Robust Data Pruning: Uncovering and Overcoming Implicit Bias
2404.05579
0
0

Abstract
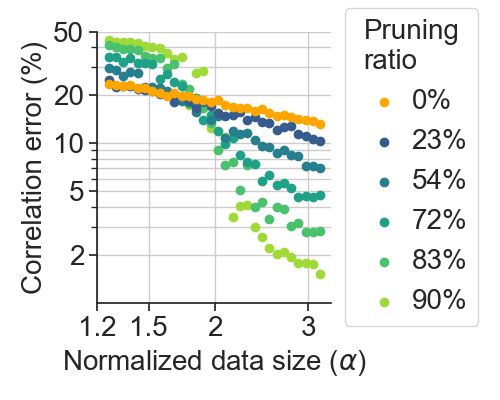
In the era of exceptionally data-hungry models, careful selection of the training data is essential to mitigate the extensive costs of deep learning. Data pruning offers a solution by removing redundant or uninformative samples from the dataset, which yields faster convergence and improved neural scaling laws. However, little is known about its impact on classification bias of the trained models. We conduct the first systematic study of this effect and reveal that existing data pruning algorithms can produce highly biased classifiers. At the same time, we argue that random data pruning with appropriate class ratios has potential to improve the worst-class performance. We propose a fairness-aware approach to pruning and empirically demonstrate its performance on standard computer vision benchmarks. In sharp contrast to existing algorithms, our proposed method continues improving robustness at a tolerable drop of average performance as we prune more from the datasets. We present theoretical analysis of the classification risk in a mixture of Gaussians to further motivate our algorithm and support our findings.
Create account to get full access
Overview
- This paper discusses the issue of implicit bias in data pruning, which is the process of selectively removing data points from a dataset to improve model performance.
- The researchers uncover how data pruning can amplify existing biases in the data, leading to unfair and biased machine learning models.
- The paper proposes a robust data pruning approach to overcome these issues and ensure fairness in the model outputs.
Plain English Explanation
Data pruning is a common technique used in machine learning to improve model performance by removing unnecessary or irrelevant data points. However, this paper shows that data pruning can also unintentionally amplify existing biases in the dataset, leading to unfair and biased models.
Imagine you're training a model to predict job applicant success. If the dataset has more positive examples for male applicants than female applicants, data pruning might remove more female examples, further skewing the data towards male applicants. This can result in a model that is biased against women, even though the original dataset may have had less obvious biases.
The researchers propose a "robust data pruning" approach to address this issue. Instead of just focusing on improving model performance, their method also considers fairness and tries to reduce biases in the pruned dataset. This helps ensure the final model is more accurate and, importantly, also more fair and unbiased in its predictions.
Technical Explanation
The paper first discusses the concept of data pruning and how it can impact model fairness. The authors explain how existing data pruning methods, which aim to optimize model performance, can inadvertently amplify biases present in the original dataset. They provide a mathematical formulation to capture this issue.
To address this problem, the researchers develop a robust data pruning approach that explicitly considers fairness objectives along with performance. Their method uses a dual gradient-based optimization procedure to simultaneously prune the data and learn a fair model. This ensures the pruned dataset maintains a balanced representation of different demographic groups, mitigating the amplification of biases.
The authors evaluate their robust pruning method on several benchmark datasets and find it outperforms standard pruning approaches in terms of both model accuracy and fairness metrics. They also analyze the pruned datasets to gain insights into how their method overcomes implicit biases.
Critical Analysis
The researchers thoroughly investigate an important issue in machine learning – the potential for data pruning to exacerbate biases. By proposing a principled, optimization-based solution to this problem, the paper makes a valuable contribution to the field of Increasing Fairness in Classification on Out-of-Distribution Data and Would Deep Generative Models Amplify Bias in the Future?.
However, the paper would be strengthened by a more in-depth discussion of the limitations and potential drawbacks of their approach. For example, the authors do not address how their method might perform on datasets with more complex, intersectional biases, or how it scales to very large-scale pruning problems. Additionally, the paper could benefit from a more thorough comparison to other Inference-Time Rule Eraser: Distilling and Removing Bias and DRIVE: Dual Gradient-based Rapid Iterative Pruning techniques for addressing bias in data pruning.
Conclusion
This paper makes an important contribution to the field of machine learning by highlighting the issue of implicit bias in data pruning and proposing a robust solution to address it. By considering fairness objectives in the pruning process, the researchers' method helps ensure that the final model is not only accurate but also unbiased in its predictions. This work has significant implications for building more ethical and responsible AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Large-scale Dataset Pruning with Dynamic Uncertainty
Muyang He, Shuo Yang, Tiejun Huang, Bo Zhao
0
0
The state of the art of many learning tasks, e.g., image classification, is advanced by collecting larger datasets and then training larger models on them. As the outcome, the increasing computational cost is becoming unaffordable. In this paper, we investigate how to prune the large-scale datasets, and thus produce an informative subset for training sophisticated deep models with negligible performance drop. We propose a simple yet effective dataset pruning method by exploring both the prediction uncertainty and training dynamics. We study dataset pruning by measuring the variation of predictions during the whole training process on large-scale datasets, i.e., ImageNet-1K and ImageNet-21K, and advanced models, i.e., Swin Transformer and ConvNeXt. Extensive experimental results indicate that our method outperforms the state of the art and achieves 25% lossless pruning ratio on both ImageNet-1K and ImageNet-21K. The code and pruned datasets are available at https://github.com/BAAI-DCAI/Dataset-Pruning.
6/17/2024
PUMA: margin-based data pruning
Javier Maroto, Pascal Frossard
0
0
Deep learning has been able to outperform humans in terms of classification accuracy in many tasks. However, to achieve robustness to adversarial perturbations, the best methodologies require to perform adversarial training on a much larger training set that has been typically augmented using generative models (e.g., diffusion models). Our main objective in this work, is to reduce these data requirements while achieving the same or better accuracy-robustness trade-offs. We focus on data pruning, where some training samples are removed based on the distance to the model classification boundary (i.e., margin). We find that the existing approaches that prune samples with low margin fails to increase robustness when we add a lot of synthetic data, and explain this situation with a perceptron learning task. Moreover, we find that pruning high margin samples for better accuracy increases the harmful impact of mislabeled perturbed data in adversarial training, hurting both robustness and accuracy. We thus propose PUMA, a new data pruning strategy that computes the margin using DeepFool, and prunes the training samples of highest margin without hurting performance by jointly adjusting the training attack norm on the samples of lowest margin. We show that PUMA can be used on top of the current state-of-the-art methodology in robustness, and it is able to significantly improve the model performance unlike the existing data pruning strategies. Not only PUMA achieves similar robustness with less data, but it also significantly increases the model accuracy, improving the performance trade-off.
5/13/2024
📊
Trusting Fair Data: Leveraging Quality in Fairness-Driven Data Removal Techniques
Manh Khoi Duong, Stefan Conrad
0
0
In this paper, we deal with bias mitigation techniques that remove specific data points from the training set to aim for a fair representation of the population in that set. Machine learning models are trained on these pre-processed datasets, and their predictions are expected to be fair. However, such approaches may exclude relevant data, making the attained subsets less trustworthy for further usage. To enhance the trustworthiness of prior methods, we propose additional requirements and objectives that the subsets must fulfill in addition to fairness: (1) group coverage, and (2) minimal data loss. While removing entire groups may improve the measured fairness, this practice is very problematic as failing to represent every group cannot be considered fair. In our second concern, we advocate for the retention of data while minimizing discrimination. By introducing a multi-objective optimization problem that considers fairness and data loss, we propose a methodology to find Pareto-optimal solutions that balance these objectives. By identifying such solutions, users can make informed decisions about the trade-off between fairness and data quality and select the most suitable subset for their application.
6/12/2024
Large-Scale Dataset Pruning in Adversarial Training through Data Importance Extrapolation
Bjorn Nieth, Thomas Altstidl, Leo Schwinn, Bjorn Eskofier
0
0
Their vulnerability to small, imperceptible attacks limits the adoption of deep learning models to real-world systems. Adversarial training has proven to be one of the most promising strategies against these attacks, at the expense of a substantial increase in training time. With the ongoing trend of integrating large-scale synthetic data this is only expected to increase even further. Thus, the need for data-centric approaches that reduce the number of training samples while maintaining accuracy and robustness arises. While data pruning and active learning are prominent research topics in deep learning, they are as of now largely unexplored in the adversarial training literature. We address this gap and propose a new data pruning strategy based on extrapolating data importance scores from a small set of data to a larger set. In an empirical evaluation, we demonstrate that extrapolation-based pruning can efficiently reduce dataset size while maintaining robustness.
6/21/2024