Emergence of Latent Binary Encoding in Deep Neural Network Classifiers
2310.08224
0
0
Abstract
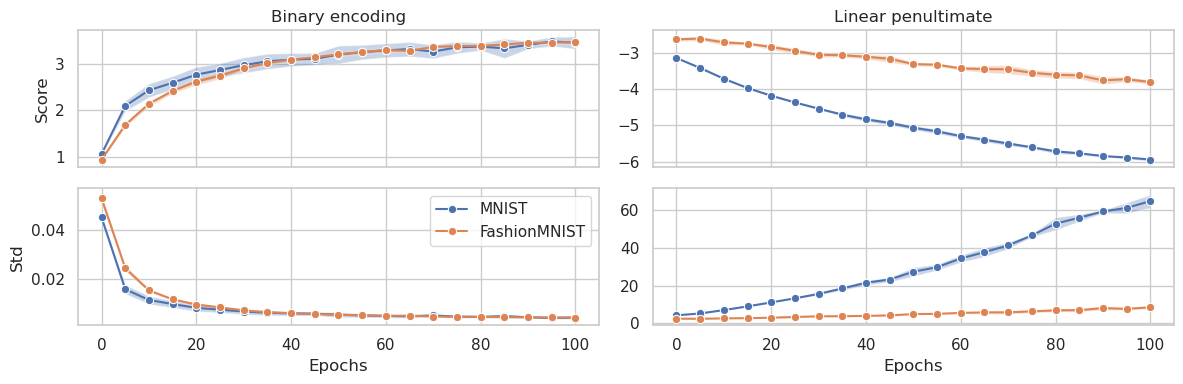
We investigate the emergence of binary encoding within the latent space of deep-neural-network classifiers. Such binary encoding is induced by the introduction of a linear penultimate layer, which employs during training a loss function specifically designed to compress the latent representations. As a result of a trade-off between compression and information retention, the network learns to assume only one of two possible values for each dimension in the latent space. The binary encoding is provoked by the collapse of all representations of the same class to the same point, which corresponds to the vertex of a hypercube. By analyzing several datasets of increasing complexity, we provide empirical evidence that the emergence of binary encoding dramatically enhances robustness while also significantly improving the reliability and generalization of the network.
Create account to get full access
Overview
- Examines the emergence of latent binary encoding in deep neural network classifiers
- Investigates how neural networks learn to represent input data using binary encoding
- Explores the potential implications and applications of this phenomenon
Plain English Explanation
Deep neural networks are powerful machine learning models that can learn to classify and recognize patterns in complex data. This research paper explores an intriguing discovery about how these neural networks sometimes develop an internal representation of the input data using binary encoding.
Binary encoding is a way of representing information using only two values, typically 0 and 1. The researchers found that even when the neural networks were not specifically trained to use binary encoding, they would sometimes spontaneously develop this type of representation in their hidden layers. This suggests that binary encoding may be a natural and efficient way for neural networks to process and store information.
The implications of this discovery could be significant. Binary encoding is a compact and computationally efficient way to represent data, which could lead to more compact and energy-efficient neural network models. It may also provide insights into how the human brain processes and represents information, as the brain is known to rely on binary-like neural signaling.
Additionally, the ability of neural networks to learn binary representations could be leveraged for applications in graph neural networks or Boolean logic-based reasoning, where binary encoding is a natural fit. The research also suggests that compressing the latent space of neural networks may be a fruitful area for further exploration.
Technical Explanation
The researchers conducted a series of experiments to investigate the emergence of latent binary encoding in deep neural network classifiers. They trained various neural network architectures, including convolutional neural networks and multi-layer perceptrons, on image classification tasks using standard datasets like MNIST and CIFAR-10.
During training, the researchers monitored the activations of the hidden layers in the neural networks to see if binary-like representations would emerge. They found that in many cases, the neural networks spontaneously developed binary-like activations, with the values of the hidden units tending to cluster around 0 and 1.
The researchers explored several factors that may influence the emergence of binary encoding, such as the network architecture, the training dataset, and the optimization algorithm. They found that the phenomenon was quite robust and occurred across a range of different settings.
The researchers also investigated the potential benefits of the binary encoding, such as improved computational efficiency and storage requirements. They found that the binary-encoded representations could be used to perform Boolean-like operations, suggesting potential applications in areas like graph neural networks and logic-based reasoning.
Critical Analysis
The researchers provide a thorough and well-designed set of experiments to investigate the emergence of latent binary encoding in deep neural networks. The findings are intriguing and suggest that this phenomenon may be a fundamental property of how these models process and represent information.
However, the paper does not delve deeply into the underlying mechanisms that drive the emergence of binary encoding. It would be helpful to have a more detailed theoretical explanation of why neural networks might naturally gravitate towards this type of representation.
Additionally, the paper does not explore the potential limitations or drawbacks of binary encoding in neural networks. For example, it is possible that the binary-like representations could lose important nuances or information, which could impact the overall performance of the models.
Further research is also needed to fully understand the practical implications and applications of this discovery. While the researchers suggest potential use cases in areas like graph neural networks and Boolean logic, more work is needed to develop and test these ideas.
Overall, this paper makes a valuable contribution to our understanding of how deep neural networks represent and process information. The discovery of latent binary encoding is an intriguing phenomenon that warrants further investigation and could have significant implications for the field of machine learning.
Conclusion
This research paper has uncovered an intriguing phenomenon in deep neural networks: the spontaneous emergence of latent binary encoding. The researchers have demonstrated that even when neural networks are not specifically trained to use binary representation, they sometimes develop this type of internal encoding, suggesting that it may be a natural and efficient way for these models to process and store information.
The implications of this discovery could be far-reaching, potentially leading to more compact and energy-efficient neural network models, as well as providing insights into how the human brain processes information. The ability of neural networks to learn binary representations could also be leveraged for applications in areas like graph neural networks and Boolean logic-based reasoning.
While the paper provides a strong experimental foundation, more research is needed to fully understand the underlying mechanisms and potential limitations of binary encoding in neural networks. Nonetheless, this work represents an important step forward in our understanding of how these powerful machine learning models represent and process complex data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On Training a Neural Network to Explain Binaries
Alexander Interrante-Grant, Andy Davis, Heather Preslier, Tim Leek
0
0
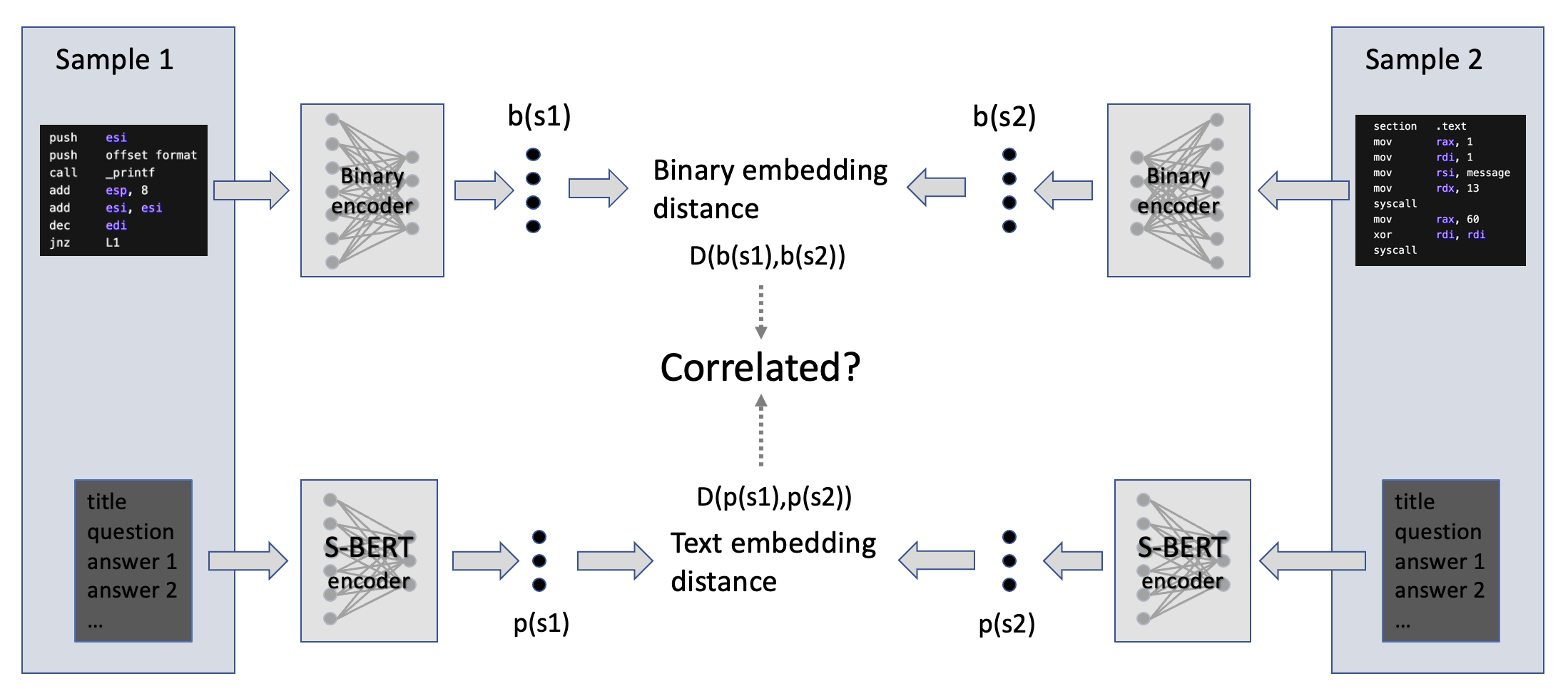
In this work, we begin to investigate the possibility of training a deep neural network on the task of binary code understanding. Specifically, the network would take, as input, features derived directly from binaries and output English descriptions of functionality to aid a reverse engineer in investigating the capabilities of a piece of closed-source software, be it malicious or benign. Given recent success in applying large language models (generative AI) to the task of source code summarization, this seems a promising direction. However, in our initial survey of the available datasets, we found nothing of sufficiently high quality and volume to train these complex models. Instead, we build our own dataset derived from a capture of Stack Overflow containing 1.1M entries. A major result of our work is a novel dataset evaluation method using the correlation between two distances on sample pairs: one distance in the embedding space of inputs and the other in the embedding space of outputs. Intuitively, if two samples have inputs close in the input embedding space, their outputs should also be close in the output embedding space. We found this Embedding Distance Correlation (EDC) test to be highly diagnostic, indicating that our collected dataset and several existing open-source datasets are of low quality as the distances are not well correlated. We proceed to explore the general applicability of EDC, applying it to a number of qualitatively known good datasets and a number of synthetically known bad ones and found it to be a reliable indicator of dataset value.
5/1/2024

Robustly overfitting latents for flexible neural image compression
Yura Perugachi-Diaz, Arwin Gansekoele, Sandjai Bhulai
0
0
Neural image compression has made a great deal of progress. State-of-the-art models are based on variational autoencoders and are outperforming classical models. Neural compression models learn to encode an image into a quantized latent representation that can be efficiently sent to the decoder, which decodes the quantized latent into a reconstructed image. While these models have proven successful in practice, they lead to sub-optimal results due to imperfect optimization and limitations in the encoder and decoder capacity. Recent work shows how to use stochastic Gumbel annealing (SGA) to refine the latents of pre-trained neural image compression models. We extend this idea by introducing SGA+, which contains three different methods that build upon SGA. We show how our method improves the overall compression performance in terms of the R-D trade-off, compared to its predecessors. Additionally, we show how refinement of the latents with our best-performing method improves the compression performance on both the Tecnick and CLIC dataset. Our method is deployed for a pre-trained hyperprior and for a more flexible model. Further, we give a detailed analysis of our proposed methods and show that they are less sensitive to hyperparameter choices. Finally, we show how each method can be extended to three- instead of two-class rounding.
5/27/2024

New!Coding schemes in neural networks learning classification tasks
Alexander van Meegen, Haim Sompolinsky
0
0
Neural networks posses the crucial ability to generate meaningful representations of task-dependent features. Indeed, with appropriate scaling, supervised learning in neural networks can result in strong, task-dependent feature learning. However, the nature of the emergent representations, which we call the `coding scheme', is still unclear. To understand the emergent coding scheme, we investigate fully-connected, wide neural networks learning classification tasks using the Bayesian framework where learning shapes the posterior distribution of the network weights. Consistent with previous findings, our analysis of the feature learning regime (also known as `non-lazy', `rich', or `mean-field' regime) shows that the networks acquire strong, data-dependent features. Surprisingly, the nature of the internal representations depends crucially on the neuronal nonlinearity. In linear networks, an analog coding scheme of the task emerges. Despite the strong representations, the mean predictor is identical to the lazy case. In nonlinear networks, spontaneous symmetry breaking leads to either redundant or sparse coding schemes. Our findings highlight how network properties such as scaling of weights and neuronal nonlinearity can profoundly influence the emergent representations.
6/26/2024

Encoder Embedding for General Graph and Node Classification
Cencheng Shen
0
0
Graph encoder embedding, a recent technique for graph data, offers speed and scalability in producing vertex-level representations from binary graphs. In this paper, we extend the applicability of this method to a general graph model, which includes weighted graphs, distance matrices, and kernel matrices. We prove that the encoder embedding satisfies the law of large numbers and the central limit theorem on a per-observation basis. Under certain condition, it achieves asymptotic normality on a per-class basis, enabling optimal classification through discriminant analysis. These theoretical findings are validated through a series of experiments involving weighted graphs, as well as text and image data transformed into general graph representations using appropriate distance metrics.
5/27/2024