced by the related work discussed in the paper. Overall, this research represents a significant step forward in addressing an important challenge in machine learning.
Conclusion
This paper presents a novel approach called Subspace Node Pruning (SNP) that leverages insights from neural network pruning to address the effective subset selection problem. By using the information gathered during the pruning process, SNP can identify the most informative features or data points in a given dataset, leading to more efficient and effective machine learning models.
The authors' work demonstrates the potential of bridging different areas of machine learning research, in this case, combining techniques from neural network pruning and feature/sample selection. The SNP approach has shown promising results on a range of benchmark datasets, and the authors have highlighted its broader applications in areas like robust data pruning, algorithm selection, and layer pruning.
While the paper acknowledges some potential limitations of the SNP method, the overall contribution represents a significant step forward in addressing a key challenge in machine learning. By providing a new perspective on effective subset selection, this research has the potential to inspire further advancements in the field and contribute to the development of more interpretable, efficient, and effective machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Enhancing Neural Subset Selection: Integrating Background Information into Set Representations
Binghui Xie, Yatao Bian, Kaiwen zhou, Yongqiang Chen, Peilin Zhao, Bo Han, Wei Meng, James Cheng
0
0
Learning neural subset selection tasks, such as compound selection in AI-aided drug discovery, have become increasingly pivotal across diverse applications. The existing methodologies in the field primarily concentrate on constructing models that capture the relationship between utility function values and subsets within their respective supersets. However, these approaches tend to overlook the valuable information contained within the superset when utilizing neural networks to model set functions. In this work, we address this oversight by adopting a probabilistic perspective. Our theoretical findings demonstrate that when the target value is conditioned on both the input set and subset, it is essential to incorporate an textit{invariant sufficient statistic} of the superset into the subset of interest for effective learning. This ensures that the output value remains invariant to permutations of the subset and its corresponding superset, enabling identification of the specific superset from which the subset originated. Motivated by these insights, we propose a simple yet effective information aggregation module designed to merge the representations of subsets and supersets from a permutation invariance perspective. Comprehensive empirical evaluations across diverse tasks and datasets validate the enhanced efficacy of our approach over conventional methods, underscoring the practicality and potency of our proposed strategies in real-world contexts.
6/11/2024

Subspace Node Pruning
Joshua Offergeld, Marcel van Gerven, Nasir Ahmad
0
0
A significant increase in the commercial use of deep neural network models increases the need for efficient AI. Node pruning is the art of removing computational units such as neurons, filters, attention heads, or even entire layers while keeping network performance at a maximum. This can significantly reduce the inference time of a deep network and thus enhance its efficiency. Few of the previous works have exploited the ability to recover performance by reorganizing network parameters while pruning. In this work, we propose to create a subspace from unit activations which enables node pruning while recovering maximum accuracy. We identify that for effective node pruning, a subspace can be created using a triangular transformation matrix, which we show to be equivalent to Gram-Schmidt orthogonalization, which automates this procedure. We further improve this method by reorganizing the network prior to subspace formation. Finally, we leverage the orthogonal subspaces to identify layer-wise pruning ratios appropriate to retain a significant amount of the layer-wise information. We show that this measure outperforms existing pruning methods on VGG networks. We further show that our method can be extended to other network architectures such as residual networks.
5/29/2024

Robust Data Pruning: Uncovering and Overcoming Implicit Bias
Artem Vysogorets, Kartik Ahuja, Julia Kempe
0
0
In the era of exceptionally data-hungry models, careful selection of the training data is essential to mitigate the extensive costs of deep learning. Data pruning offers a solution by removing redundant or uninformative samples from the dataset, which yields faster convergence and improved neural scaling laws. However, little is known about its impact on classification bias of the trained models. We conduct the first systematic study of this effect and reveal that existing data pruning algorithms can produce highly biased classifiers. At the same time, we argue that random data pruning with appropriate class ratios has potential to improve the worst-class performance. We propose a fairness-aware approach to pruning and empirically demonstrate its performance on standard computer vision benchmarks. In sharp contrast to existing algorithms, our proposed method continues improving robustness at a tolerable drop of average performance as we prune more from the datasets. We present theoretical analysis of the classification risk in a mixture of Gaussians to further motivate our algorithm and support our findings.
4/9/2024
Sample Complexity of Algorithm Selection Using Neural Networks and Its Applications to Branch-and-Cut
Hongyu Cheng, Sammy Khalife, Barbara Fiedorowicz, Amitabh Basu
0
0
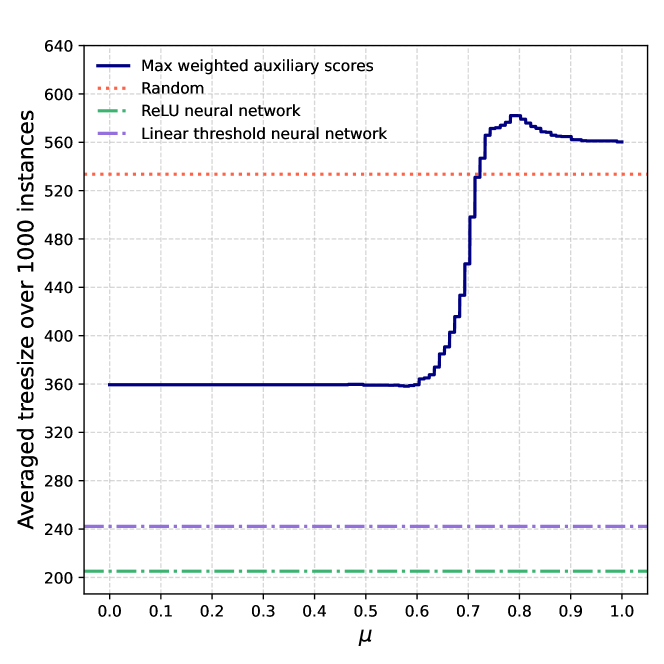
Data-driven algorithm design is a paradigm that uses statistical and machine learning techniques to select from a class of algorithms for a computational problem an algorithm that has the best expected performance with respect to some (unknown) distribution on the instances of the problem. We build upon recent work in this line of research by considering the setup where, instead of selecting a single algorithm that has the best performance, we allow the possibility of selecting an algorithm based on the instance to be solved, using neural networks. In particular, given a representative sample of instances, we learn a neural network that maps an instance of the problem to the most appropriate algorithm for that instance. We formalize this idea and derive rigorous sample complexity bounds for this learning problem, in the spirit of recent work in data-driven algorithm design. We then apply this approach to the problem of making good decisions in the branch-and-cut framework for mixed-integer optimization (e.g., which cut to add?). In other words, the neural network will take as input a mixed-integer optimization instance and output a decision that will result in a small branch-and-cut tree for that instance. Our computational results provide evidence that our particular way of using neural networks for cut selection can make a significant impact in reducing branch-and-cut tree sizes, compared to previous data-driven approaches.
6/5/2024