Efficient Medical Question Answering with Knowledge-Augmented Question Generation
2405.14654
0
0
🛸
Abstract
In the expanding field of language model applications, medical knowledge representation remains a significant challenge due to the specialized nature of the domain. Large language models, such as GPT-4, obtain reasonable scores on medical question answering tasks, but smaller models are far behind. In this work, we introduce a method to improve the proficiency of a small language model in the medical domain by employing a two-fold approach. We first fine-tune the model on a corpus of medical textbooks. Then, we use GPT-4 to generate questions similar to the downstream task, prompted with textbook knowledge, and use them to fine-tune the model. Additionally, we introduce ECN-QA, a novel medical question answering dataset containing ``progressive questions'' composed of related sequential questions. We show the benefits of our training strategy on this dataset. The study's findings highlight the potential of small language models in the medical domain when appropriately fine-tuned. The code and weights are available at https://github.com/raidium-med/MQG.
Create account to get full access
Overview
- Improving the performance of small language models in the medical domain is a significant challenge due to the specialized nature of the field.
- This work introduces a two-fold approach to enhance the proficiency of a small language model in medical question answering tasks.
- The study also introduces a novel medical question answering dataset called ECN-QA, which contains "progressive questions" composed of related sequential questions.
Plain English Explanation
Medical knowledge is highly specialized, and it can be difficult for language models to perform well on tasks related to it. This is especially true for smaller language models, which often struggle compared to larger models like GPT-4.
To address this, the researchers in this study used a two-step approach. First, they "fine-tuned" a small language model by training it on a large corpus of medical textbooks. This helps the model learn the specialized vocabulary and concepts used in the medical domain.
Next, they used the powerful GPT-4 model to generate practice questions for the smaller model, based on the knowledge it had learned from the textbooks. This additional fine-tuning helped the small model become better at answering medical questions.
The researchers also created a new dataset called ECN-QA, which contains "progressive questions" - a series of related questions that build on each other. This allows the researchers to test how well the model can understand and retain medical knowledge over a sequence of questions.
The results of this study show that with the right training approach, smaller language models can perform well on medical question answering tasks, even though they are not as capable as larger models like GPT-4 in this domain. This is an important step in making advanced language technology more accessible and useful in the medical field.
Technical Explanation
The researchers in this study focused on improving the performance of small language models on medical question answering tasks. They employed a two-fold approach to fine-tune a small model for this domain.
First, they fine-tuned the model on a corpus of medical textbooks. This allowed the model to learn the specialized vocabulary and concepts used in the medical field, which is crucial for performing well on medical tasks.
Next, they used the powerful GPT-4 model to generate practice questions for the smaller model, based on the knowledge it had learned from the textbooks. This additional fine-tuning helped the small model become better at answering medical questions.
The researchers also introduced a novel medical question answering dataset called ECN-QA. This dataset contains "progressive questions" - a series of related questions that build on each other. This allows the researchers to test how well the model can understand and retain medical knowledge over a sequence of questions, which is an important aspect of medical reasoning.
The study's findings demonstrate the potential of small language models in the medical domain when they are appropriately fine-tuned. The researchers show that the two-fold fine-tuning approach can significantly improve the performance of a small model on medical question answering tasks, bringing it closer to the capabilities of larger models like GPT-4.
Critical Analysis
The researchers acknowledge that while their approach leads to significant improvements in the small model's performance, it is still not on par with the capabilities of larger models like GPT-4 on medical question answering tasks. This suggests that there is still room for further research and development to bridge the gap between small and large language models in specialized domains like medicine.
Additionally, the researchers note that the ECN-QA dataset they introduced, while a valuable resource for evaluating medical question answering models, may not capture the full breadth and complexity of real-world medical scenarios. Further research may be needed to develop more comprehensive and realistic datasets for this task.
Another potential limitation of the study is that it focuses primarily on text-based medical knowledge and question answering. In the real world, medical decision-making often involves the integration of multiple modalities, such as medical images, diagnostic tests, and patient histories. Future research could explore ways to extend the proposed approach to incorporate these additional modalities and better reflect the multifaceted nature of medical practice.
Overall, the researchers have made an important contribution to the field of medical language modeling, but there are still opportunities for further advancements and refinements to truly unlock the potential of small language models in the medical domain.
Conclusion
This study presents a promising approach to improving the performance of small language models on medical question answering tasks. By fine-tuning the model on medical textbooks and using GPT-4 to generate practice questions, the researchers were able to significantly enhance the small model's proficiency in this specialized domain.
The introduction of the ECN-QA dataset, with its "progressive questions," also provides a valuable tool for evaluating the medical reasoning capabilities of language models. While the small model's performance is still not on par with larger models like GPT-4, the study's findings highlight the potential of fine-tuning strategies to bridge this gap and make advanced language technology more accessible and useful in the medical field.
As the field of medical language modeling continues to evolve, this work serves as an important stepping stone towards developing more robust and capable language models that can support healthcare professionals and ultimately improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
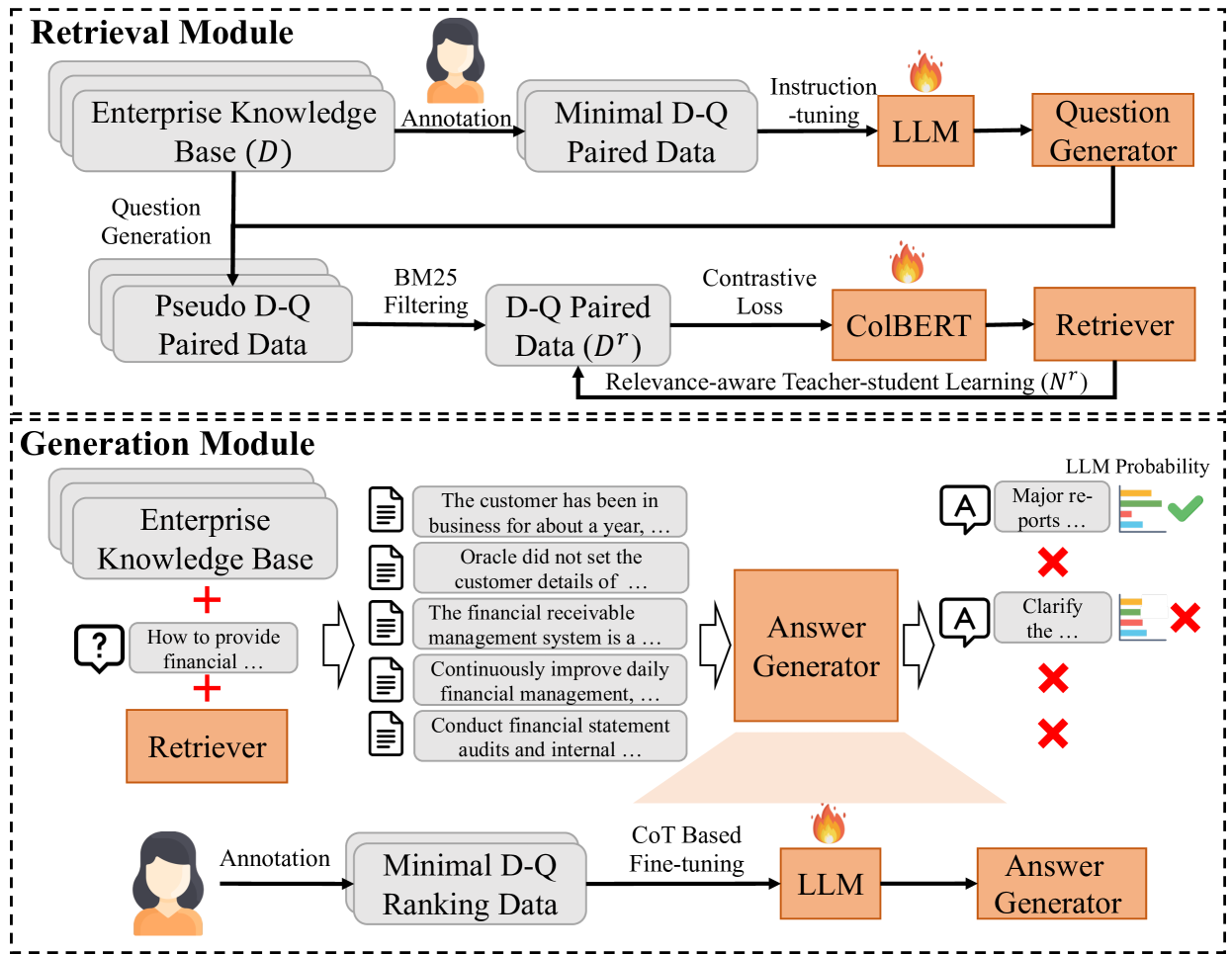
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024
MedREQAL: Examining Medical Knowledge Recall of Large Language Models via Question Answering
Juraj Vladika, Phillip Schneider, Florian Matthes
0
0
In recent years, Large Language Models (LLMs) have demonstrated an impressive ability to encode knowledge during pre-training on large text corpora. They can leverage this knowledge for downstream tasks like question answering (QA), even in complex areas involving health topics. Considering their high potential for facilitating clinical work in the future, understanding the quality of encoded medical knowledge and its recall in LLMs is an important step forward. In this study, we examine the capability of LLMs to exhibit medical knowledge recall by constructing a novel dataset derived from systematic reviews -- studies synthesizing evidence-based answers for specific medical questions. Through experiments on the new MedREQAL dataset, comprising question-answer pairs extracted from rigorous systematic reviews, we assess six LLMs, such as GPT and Mixtral, analyzing their classification and generation performance. Our experimental insights into LLM performance on the novel biomedical QA dataset reveal the still challenging nature of this task.
6/11/2024
Multiple Choice Questions and Large Languages Models: A Case Study with Fictional Medical Data
Maxime Griot, Jean Vanderdonckt, Demet Yuksel, Coralie Hemptinne
0
0
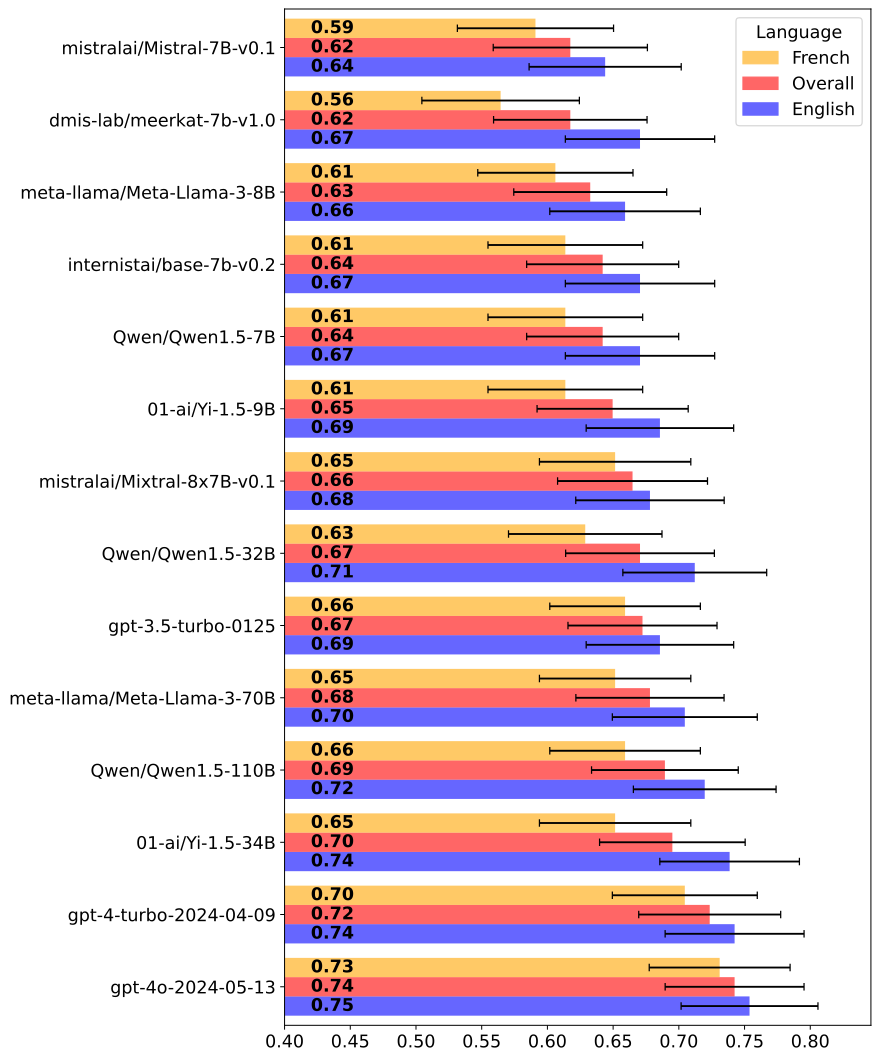
Large Language Models (LLMs) like ChatGPT demonstrate significant potential in the medical field, often evaluated using multiple-choice questions (MCQs) similar to those found on the USMLE. Despite their prevalence in medical education, MCQs have limitations that might be exacerbated when assessing LLMs. To evaluate the effectiveness of MCQs in assessing the performance of LLMs, we developed a fictional medical benchmark focused on a non-existent gland, the Glianorex. This approach allowed us to isolate the knowledge of the LLM from its test-taking abilities. We used GPT-4 to generate a comprehensive textbook on the Glianorex in both English and French and developed corresponding multiple-choice questions in both languages. We evaluated various open-source, proprietary, and domain-specific LLMs using these questions in a zero-shot setting. The models achieved average scores around 67%, with minor performance differences between larger and smaller models. Performance was slightly higher in English than in French. Fine-tuned medical models showed some improvement over their base versions in English but not in French. The uniformly high performance across models suggests that traditional MCQ-based benchmarks may not accurately measure LLMs' clinical knowledge and reasoning abilities, instead highlighting their pattern recognition skills. This study underscores the need for more robust evaluation methods to better assess the true capabilities of LLMs in medical contexts.
6/5/2024
🛸
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
0
0
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
5/30/2024