Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
2404.08695
0
0
Abstract
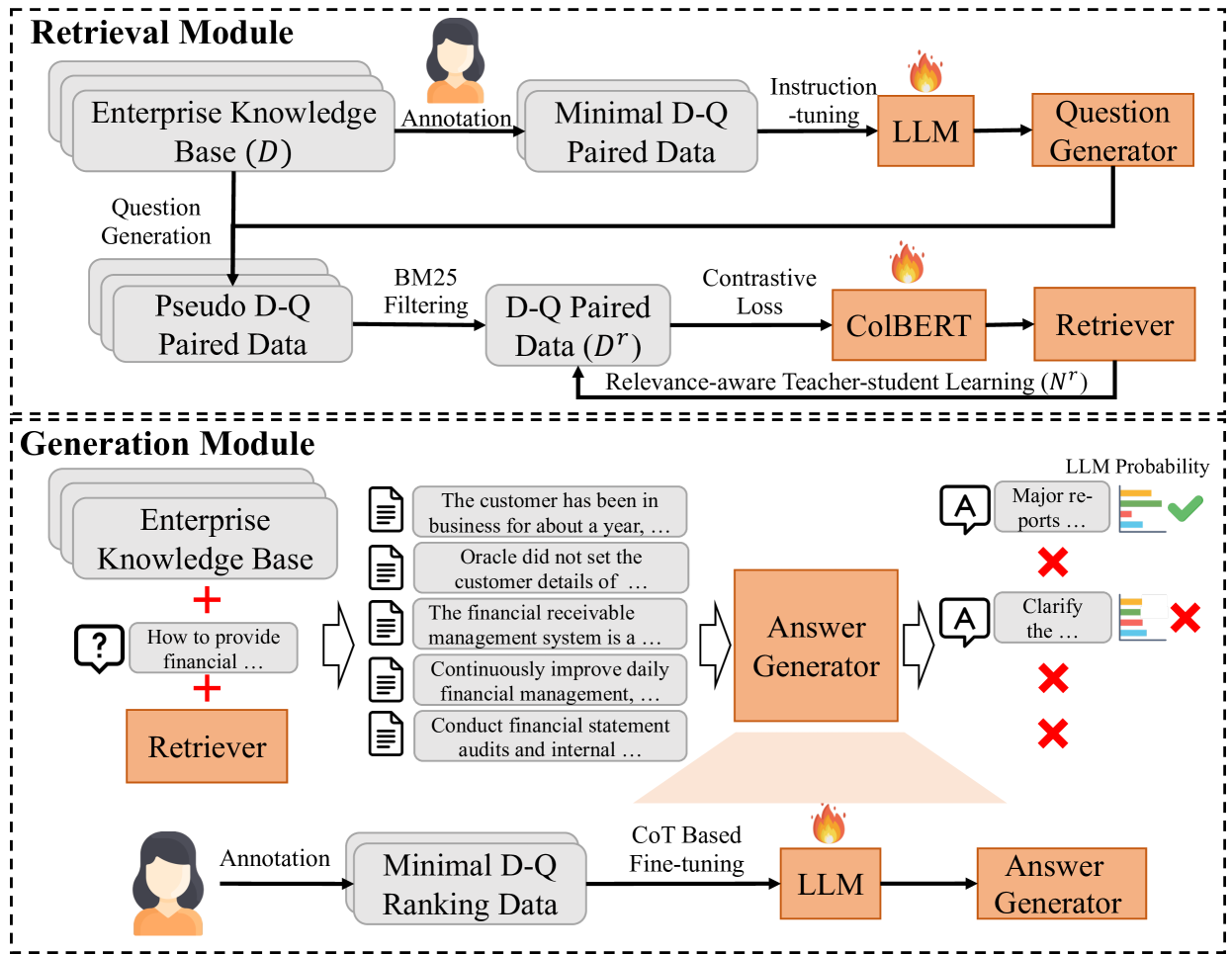
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Create account to get full access
Overview
- The paper explores how to enhance question answering (QA) for enterprise knowledge bases using large language models (LLMs).
- The researchers propose a framework that leverages LLMs to improve QA performance with minimal supervision.
- The paper evaluates the framework on several enterprise QA datasets and demonstrates its effectiveness compared to existing approaches.
Plain English Explanation
The paper focuses on improving the ability of computer systems to answer questions based on the information stored in enterprise knowledge bases. Knowledge bases are collections of structured data that companies use to store and organize important information.
The researchers recognized that while large language models (LLMs) like GPT-3 have shown impressive performance on general question answering tasks, applying them to enterprise knowledge bases can be challenging. LLMs are trained on broad internet data, while enterprise knowledge bases contain more specialized information.
To address this, the researchers developed a framework that can effectively utilize LLMs to enhance question answering for enterprise knowledge bases. Their approach requires only minimal additional training data, making it practical for real-world deployment.
The framework was evaluated on several benchmark datasets for enterprise QA, and the results showed significant improvements over existing methods. This suggests that the researchers' techniques could help companies get more value out of their knowledge bases by making it easier for employees to find the information they need.
Technical Explanation
The paper proposes a novel framework for leveraging large language models to enhance question answering (QA) performance for enterprise knowledge bases. The key components of the framework include:
-
Knowledge Base Encoding: The researchers use a pre-trained LLM to encode the contents of the enterprise knowledge base into a dense vector representation. This allows the model to efficiently reason about the relationships between different knowledge base entities.
-
Question Encoding: Similarly, the framework encodes user questions using the same LLM to capture their semantic meaning.
-
Retrieval and Ranking: Given a user question, the framework retrieves the most relevant knowledge base entries and ranks them based on their similarity to the question. This is achieved through a learned dense retrieval model.
-
Answer Generation: Finally, the framework generates the actual answer to the user's question by conditioning the LLM on the retrieved and ranked knowledge base entries.
The researchers evaluate their framework on several enterprise QA datasets, including ones from the CuriosityLLM and RAG-based QA projects. The results demonstrate significant performance improvements over existing baselines, especially in settings with limited training data.
Critical Analysis
The researchers acknowledge several limitations of their work:
- The framework relies on the availability of a pre-trained LLM, which may not be accessible for all enterprises. Developing effective LLM fine-tuning techniques could help address this challenge.
- The framework was evaluated on English-language datasets, and its performance on other languages is unknown. Extending the approach to multilingual settings would be an important future direction.
- While the framework improves QA performance, it does not directly address the issue of knowledge graph construction from enterprise data. Integrating these two tasks could lead to further advancements.
Additionally, one could question whether the proposed framework sufficiently leverages the skeleton heuristics that are known to boost LLM performance. Exploring more advanced LLM prompting and fine-tuning strategies could potentially lead to even greater improvements.
Conclusion
This paper presents a promising framework for enhancing question answering capabilities for enterprise knowledge bases using large language models. By effectively encoding knowledge base contents and user questions, and then leveraging LLMs for retrieval and answer generation, the researchers demonstrate significant performance gains over existing approaches.
While the framework has some limitations, it represents an important step forward in bridging the gap between general-purpose LLMs and the specialized needs of enterprise knowledge management. Further research in this direction could yield valuable tools for companies looking to maximize the value of their data and information assets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
0
0
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
5/30/2024
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
0
0
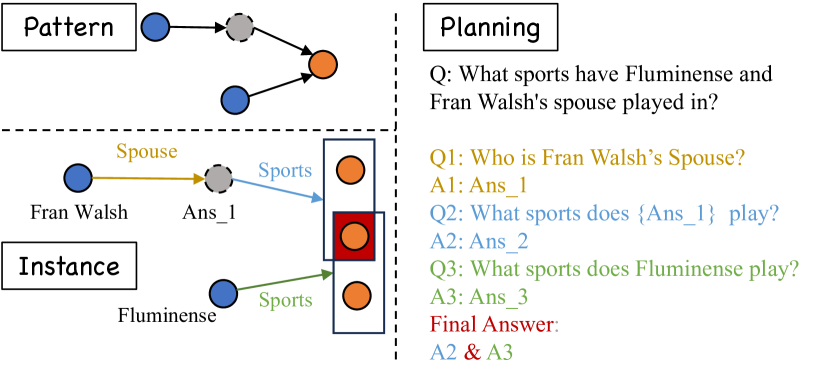
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
6/21/2024
💬
ChatKBQA: A Generate-then-Retrieve Framework for Knowledge Base Question Answering with Fine-tuned Large Language Models
Haoran Luo, Haihong E, Zichen Tang, Shiyao Peng, Yikai Guo, Wentai Zhang, Chenghao Ma, Guanting Dong, Meina Song, Wei Lin, Yifan Zhu, Luu Anh Tuan
0
0
Knowledge Base Question Answering (KBQA) aims to answer natural language questions over large-scale knowledge bases (KBs), which can be summarized into two crucial steps: knowledge retrieval and semantic parsing. However, three core challenges remain: inefficient knowledge retrieval, mistakes of retrieval adversely impacting semantic parsing, and the complexity of previous KBQA methods. To tackle these challenges, we introduce ChatKBQA, a novel and simple generate-then-retrieve KBQA framework, which proposes first generating the logical form with fine-tuned LLMs, then retrieving and replacing entities and relations with an unsupervised retrieval method, to improve both generation and retrieval more directly. Experimental results show that ChatKBQA achieves new state-of-the-art performance on standard KBQA datasets, WebQSP, and CWQ. This work can also be regarded as a new paradigm for combining LLMs with knowledge graphs (KGs) for interpretable and knowledge-required question answering. Our code is publicly available.
5/31/2024
🛸
Retrieval-Augmented Generation with Knowledge Graphs for Customer Service Question Answering
Zhentao Xu, Mark Jerome Cruz, Matthew Guevara, Tie Wang, Manasi Deshpande, Xiaofeng Wang, Zheng Li
0
0
In customer service technical support, swiftly and accurately retrieving relevant past issues is critical for efficiently resolving customer inquiries. The conventional retrieval methods in retrieval-augmented generation (RAG) for large language models (LLMs) treat a large corpus of past issue tracking tickets as plain text, ignoring the crucial intra-issue structure and inter-issue relations, which limits performance. We introduce a novel customer service question-answering method that amalgamates RAG with a knowledge graph (KG). Our method constructs a KG from historical issues for use in retrieval, retaining the intra-issue structure and inter-issue relations. During the question-answering phase, our method parses consumer queries and retrieves related sub-graphs from the KG to generate answers. This integration of a KG not only improves retrieval accuracy by preserving customer service structure information but also enhances answering quality by mitigating the effects of text segmentation. Empirical assessments on our benchmark datasets, utilizing key retrieval (MRR, Recall@K, NDCG@K) and text generation (BLEU, ROUGE, METEOR) metrics, reveal that our method outperforms the baseline by 77.6% in MRR and by 0.32 in BLEU. Our method has been deployed within LinkedIn's customer service team for approximately six months and has reduced the median per-issue resolution time by 28.6%.
5/7/2024