Representations as Language: An Information-Theoretic Framework for Interpretability
2406.02449
0
0
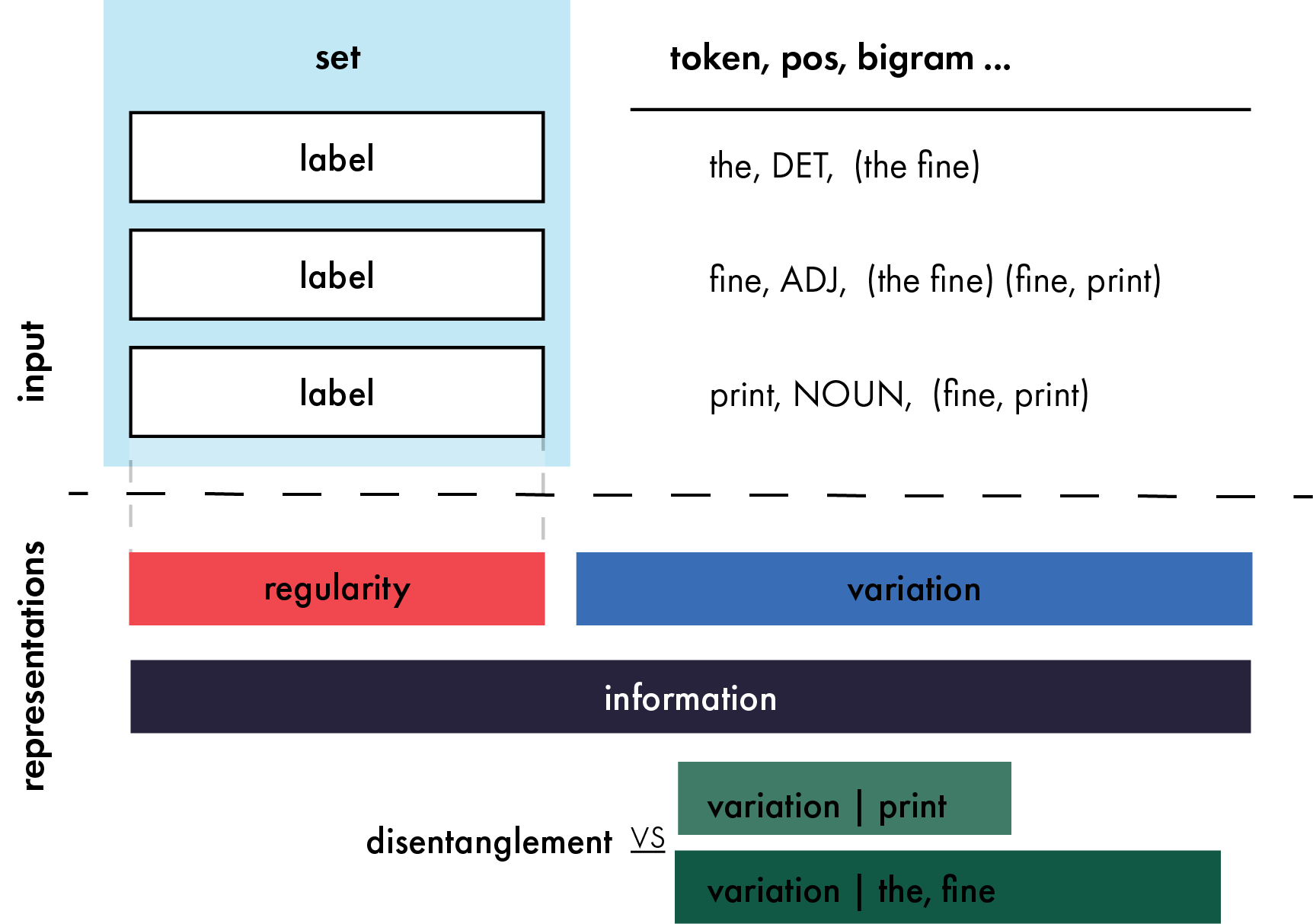
Abstract
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
Create account to get full access
Overview
- Presents an information-theoretic framework for interpreting and understanding the representations learned by machine learning models
- Proposes representing model representations as a "language" that can be analyzed and interpreted using techniques from natural language processing
- Demonstrates how this approach can provide insights into the inner workings of complex models and improve model interpretability
Plain English Explanation
The paper introduces a new way to understand how machine learning models "think" by representing the internal representations they learn as a kind of "language." Just like natural languages have vocabularies, grammar, and structures that can be analyzed, the authors suggest that the internal representations of machine learning models can also be studied in a similar way.
By modeling the representations as a language, the researchers show that tools from natural language processing can be used to gain insights into what the model has learned and how it is making decisions. This can help make complex machine learning systems more interpretable and understandable to humans.
For example, the authors demonstrate how this framework can be used to identify the most important "words" or features that a model is focusing on, and how these features are combined to form higher-level "sentences" or representations. This provides a window into the black box of the model's inner workings.
The key insight is that even very advanced machine learning models, which may seem opaque and difficult to understand, can be analyzed and interpreted in a systematic way using this language-based approach. This could lead to more transparent and accountable AI systems in the future.
Technical Explanation
The paper proposes an information-theoretic framework for interpreting the internal representations learned by machine learning models. The core idea is to treat these representations as a form of "language" that can be analyzed using techniques from natural language processing.
Specifically, the authors define a set of information-theoretic measures that can be used to quantify various properties of the representations, such as their complexity, distinctiveness, and the relationships between different parts of the representation. These measures are inspired by concepts from information theory and linguistics, such as surprisal, perplexity, and mutual information.
The researchers demonstrate the utility of this framework through several case studies, including analyzing the representations learned by language models, image classification models, and reinforcement learning agents. They show how the proposed measures can provide insights into the structure and function of these representations, and how this can be used to improve model interpretability and explainability.
For example, the authors show how the most "informative" or significant features in a model's representation can be identified, and how these features are combined to form higher-level representations. They also explore how the complexity and diversity of the representations evolve during the training process, and how this relates to the model's performance.
Overall, the paper presents a novel and principled approach to understanding the inner workings of complex machine learning models, with the goal of making these systems more transparent and accountable. The information-theoretic framework provides a rigorous mathematical foundation for this task, while the connection to natural language processing offers a familiar and intuitive way to interpret the results.
Critical Analysis
The proposed information-theoretic framework for interpreting machine learning representations is a promising approach that could lead to significant advances in model interpretability and explainability. By representing the internal representations as a form of "language," the authors are able to leverage a wealth of existing techniques and insights from natural language processing, which is a well-studied field.
One potential limitation of the approach, however, is that it may not fully capture the nuances and complexities of the representations learned by modern machine learning models, which can be highly nonlinear and multi-modal. The information-theoretic measures used in the paper, while rigorous, may not always provide a complete or accurate picture of the representation's structure and function.
Additionally, the paper primarily focuses on analyzing the representations themselves, rather than their impact on the model's overall performance or decision-making. While this is a valuable first step, it will be important to also consider how the insights gained from this framework can be used to improve the model's behavior and robustness, particularly in sensitive or high-stakes applications.
Further research could explore ways to extend the proposed framework to handle more complex and dynamic representations, as well as to better integrate the interpretability insights with the model's actual decision-making process. Incorporating human feedback and evaluation into the analysis could also help ensure that the interpretability measures align with human-centric notions of transparency and explainability.
Overall, the paper presents a compelling and well-executed approach to model interpretability, and its connection to natural language processing is a particularly promising direction for future work in this area. By continuing to develop and refine these types of interpretability frameworks, we can work towards more accountable and trustworthy AI systems that can be better integrated into real-world applications.
Conclusion
This paper introduces an information-theoretic framework for interpreting and understanding the internal representations learned by machine learning models. By representing these representations as a form of "language," the authors demonstrate how techniques from natural language processing can be applied to gain insights into the structure and function of these representations.
The proposed measures, such as surprisal, perplexity, and mutual information, provide a rigorous mathematical foundation for quantifying various properties of the representations, such as their complexity, distinctiveness, and the relationships between different parts of the representation. The authors show how these measures can be used to identify the most important features in a model's representation, and how these features are combined to form higher-level representations.
Overall, this work represents an important step towards making complex machine learning systems more interpretable and explainable. By providing a principled framework for analyzing the inner workings of these models, the paper lays the groundwork for more transparent and accountable AI systems that can be better integrated into real-world applications. As the field of machine learning continues to advance, approaches like this will become increasingly crucial for ensuring the safety, reliability, and trustworthiness of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
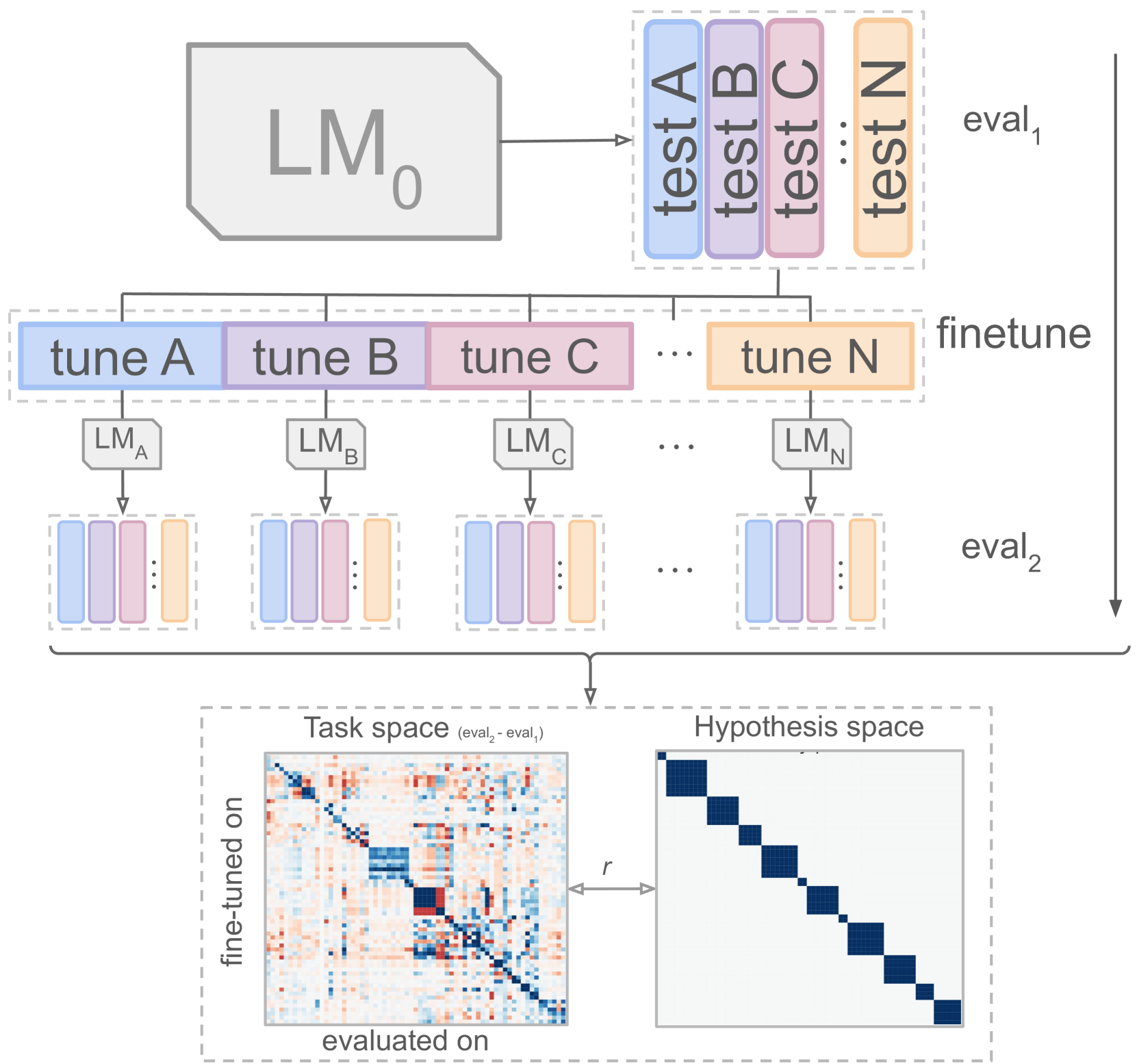
Interpretability of Language Models via Task Spaces
Lucas Weber, Jaap Jumelet, Elia Bruni, Dieuwke Hupkes
0
0
The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
6/11/2024
👁️
Interpretable Representations in Explainable AI: From Theory to Practice
Kacper Sokol, Peter Flach
0
0
Interpretable representations are the backbone of many explainers that target black-box predictive systems based on artificial intelligence and machine learning algorithms. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanatory insights. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, tweaking which allows to target a particular audience and use case. However, many explainers built upon interpretable representations overlook their merit and fall back on default solutions that often carry implicit assumptions, thereby degrading the explanatory power and reliability of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We demonstrate how they are operationalised for tabular, image and text data; discuss their assumptions, strengths and weaknesses; identify their core building blocks; and scrutinise their configuration and parameterisation. In particular, this in-depth analysis allows us to pinpoint their explanatory properties, desiderata and scope for (malicious) manipulation in the context of tabular data where a linear model is used to quantify the influence of interpretable concepts on a black-box prediction. Our findings lead to a range of recommendations for designing trustworthy interpretable representations; specifically, the benefits of class-aware (supervised) discretisation of tabular data, e.g., with decision trees, and sensitivity of image interpretable representations to segmentation granularity and occlusion colour.
4/29/2024

Interpreting Latent Student Knowledge Representations in Programming Assignments
Nigel Fernandez, Andrew Lan
0
0
Recent advances in artificial intelligence for education leverage generative large language models, including using them to predict open-ended student responses rather than their correctness only. However, the black-box nature of these models limits the interpretability of the learned student knowledge representations. In this paper, we conduct a first exploration into interpreting latent student knowledge representations by presenting InfoOIRT, an Information regularized Open-ended Item Response Theory model, which encourages the latent student knowledge states to be interpretable while being able to generate student-written code for open-ended programming questions. InfoOIRT maximizes the mutual information between a fixed subset of latent knowledge states enforced with simple prior distributions and generated student code, which encourages the model to learn disentangled representations of salient syntactic and semantic code features including syntactic styles, mastery of programming skills, and code structures. Through experiments on a real-world programming education dataset, we show that InfoOIRT can both accurately generate student code and lead to interpretable student knowledge representations.
5/15/2024
💬
A Philosophical Introduction to Language Models - Part II: The Way Forward
Raphael Milli`ere, Cameron Buckner
0
0
In this paper, the second of two companion pieces, we explore novel philosophical questions raised by recent progress in large language models (LLMs) that go beyond the classical debates covered in the first part. We focus particularly on issues related to interpretability, examining evidence from causal intervention methods about the nature of LLMs' internal representations and computations. We also discuss the implications of multimodal and modular extensions of LLMs, recent debates about whether such systems may meet minimal criteria for consciousness, and concerns about secrecy and reproducibility in LLM research. Finally, we discuss whether LLM-like systems may be relevant to modeling aspects of human cognition, if their architectural characteristics and learning scenario are adequately constrained.
5/7/2024