DNN Memory Footprint Reduction via Post-Training Intra-Layer Multi-Precision Quantization
2404.02947
0
0
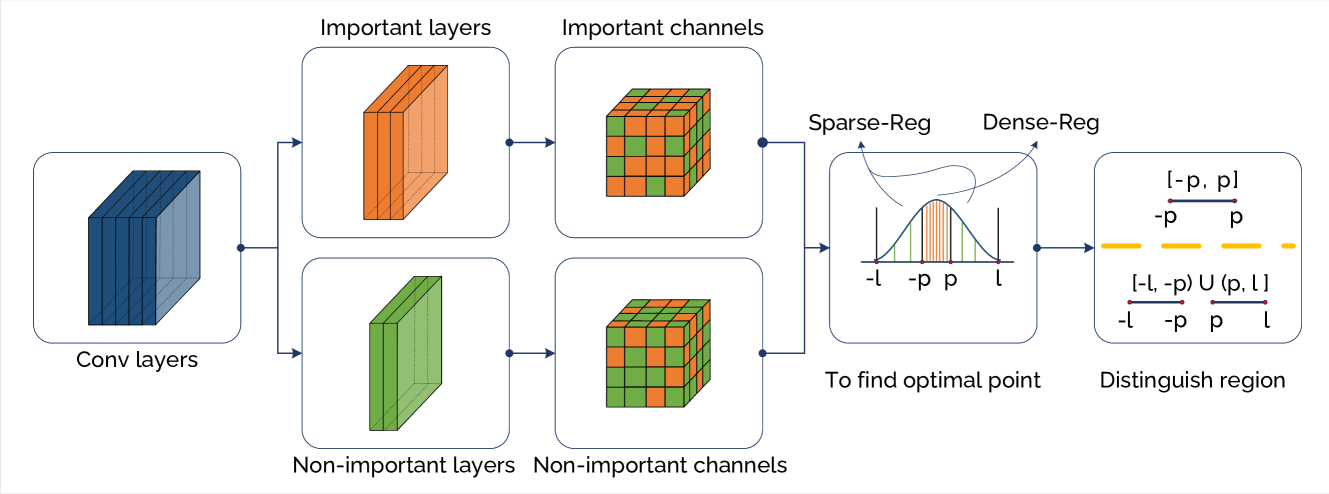
Abstract
The imperative to deploy Deep Neural Network (DNN) models on resource-constrained edge devices, spurred by privacy concerns, has become increasingly apparent. To facilitate the transition from cloud to edge computing, this paper introduces a technique that effectively reduces the memory footprint of DNNs, accommodating the limitations of resource-constrained edge devices while preserving model accuracy. Our proposed technique, named Post-Training Intra-Layer Multi-Precision Quantization (PTILMPQ), employs a post-training quantization approach, eliminating the need for extensive training data. By estimating the importance of layers and channels within the network, the proposed method enables precise bit allocation throughout the quantization process. Experimental results demonstrate that PTILMPQ offers a promising solution for deploying DNNs on edge devices with restricted memory resources. For instance, in the case of ResNet50, it achieves an accuracy of 74.57% with a memory footprint of 9.5 MB, representing a 25.49% reduction compared to previous similar methods, with only a minor 1.08% decrease in accuracy.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Deep neural networks (DNNs) are powerful but have large memory footprints, limiting their use in edge devices
- This paper proposes a method to reduce DNN memory footprint through post-training quantization that allows different layers to use different precisions
- The method can significantly reduce memory usage without sacrificing model accuracy
Plain English Explanation
Deep neural networks are a type of artificial intelligence that can perform impressive tasks like image recognition and language translation. However, these powerful models require a lot of memory to store all the numbers that represent the network's structure and learned knowledge. This large memory footprint makes it difficult to run these models on small, low-power devices like smartphones or sensors.
The researchers in this paper came up with a new way to shrink the memory needed for a neural network, without losing much of its accuracy. Their key insight is that different parts of the network don't need to use the same level of precision (the number of digits used to represent each value). For example, the first layers that just detect simple features might not need as much precision as the later layers that do more complex reasoning.
So the researchers developed a method to automatically decide the best precision to use for each layer, after the network has already been trained. This "post-training" quantization allows them to compress the network in a smart way, tailoring the precision to what each part of the network needs. By using a mix of high and low precision across the layers, they can substantially reduce the overall memory footprint while maintaining the network's performance.
Technical Explanation
The core contribution of this paper is a novel post-training quantization method that allows for intra-layer multi-precision, rather than a uniform precision across the entire network.
The key steps are:
- Analyze the layer-wise distribution of weight and activation values to determine the optimal precision for each layer.
- Quantize the weights and activations to the determined precisions using a custom quantization function.
- Fine-tune the quantized model to recover any accuracy lost during quantization.
The authors evaluate their method on various DNN architectures and datasets. They show significant reductions in model size (up to 4.7x) with negligible accuracy degradation compared to baseline uniform quantization approaches.
Critical Analysis
The authors thoroughly explore the design space and provide extensive experimental results to validate their approach. However, a few caveats are worth noting:
-
The proposed method requires an additional fine-tuning step after quantization, which adds computational overhead. The authors do not provide benchmarks on the training time overhead.
-
The method assumes the availability of a representative validation set to guide the precision allocation. In real-world deployments, obtaining such a validation set may be challenging.
-
While the intra-layer multi-precision approach is effective, the authors do not investigate inter-layer quantization, which could provide further opportunities for optimization.
-
The experiments focus on image classification tasks. It would be valuable to evaluate the method's performance on other domains like natural language processing or reinforcement learning.
Conclusion
This paper presents a novel post-training quantization technique that can significantly reduce the memory footprint of deep neural networks. By adaptively allocating different precisions to different layers, the method achieves substantial model compression without sacrificing model accuracy. The approach has the potential to enable the deployment of powerful DNN models on resource-constrained edge devices, expanding the reach of AI-powered applications. Further research on reducing the computational overhead and exploring inter-layer quantization could further improve the practical applicability of this technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
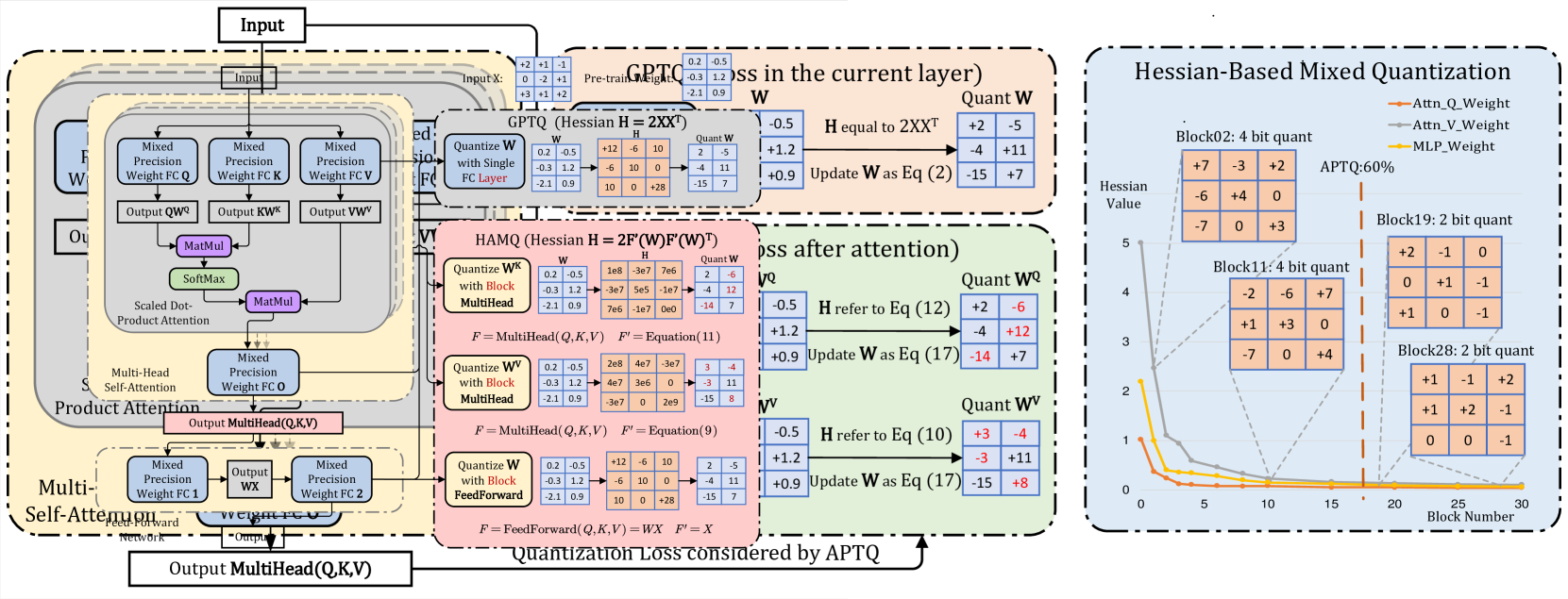
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, Hao Yu
0
0
Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24% and 70.48% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.
4/17/2024
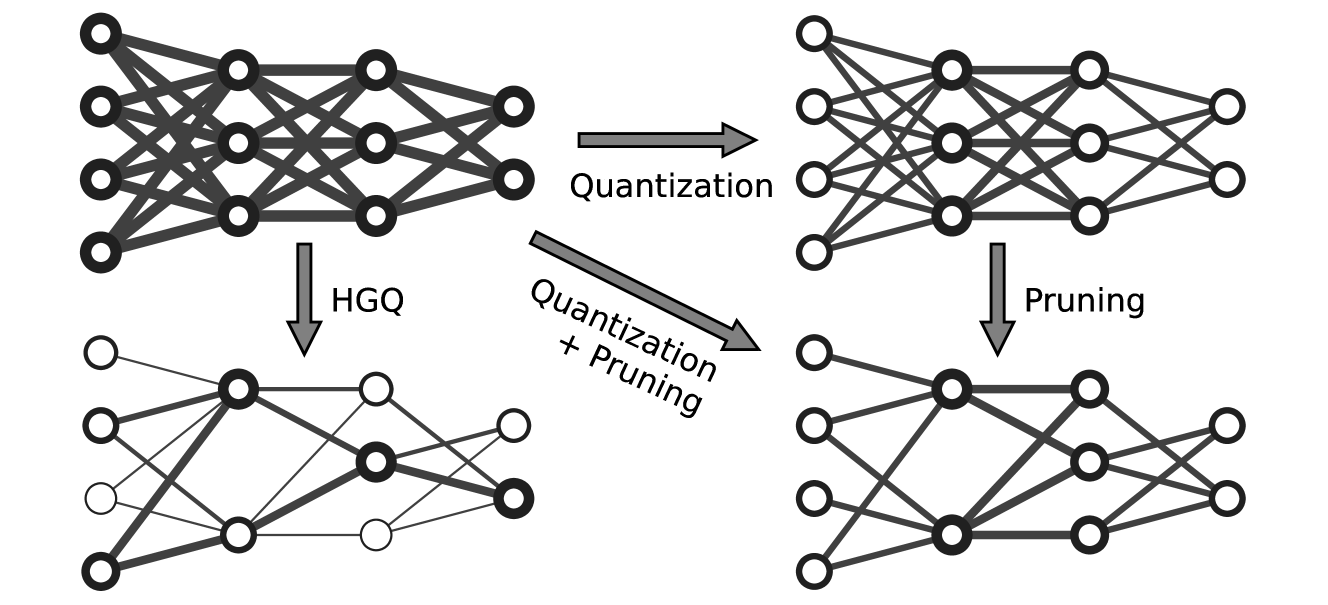
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
Chang Sun, Thea K. {AA}rrestad, Vladimir Loncar, Jennifer Ngadiuba, Maria Spiropulu
0
0
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
5/2/2024
🏋️
On-Device Training Under 256KB Memory
Ji Lin, Ligeng Zhu, Wei-Ming Chen, Wei-Chen Wang, Chuang Gan, Song Han
0
0
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. Users can benefit from customized AI models without having to transfer the data to the cloud, protecting the privacy. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to low bit-precision and the lack of normalization; (2) the limited hardware resource does not allow full back-propagation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize 8-bit quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offload the runtime auto-differentiation to compile time. Our framework is the first solution to enable tiny on-device training of convolutional neural networks under 256KB SRAM and 1MB Flash without auxiliary memory, using less than 1/1000 of the memory of PyTorch and TensorFlow while matching the accuracy on tinyML application VWW. Our study enables IoT devices not only to perform inference but also to continuously adapt to new data for on-device lifelong learning. A video demo can be found here: https://youtu.be/0pUFZYdoMY8.
4/4/2024
🏷️
EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
Yefei He, Jing Liu, Weijia Wu, Hong Zhou, Bohan Zhuang
0
0
Diffusion models have demonstrated remarkable capabilities in image synthesis and related generative tasks. Nevertheless, their practicality for real-world applications is constrained by substantial computational costs and latency issues. Quantization is a dominant way to compress and accelerate diffusion models, where post-training quantization (PTQ) and quantization-aware training (QAT) are two main approaches, each bearing its own properties. While PTQ exhibits efficiency in terms of both time and data usage, it may lead to diminished performance in low bit-width. On the other hand, QAT can alleviate performance degradation but comes with substantial demands on computational and data resources. In this paper, we introduce a data-free and parameter-efficient fine-tuning framework for low-bit diffusion models, dubbed EfficientDM, to achieve QAT-level performance with PTQ-like efficiency. Specifically, we propose a quantization-aware variant of the low-rank adapter (QALoRA) that can be merged with model weights and jointly quantized to low bit-width. The fine-tuning process distills the denoising capabilities of the full-precision model into its quantized counterpart, eliminating the requirement for training data. We also introduce scale-aware optimization and temporal learned step-size quantization to further enhance performance. Extensive experimental results demonstrate that our method significantly outperforms previous PTQ-based diffusion models while maintaining similar time and data efficiency. Specifically, there is only a 0.05 sFID increase when quantizing both weights and activations of LDM-4 to 4-bit on ImageNet 256x256. Compared to QAT-based methods, our EfficientDM also boasts a 16.2x faster quantization speed with comparable generation quality. Code is available at href{https://github.com/ThisisBillhe/EfficientDM}{this hrl}.
4/16/2024