Efficient Privacy-Preserving KAN Inference Using Homomorphic Encryption

0

Sign in to get full access
Overview
- This paper presents an efficient approach for privacy-preserving inference using Kolmogorov-Arnold Networks (KANs) and homomorphic encryption.
- KANs are a type of neural network that can approximate any continuous function, making them suitable for various applications like fraud detection.
- The researchers develop a privacy-preserving KAN inference method that leverages homomorphic encryption to enable computation on encrypted data without decryption.
Plain English Explanation
The paper discusses a way to perform KAN inference while protecting the privacy of the data. KANs are a type of neural network that can approximate any continuous function, making them useful for things like detecting fraud.
The researchers show how to use homomorphic encryption to enable computations on encrypted data without needing to decrypt it first. This allows the KAN inference to be performed in a privacy-preserving manner, where the sensitive input data remains encrypted throughout the process.
The key idea is to modify the standard KAN operations to work with encrypted data, ensuring the results are still accurate even though the inputs are encrypted. This allows the benefits of KANs, like their versatility, to be realized while protecting the privacy of the data.
Technical Explanation
The paper presents an efficient approach for privacy-preserving KAN inference using homomorphic encryption. KANs are a type of neural network that can approximate any continuous function, making them suitable for applications like fraud detection.
The researchers develop a privacy-preserving KAN inference method that leverages homomorphic encryption to enable computations on encrypted data without decryption. They modify the standard KAN operations, including matrix-vector multiplication, activation functions, and output aggregation, to work with encrypted data while maintaining accuracy.
The proposed approach allows KAN inference to be performed in a privacy-preserving manner, where the sensitive input data remains encrypted throughout the process. This is achieved by carefully designing the homomorphic operations to align with the KAN computations, enabling the benefits of KANs, like their versatility, to be realized while protecting the privacy of the data.
Critical Analysis
The paper presents a promising approach for privacy-preserving KAN inference, but there are a few potential limitations and areas for further research:
-
The authors note that the computational overhead of the homomorphic encryption operations may impact the efficiency of the inference process, especially for large-scale applications. Further optimizations or the use of more efficient homomorphic encryption schemes could help address this.
-
The paper focuses on the encryption of input data, but it does not discuss the privacy implications of the intermediate computations or the final output. Ensuring the privacy of these components may require additional considerations or techniques.
-
The evaluation is limited to a single dataset and application (fraud detection). Extending the experiments to a broader range of datasets and use cases would help demonstrate the generalizability and robustness of the approach.
-
The paper does not explore the potential trade-offs between the level of privacy protection and the accuracy or performance of the KAN inference. Investigating these trade-offs could provide valuable insights for real-world deployments.
Conclusion
This paper presents an efficient privacy-preserving KAN inference method that leverages homomorphic encryption. By modifying the standard KAN operations to work with encrypted data, the researchers enable KAN inference to be performed while protecting the privacy of the input data.
The proposed approach has the potential to unlock the benefits of KANs, such as their versatility and ability to approximate complex functions, in privacy-sensitive applications like fraud detection. While the paper identifies some areas for further optimization and exploration, it represents an important step towards bridging the gap between the powerful capabilities of KANs and the growing need for privacy-preserving AI solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Privacy-Preserving KAN Inference Using Homomorphic Encryption
Zhizheng Lai, Yufei Zhou, Peijia Zheng, Lin Chen
The recently proposed Kolmogorov-Arnold Networks (KANs) offer enhanced interpretability and greater model expressiveness. However, KANs also present challenges related to privacy leakage during inference. Homomorphic encryption (HE) facilitates privacy-preserving inference for deep learning models, enabling resource-limited users to benefit from deep learning services while ensuring data security. Yet, the complex structure of KANs, incorporating nonlinear elements like the SiLU activation function and B-spline functions, renders existing privacy-preserving inference techniques inadequate. To address this issue, we propose an accurate and efficient privacy-preserving inference scheme tailored for KANs. Our approach introduces a task-specific polynomial approximation for the SiLU activation function, dynamically adjusting the approximation range to ensure high accuracy on real-world datasets. Additionally, we develop an efficient method for computing B-spline functions within the HE domain, leveraging techniques such as repeat packing, lazy combination, and comparison functions. We evaluate the effectiveness of our privacy-preserving KAN inference scheme on both symbolic formula evaluation and image classification. The experimental results show that our model achieves accuracy comparable to plaintext KANs across various datasets and outperforms plaintext MLPs. Additionally, on the CIFAR-10 dataset, our inference latency achieves over 7 times speedup compared to the naive method.
Read more9/14/2024
🤯
0
Optimized Layerwise Approximation for Efficient Private Inference on Fully Homomorphic Encryption
Junghyun Lee, Eunsang Lee, Young-Sik Kim, Yongwoo Lee, Joon-Woo Lee, Yongjune Kim, Jong-Seon No
Recent studies have explored the deployment of privacy-preserving deep neural networks utilizing homomorphic encryption (HE), especially for private inference (PI). Many works have attempted the approximation-aware training (AAT) approach in PI, changing the activation functions of a model to low-degree polynomials that are easier to compute on HE by allowing model retraining. However, due to constraints in the training environment, it is often necessary to consider post-training approximation (PTA), using the pre-trained parameters of the existing plaintext model without retraining. Existing PTA studies have uniformly approximated the activation function in all layers to a high degree to mitigate accuracy loss from approximation, leading to significant time consumption. This study proposes an optimized layerwise approximation (OLA), a systematic framework that optimizes both accuracy loss and time consumption by using different approximation polynomials for each layer in the PTA scenario. For efficient approximation, we reflect the layerwise impact on the classification accuracy by considering the actual input distribution of each activation function while constructing the optimization problem. Additionally, we provide a dynamic programming technique to solve the optimization problem and achieve the optimized layerwise degrees in polynomial time. As a result, the OLA method reduces inference times for the ResNet-20 model and the ResNet-32 model by 3.02 times and 2.82 times, respectively, compared to prior state-of-the-art implementations employing uniform degree polynomials. Furthermore, we successfully classified CIFAR-10 by replacing the GELU function in the ConvNeXt model with only 3-degree polynomials using the proposed method, without modifying the backbone model.
Read more5/30/2024
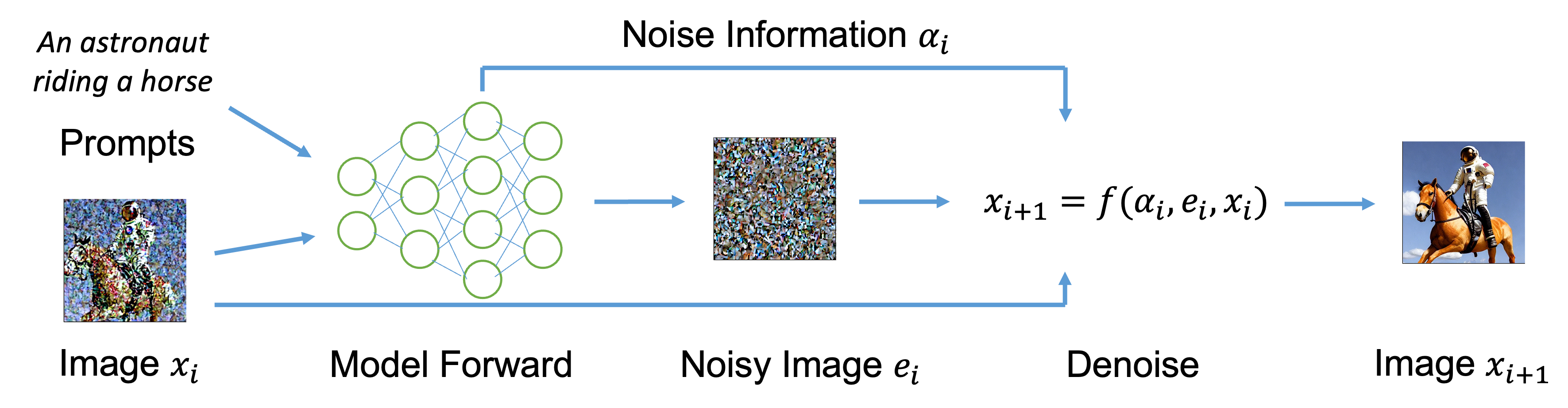
0
Privacy-Preserving Diffusion Model Using Homomorphic Encryption
Yaojian Chen, Qiben Yan
In this paper, we introduce a privacy-preserving stable diffusion framework leveraging homomorphic encryption, called HE-Diffusion, which primarily focuses on protecting the denoising phase of the diffusion process. HE-Diffusion is a tailored encryption framework specifically designed to align with the unique architecture of stable diffusion, ensuring both privacy and functionality. To address the inherent computational challenges, we propose a novel min-distortion method that enables efficient partial image encryption, significantly reducing the overhead without compromising the model's output quality. Furthermore, we adopt a sparse tensor representation to expedite computational operations, enhancing the overall efficiency of the privacy-preserving diffusion process. We successfully implement HE-based privacy-preserving stable diffusion inference. The experimental results show that HE-Diffusion achieves 500 times speedup compared with the baseline method, and reduces time cost of the homomorphically encrypted inference to the minute level. Both the performance and accuracy of the HE-Diffusion are on par with the plaintext counterpart. Our approach marks a significant step towards integrating advanced cryptographic techniques with state-of-the-art generative models, paving the way for privacy-preserving and efficient image generation in critical applications.
Read more5/3/2024

0
Kolmogorov Arnold Networks in Fraud Detection: Bridging the Gap Between Theory and Practice
Yang Lu, Felix Zhan
This study evaluates the applicability of Kolmogorov-Arnold Networks (KAN) in fraud detection, finding that their effectiveness is context-dependent. We propose a quick decision rule using Principal Component Analysis (PCA) to assess the suitability of KAN: if data can be effectively separated in two dimensions using splines, KAN may outperform traditional models; otherwise, other methods could be more appropriate. We also introduce a heuristic approach to hyperparameter tuning, significantly reducing computational costs. These findings suggest that while KAN has potential, its use should be guided by data-specific assessments.
Read more9/5/2024