Efficiency for Free: Ideal Data Are Transportable Representations
2405.14669
0
0
📊
Abstract
Data, the seminal opportunity and challenge in modern machine learning, currently constrains the scalability of representation learning and impedes the pace of model evolution. Existing paradigms tackle the issue of learning efficiency over massive datasets from the perspective of self-supervised learning and dataset distillation independently, while neglecting the untapped potential of accelerating representation learning from an intermediate standpoint. In this work, we delve into defining the ideal data properties from both optimization and generalization perspectives. We propose that model-generated representations, despite being trained on diverse tasks and architectures, converge to a shared linear space, facilitating effective linear transport between models. Furthermore, we demonstrate that these representations exhibit properties conducive to the formation of ideal data. The theoretical/empirical insights therein inspire us to propose a Representation Learning Accelerator (ReLA), which leverages a task- and architecture-agnostic, yet publicly available, free model to form a dynamic data subset and thus accelerate (self-)supervised learning. For instance, employing a CLIP ViT B/16 as a prior model for dynamic data generation, ReLA-aided BYOL can train a ResNet-50 from scratch with 50% of ImageNet-1K, yielding performance surpassing that of training on the full dataset. Additionally, employing a ResNet-18 pre-trained on CIFAR-10 can enhance ResNet-50 training on 10% of ImageNet-1K, resulting in a 7.7% increase in accuracy.
Create account to get full access
Overview
- The paper discusses the challenges of data constraints in modern machine learning, and proposes a Representation Learning Accelerator (ReLA) to address these challenges.
- ReLA leverages publicly available, task- and architecture-agnostic models to generate dynamic data subsets, which can then be used to accelerate (self-)supervised learning.
- The paper suggests that model-generated representations converge to a shared linear space, facilitating effective linear transport between models and enabling the formation of "ideal data" for faster learning.
Plain English Explanation
The amount and quality of data available is a major factor that constrains how well machine learning models can be trained. The paper explores ways to address this challenge by using existing models to generate new, more effective training data.
The key idea is that different machine learning models, even if trained on diverse tasks and architectures, tend to produce representations that live in a shared "linear space." This means that the high-level features extracted by the models are similar, and can be easily transferred between them.
The authors propose a system called the "Representation Learning Accelerator" (ReLA) that takes advantage of this property. ReLA uses a publicly available, general-purpose model (like CLIP) to generate a subset of "ideal" training data. This data can then be used to train other models much more efficiently, requiring less of the original training data.
For example, by using a CLIP model to generate a reduced ImageNet dataset, the authors were able to train a ResNet-50 model to the same performance level as training on the full ImageNet dataset, but using only 50% of the original data. Similarly, they were able to improve the performance of a ResNet-50 model on 10% of ImageNet by pretraining it on a small CIFAR-10 dataset.
The key insight is that the representations learned by general-purpose models like CLIP can act as a bridge, allowing efficient transfer of knowledge to other models and tasks, even when the original training data is limited.
Technical Explanation
The paper proposes a Representation Learning Accelerator (ReLA) that leverages publicly available, task- and architecture-agnostic models to generate dynamic data subsets for accelerating (self-)supervised learning.
The authors first establish that model-generated representations, despite being trained on diverse tasks and architectures, converge to a shared linear space. This facilitates effective linear transport between models, enabling the formation of "ideal data" that exhibits properties conducive to faster learning.
To demonstrate the effectiveness of ReLA, the authors conduct several experiments. In one example, they use a CLIP ViT B/16 model as a prior for dynamic data generation, and show that ReLA-aided BYOL can train a ResNet-50 from scratch with just 50% of the ImageNet-1K dataset, achieving performance surpassing that of training on the full dataset.
In another experiment, the authors use a ResNet-18 pre-trained on CIFAR-10 to enhance ResNet-50 training on 10% of ImageNet-1K, resulting in a 7.7% increase in accuracy compared to training on the limited ImageNet data alone.
The key technical insights are:
- Model-generated representations converge to a shared linear space, enabling effective linear transport between models (Quantifying Representation Reliability in Self-Supervised Learning Models).
- These representations exhibit properties that are conducive to the formation of "ideal data" for faster learning (Image Clustering via Principle Rate Reduction).
- ReLA leverages a task- and architecture-agnostic prior model to generate dynamic data subsets that can significantly accelerate (self-)supervised learning on various tasks and datasets.
Critical Analysis
The paper presents a novel and promising approach to addressing the data constraints that limit the scalability of modern machine learning. By leveraging the shared linear space of model representations, ReLA offers a way to generate more effective training data without relying solely on the original dataset.
However, the paper does not fully address the potential limitations and caveats of this approach. For example, it is unclear how the performance of ReLA-generated data would scale to larger or more complex datasets, or how the choice of the prior model might affect the quality of the generated data.
Additionally, the paper focuses primarily on vision-based tasks, and it is not clear how well the proposed approach would generalize to other domains, such as financial transactional data or natural language processing.
Further research and experimentation would be needed to fully understand the strengths, weaknesses, and broader applicability of the ReLA framework. Nonetheless, the insights provided in this paper represent an important step towards addressing the data challenges that constrain the evolution of machine learning models.
Conclusion
The paper introduces the Representation Learning Accelerator (ReLA), a novel approach to addressing the data constraints that limit the scalability of modern machine learning. By leveraging the shared linear space of model representations, ReLA can generate dynamic data subsets that can significantly accelerate (self-)supervised learning, even with limited original training data.
The key innovation is the idea of using a publicly available, task- and architecture-agnostic prior model to bridge the gap between different models and tasks, enabling efficient knowledge transfer and the formation of "ideal data" for faster learning. The empirical results demonstrate the potential of this approach, and suggest that ReLA could be a valuable tool for advancing the state of the art in representation learning and model evolution.
While the paper primarily focuses on vision-based tasks, the underlying principles and insights could have broader applicability across various domains of machine learning. Further research and development of the ReLA framework could lead to significant advancements in how we approach the fundamental challenge of data constraints in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
0
0
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
6/5/2024
🤯
From latent dynamics to meaningful representations
Dedi Wang, Yihang Wang, Luke Evans, Pratyush Tiwary
0
0
While representation learning has been central to the rise of machine learning and artificial intelligence, a key problem remains in making the learned representations meaningful. For this, the typical approach is to regularize the learned representation through prior probability distributions. However, such priors are usually unavailable or are ad hoc. To deal with this, recent efforts have shifted towards leveraging the insights from physical principles to guide the learning process. In this spirit, we propose a purely dynamics-constrained representation learning framework. Instead of relying on predefined probabilities, we restrict the latent representation to follow overdamped Langevin dynamics with a learnable transition density - a prior driven by statistical mechanics. We show this is a more natural constraint for representation learning in stochastic dynamical systems, with the crucial ability to uniquely identify the ground truth representation. We validate our framework for different systems including a real-world fluorescent DNA movie dataset. We show that our algorithm can uniquely identify orthogonal, isometric and meaningful latent representations.
4/11/2024
REP: Resource-Efficient Prompting for On-device Continual Learning
Sungho Jeon, Xinyue Ma, Kwang In Kim, Myeongjae Jeon
0
0
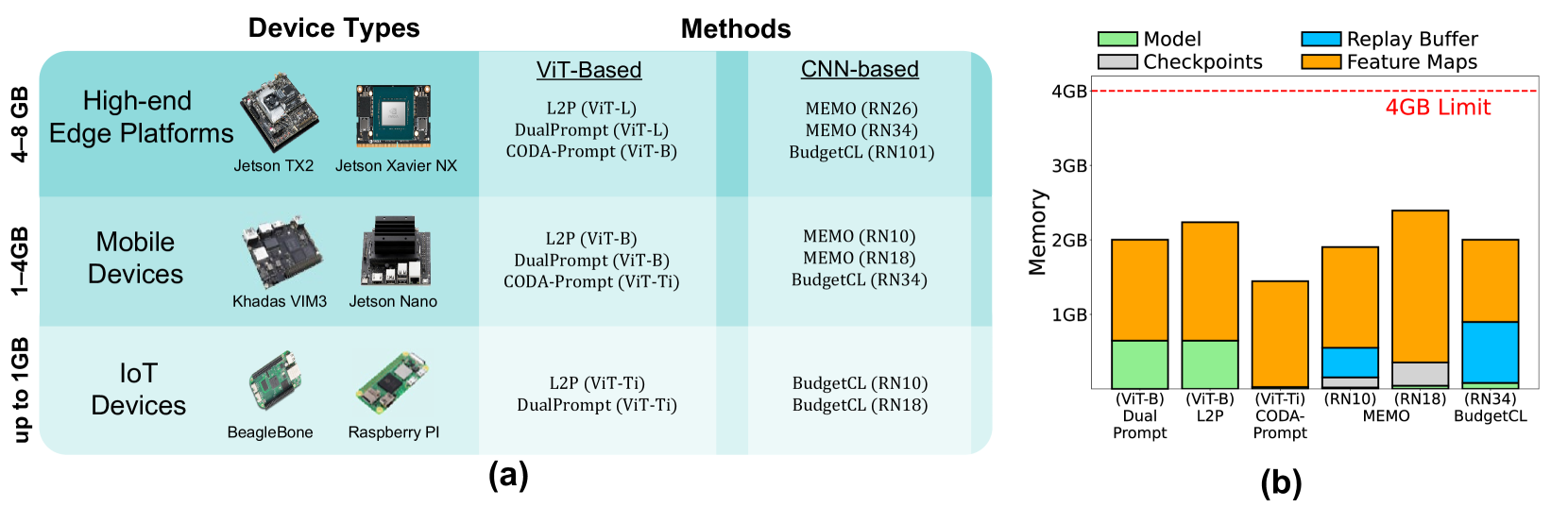
On-device continual learning (CL) requires the co-optimization of model accuracy and resource efficiency to be practical. This is extremely challenging because it must preserve accuracy while learning new tasks with continuously drifting data and maintain both high energy and memory efficiency to be deployable on real-world devices. Typically, a CL method leverages one of two types of backbone networks: CNN or ViT. It is commonly believed that CNN-based CL excels in resource efficiency, whereas ViT-based CL is superior in model performance, making each option attractive only for a single aspect. In this paper, we revisit this comparison while embracing powerful pre-trained ViT models of various sizes, including ViT-Ti (5.8M parameters). Our detailed analysis reveals that many practical options exist today for making ViT-based methods more suitable for on-device CL, even when accuracy, energy, and memory are all considered. To further expand this impact, we introduce REP, which improves resource efficiency specifically targeting prompt-based rehearsal-free methods. Our key focus is on avoiding catastrophic trade-offs with accuracy while trimming computational and memory costs throughout the training process. We achieve this by exploiting swift prompt selection that enhances input data using a carefully provisioned model, and by developing two novel algorithms-adaptive token merging (AToM) and adaptive layer dropping (ALD)-that optimize the prompt updating stage. In particular, AToM and ALD perform selective skipping across the data and model-layer dimensions without compromising task-specific features in vision transformer models. Extensive experiments on three image classification datasets validate REP's superior resource efficiency over current state-of-the-art methods.
6/10/2024
🔍
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
0
0
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
5/24/2024