On the effects of similarity metrics in decentralized deep learning under distributional shift

0
Sign in to get full access
Overview
- Examines the effects of similarity metrics on decentralized deep learning under distributional shift
- Considers how different similarity metrics can impact model performance and convergence in federated learning scenarios
- Conducted experiments to assess the performance of various similarity metrics in the presence of data heterogeneity and drift
Plain English Explanation
In the context of decentralized deep learning, where machine learning models are trained across multiple devices or organizations without a central authority, the choice of similarity metric can have a significant impact on the model's performance.
The paper investigates how different similarity metrics, such as cosine similarity or Euclidean distance, can affect the model's ability to learn effectively when the data distribution across devices is not uniform (known as distributional shift).
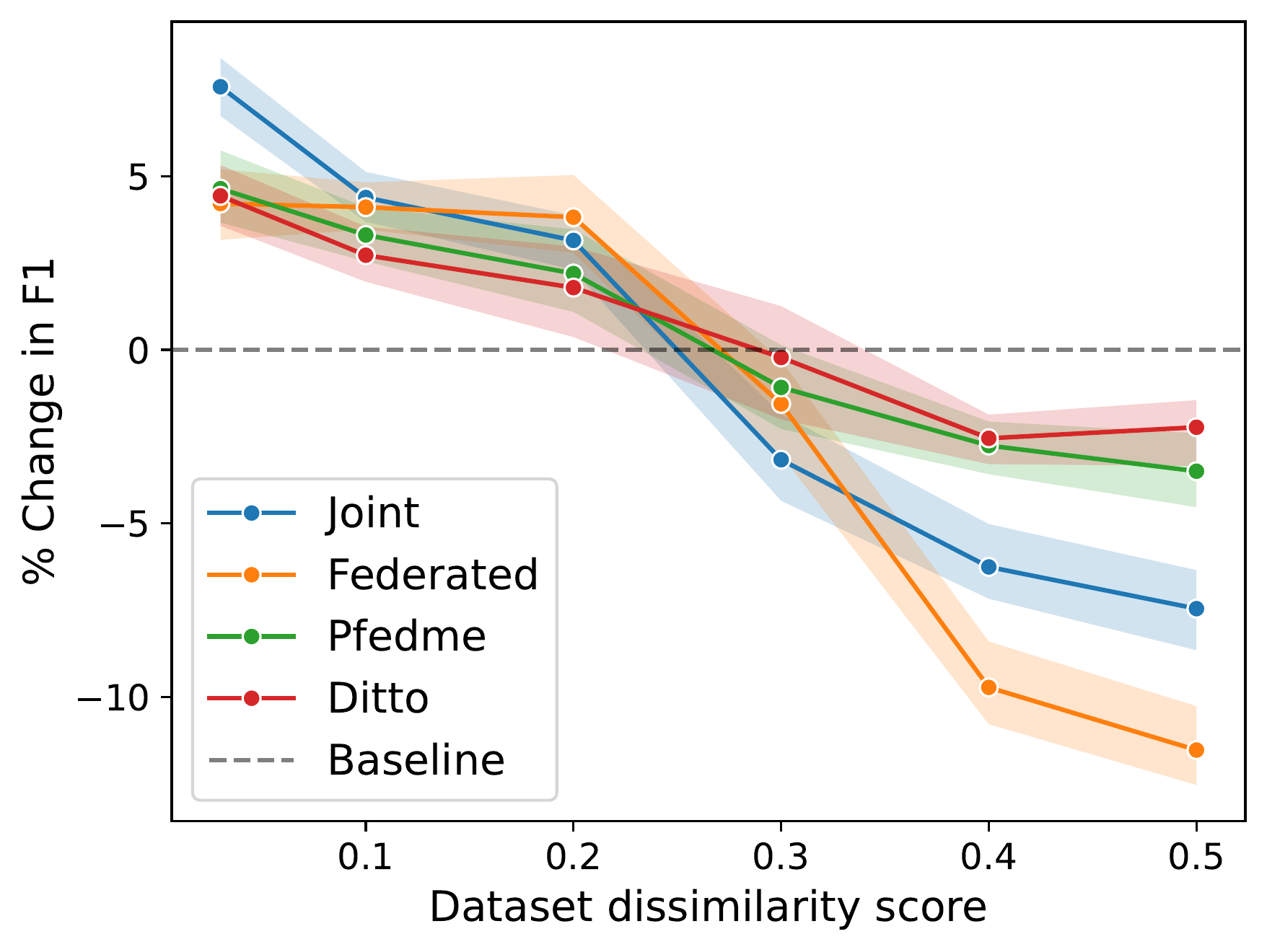
The researchers conducted experiments to evaluate the performance of various similarity metrics in scenarios where the data on each device differed in terms of its statistical properties. They found that the choice of similarity metric can have a substantial effect on the model's convergence and final performance, especially when the data is heterogeneous or drifts over time.
Technical Explanation
The paper examines the impact of similarity metrics in the context of decentralized deep learning, where multiple devices or organizations collaborate to train a shared model without a central authority.
The authors consider several commonly used similarity metrics, such as cosine similarity, Euclidean distance, and Pearson correlation, and assess their performance in the presence of distributional shift - i.e., when the data distribution across devices is not uniform.
Through a series of experiments, the researchers demonstrate that the choice of similarity metric can have a significant impact on the model's convergence and final performance, especially when the data is heterogeneous or drifts over time. They find that certain metrics, such as cosine similarity, can be more robust to distributional shift, while others, like Euclidean distance, may be more sensitive to data heterogeneity.
The paper also discusses the implications of these findings for the design of federated learning systems and the incentivization of data sharing in decentralized settings.
Critical Analysis
The paper provides valuable insights into the importance of similarity metrics in decentralized deep learning under distributional shift. However, the authors acknowledge that their experiments are limited to specific scenarios and dataset configurations, and they encourage further research to explore the generalizability of their findings.
Additionally, the paper does not address potential privacy-preserving or Byzantine-robust considerations in the selection of similarity metrics, which may be important in real-world decentralized learning applications.
Further research could also investigate the impact of similarity metrics in more complex decentralized learning settings, such as those involving data distillation or gradient-based data selection.
Conclusion
This paper highlights the critical role that similarity metrics play in the performance of decentralized deep learning systems, especially when the data is heterogeneous or shifts over time. By carefully considering the choice of similarity metric, researchers and practitioners can design more robust and effective federated learning frameworks, ultimately paving the way for more successful collaboration and data sharing in decentralized settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the effects of similarity metrics in decentralized deep learning under distributional shift
Edvin Listo Zec, Tom Hagander, Eric Ihre-Thomason, Sarunas Girdzijauskas
Decentralized Learning (DL) enables privacy-preserving collaboration among organizations or users to enhance the performance of local deep learning models. However, model aggregation becomes challenging when client data is heterogeneous, and identifying compatible collaborators without direct data exchange remains a pressing issue. In this paper, we investigate the effectiveness of various similarity metrics in DL for identifying peers for model merging, conducting an empirical analysis across multiple datasets with distribution shifts. Our research provides insights into the performance of these metrics, examining their role in facilitating effective collaboration. By exploring the strengths and limitations of these metrics, we contribute to the development of robust DL methods.
Read more9/18/2024
0
A Universal Metric of Dataset Similarity for Cross-silo Federated Learning
Ahmed Elhussein, Gamze Gursoy
Federated Learning is increasingly used in domains such as healthcare to facilitate collaborative model training without data-sharing. However, datasets located in different sites are often non-identically distributed, leading to degradation of model performance in FL. Most existing methods for assessing these distribution shifts are limited by being dataset or task-specific. Moreover, these metrics can only be calculated by exchanging data, a practice restricted in many FL scenarios. To address these challenges, we propose a novel metric for assessing dataset similarity. Our metric exhibits several desirable properties for FL: it is dataset-agnostic, is calculated in a privacy-preserving manner, and is computationally efficient, requiring no model training. In this paper, we first establish a theoretical connection between our metric and training dynamics in FL. Next, we extensively evaluate our metric on a range of datasets including synthetic, benchmark, and medical imaging datasets. We demonstrate that our metric shows a robust and interpretable relationship with model performance and can be calculated in privacy-preserving manner. As the first federated dataset similarity metric, we believe this metric can better facilitate successful collaborations between sites.
Read more4/30/2024
↗️
0
Privacy-Preserving Aggregation for Decentralized Learning with Byzantine-Robustness
Ali Reza Ghavamipour, Benjamin Zi Hao Zhao, Oguzhan Ersoy, Fatih Turkmen
Decentralized machine learning (DL) has been receiving an increasing interest recently due to the elimination of a single point of failure, present in Federated learning setting. Yet, it is threatened by the looming threat of Byzantine clients who intentionally disrupt the learning process by broadcasting arbitrary model updates to other clients, seeking to degrade the performance of the global model. In response, robust aggregation schemes have emerged as promising solutions to defend against such Byzantine clients, thereby enhancing the robustness of Decentralized Learning. Defenses against Byzantine adversaries, however, typically require access to the updates of other clients, a counterproductive privacy trade-off that in turn increases the risk of inference attacks on those same model updates. In this paper, we introduce SecureDL, a novel DL protocol designed to enhance the security and privacy of DL against Byzantine threats. SecureDL~facilitates a collaborative defense, while protecting the privacy of clients' model updates through secure multiparty computation. The protocol employs efficient computation of cosine similarity and normalization of updates to robustly detect and exclude model updates detrimental to model convergence. By using MNIST, Fashion-MNIST, SVHN and CIFAR-10 datasets, we evaluated SecureDL against various Byzantine attacks and compared its effectiveness with four existing defense mechanisms. Our experiments show that SecureDL is effective even in the case of attacks by the malicious majority (e.g., 80% Byzantine clients) while preserving high training accuracy.
Read more4/30/2024

0
Data Distribution Shifts in (Industrial) Federated Learning as a Privacy Issue
David Brunner, Alessio Montuoro
We consider industrial federated learning, a collaboration between a small number of powerful, potentially competing industrial players, mediated by a third party aspiring to improve the service it provides to its customers. We argue that this configuration harbours covert privacy risks that do not arise in e.g. cross-device settings. Companies are very protective of their intellectual property and production processes. Information about changes to their production and the timing of which is to be kept private. We study a scenario in which one of the collaborators infers changes to their competitors' production by detecting potentially subtle temporal data distribution shifts. In this framing, a data distribution shift is always problematic, even if it has no negative effect on training convergence. Thus, our goal is to find means that allow the detection of distributional shifts better than customary evaluation metrics. Based on the assumption that even minor shifts translate into the collaboratively learned machine learning model, the attacker tracks the shared models' internal state with a selection of metrics from literature in order to pick up on relevant changes. In an empirical study on benchmark datasets, we show an honest-but-curious attacker to be capable of detecting subtle distributional shifts on other clients, in some cases long before they become obvious in evaluation.
Read more9/24/2024