On Training a Neural Network to Explain Binaries
2404.19631
0
0
Abstract
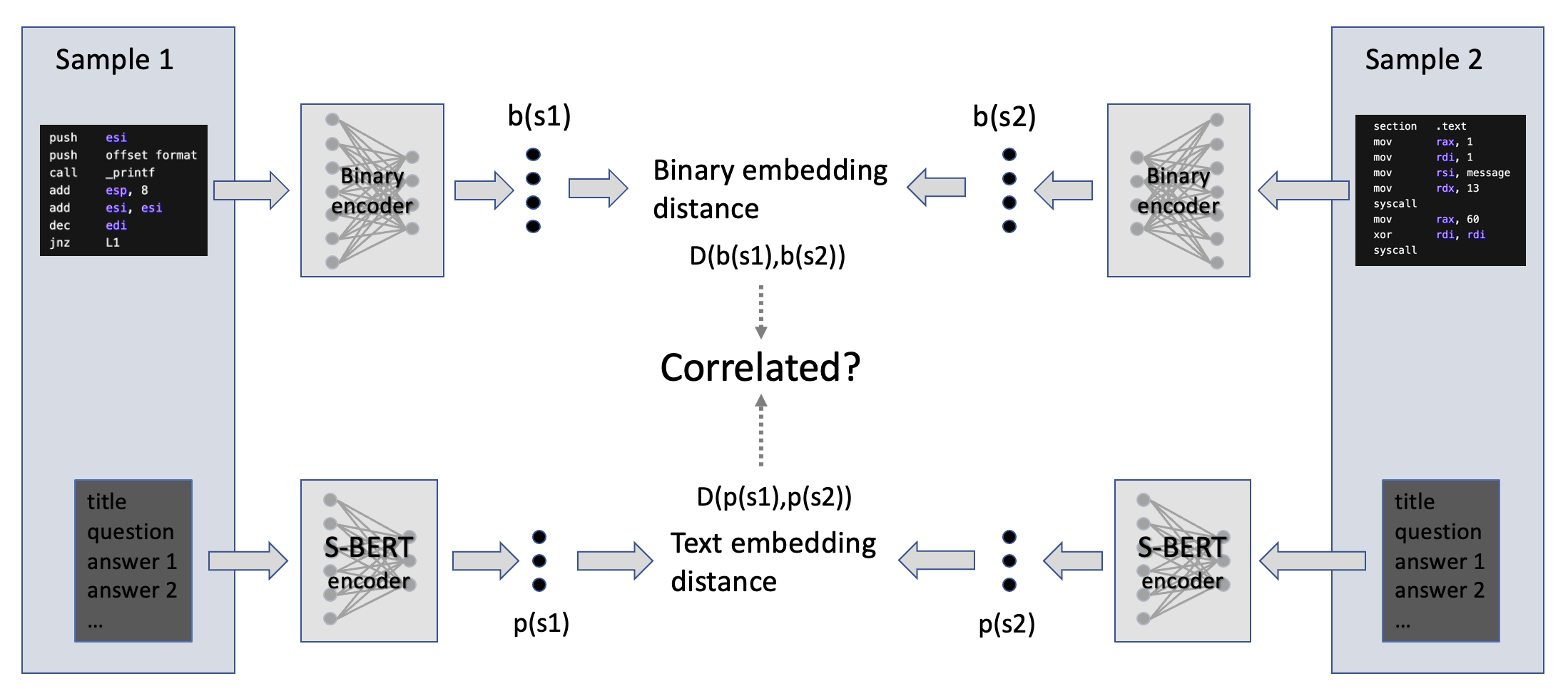
In this work, we begin to investigate the possibility of training a deep neural network on the task of binary code understanding. Specifically, the network would take, as input, features derived directly from binaries and output English descriptions of functionality to aid a reverse engineer in investigating the capabilities of a piece of closed-source software, be it malicious or benign. Given recent success in applying large language models (generative AI) to the task of source code summarization, this seems a promising direction. However, in our initial survey of the available datasets, we found nothing of sufficiently high quality and volume to train these complex models. Instead, we build our own dataset derived from a capture of Stack Overflow containing 1.1M entries. A major result of our work is a novel dataset evaluation method using the correlation between two distances on sample pairs: one distance in the embedding space of inputs and the other in the embedding space of outputs. Intuitively, if two samples have inputs close in the input embedding space, their outputs should also be close in the output embedding space. We found this Embedding Distance Correlation (EDC) test to be highly diagnostic, indicating that our collected dataset and several existing open-source datasets are of low quality as the distances are not well correlated. We proceed to explore the general applicability of EDC, applying it to a number of qualitatively known good datasets and a number of synthetically known bad ones and found it to be a reliable indicator of dataset value.
Create account to get full access
Overview
- This paper explores the use of neural networks to explain the behavior of binary programs, which are computer programs that can only have two possible outputs (e.g., 0 or 1, true or false).
- The researchers aim to develop a system that can analyze binary programs and provide human-readable explanations of how they work, which could be useful for tasks like software debugging, security analysis, and program optimization.
- The paper discusses the challenges of constructing a suitable dataset for this task and presents a method for generating synthetic binary programs with corresponding explanations.
Plain English Explanation
The researchers in this paper are working on a way to help people better understand how computer programs work, especially programs that only have two possible outputs (like "yes" or "no", "true" or "false"). They're using a type of artificial intelligence called a neural network to analyze these binary programs and come up with explanations that a human can understand.
The key idea is that if we can get a neural network to "explain" how a binary program works, it could be really useful for things like finding bugs in software, analyzing computer security, and optimizing program performance. But to train the neural network, the researchers first need to create a dataset of binary programs and their corresponding explanations.
Coming up with this dataset is a big challenge, since binary programs can be very complex and it's not always easy to describe how they work in plain language. The paper presents a method for generating synthetic binary programs and their explanations, which the researchers can then use to train their neural network model.
Technical Explanation
The paper focuses on the task of training a neural network to provide human-readable explanations of binary programs. Binary programs are computer programs that can only have two possible outputs, such as 0 or 1, true or false.
To tackle this problem, the researchers first discuss the challenges of constructing a suitable dataset. Existing datasets of binary programs and their explanations are limited, so the researchers propose a method for generating synthetic binary programs and their corresponding explanations.
The key steps in their approach are:
- Defining a domain-specific language (DSL) to represent binary programs.
- Randomly generating programs in this DSL and automatically deriving their explanations.
- Using the generated programs and explanations to train a neural network model to learn the mapping between binary programs and their explanations.
The researchers experiment with different neural network architectures, including encoder-decoder models and transformers, to find the most effective approach for this task. They evaluate their models on both the synthetic dataset and a small set of real-world binary programs, measuring the quality of the generated explanations.
The results suggest that the proposed approach can successfully train neural networks to provide human-readable explanations for binary programs, though the researchers note that further work is needed to scale this to more complex real-world programs.
Critical Analysis
The research presented in this paper tackles an important problem in the field of program understanding and analysis. Being able to automatically generate human-readable explanations of binary programs could have significant practical applications, such as aiding software debugging, security analysis, and program optimization.
One of the key strengths of the paper is the researchers' approach to constructing a suitable dataset for training the neural network models. By generating synthetic binary programs and their corresponding explanations, they are able to overcome the lack of existing datasets for this task. This is a clever and pragmatic solution, though the researchers acknowledge that the synthetic dataset may not fully capture the complexity of real-world binary programs.
Additionally, the paper explores multiple neural network architectures, including encoder-decoder models and transformers, which is a thorough and systematic approach to finding the most effective model for the task. The results suggest that these models can indeed learn to generate meaningful explanations, but the researchers note that further work is needed to scale this approach to more complex real-world programs.
One potential limitation of the research is the reliance on a domain-specific language (DSL) to represent the binary programs. While this allows for the automated generation of programs and explanations, it may not fully capture the nuances and complexities of real-world binary programs written in lower-level languages like assembly or machine code. Extending the approach to handle a wider range of program representations could be an area for further investigation.
Overall, this paper presents a promising approach to the challenging problem of explaining the inner workings of binary programs. The researchers' focus on constructing a suitable dataset and exploring different neural network architectures is commendable, and the results suggest that this line of research has the potential to yield significant practical benefits in the field of program analysis and understanding.
Conclusion
This paper explores the use of neural networks to automatically generate human-readable explanations of binary programs, which are computer programs that can only have two possible outputs. The researchers propose a method for constructing a synthetic dataset of binary programs and their corresponding explanations, which they then use to train various neural network models.
The results suggest that these models can indeed learn to provide meaningful explanations of binary program behavior, though the researchers note that further work is needed to scale this approach to more complex real-world programs. The potential applications of this research include aiding software debugging, security analysis, and program optimization, which could have a significant impact on the field of program understanding and analysis.
While the paper presents a promising approach, it also highlights the challenges of capturing the full complexity of real-world binary programs using a domain-specific language and synthetic data. Extending the research to handle a wider range of program representations and real-world scenarios could be an interesting direction for future work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Emergence of Latent Binary Encoding in Deep Neural Network Classifiers
Luigi Sbail`o, Luca Ghiringhelli
0
0
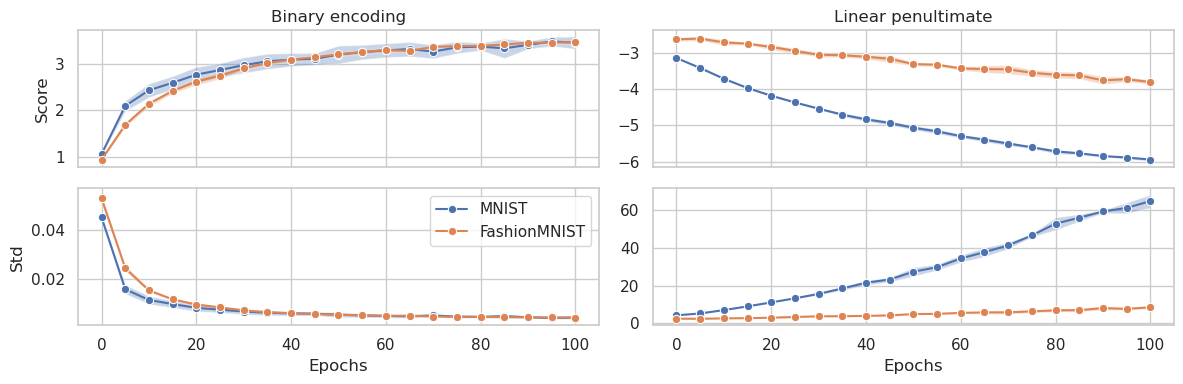
We investigate the emergence of binary encoding within the latent space of deep-neural-network classifiers. Such binary encoding is induced by the introduction of a linear penultimate layer, which employs during training a loss function specifically designed to compress the latent representations. As a result of a trade-off between compression and information retention, the network learns to assume only one of two possible values for each dimension in the latent space. The binary encoding is provoked by the collapse of all representations of the same class to the same point, which corresponds to the vertex of a hypercube. By analyzing several datasets of increasing complexity, we provide empirical evidence that the emergence of binary encoding dramatically enhances robustness while also significantly improving the reliability and generalization of the network.
5/29/2024
Opening the Black Box: predicting the trainability of deep neural networks with reconstruction entropy
Yanick Thurn, Ro Jefferson, Johanna Erdmenger
0
0
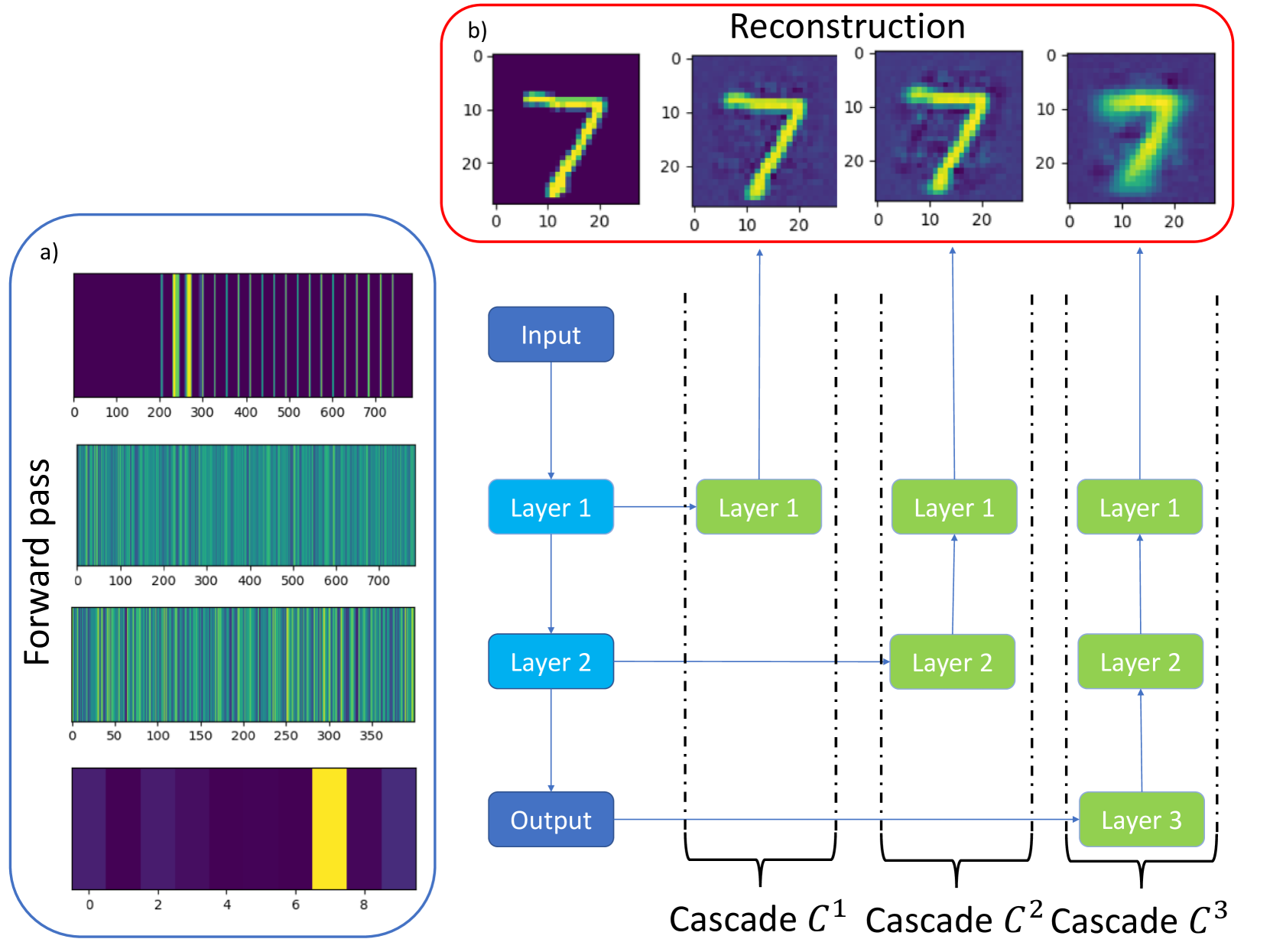
An important challenge in machine learning is to predict the initial conditions under which a given neural network will be trainable. We present a method for predicting the trainable regime in parameter space for deep feedforward neural networks, based on reconstructing the input from subsequent activation layers via a cascade of single-layer auxiliary networks. For both MNIST and CIFAR10, we show that a single epoch of training of the shallow cascade networks is sufficient to predict the trainability of the deep feedforward network, thereby providing a significant reduction in overall training time. We achieve this by computing the relative entropy between reconstructed images and the original inputs, and show that this probe of information loss is sensitive to the phase behaviour of the network. Our results provide a concrete link between the flow of information and the trainability of deep neural networks, further elucidating the role of criticality in these systems.
6/21/2024
📶
Bi-Directional Transformers vs. word2vec: Discovering Vulnerabilities in Lifted Compiled Code
Gary A. McCully, John D. Hastings, Shengjie Xu, Adam Fortier
0
0
Detecting vulnerabilities within compiled binaries is challenging due to lost high-level code structures and other factors such as architectural dependencies, compilers, and optimization options. To address these obstacles, this research explores vulnerability detection by using natural language processing (NLP) embedding techniques with word2vec, BERT, and RoBERTa to learn semantics from intermediate representation (LLVM) code. Long short-term memory (LSTM) neural networks were trained on embeddings from encoders created using approximately 118k LLVM functions from the Juliet dataset. This study is pioneering in its comparison of word2vec models with multiple bidirectional transformer (BERT, RoBERTa) embeddings built using LLVM code to train neural networks to detect vulnerabilities in compiled binaries. word2vec Continuous Bag of Words (CBOW) models achieved 92.3% validation accuracy in detecting vulnerabilities, outperforming word2vec Skip-Gram, BERT, and RoBERTa. This suggests that complex contextual NLP embeddings may not provide advantages over simpler word2vec models for this task when a limited number (e.g. 118K) of data samples are used to train the bidirectional transformer-based models. The comparative results provide novel insights into selecting optimal embeddings for learning compiler-independent semantic code representations to advance machine learning detection of vulnerabilities in compiled binaries.
6/3/2024
🧠
Seeking Interpretability and Explainability in Binary Activated Neural Networks
Benjamin Leblanc, Pascal Germain
0
0
We study the use of binary activated neural networks as interpretable and explainable predictors in the context of regression tasks on tabular data; more specifically, we provide guarantees on their expressiveness, present an approach based on the efficient computation of SHAP values for quantifying the relative importance of the features, hidden neurons and even weights. As the model's simplicity is instrumental in achieving interpretability, we propose a greedy algorithm for building compact binary activated networks. This approach doesn't need to fix an architecture for the network in advance: it is built one layer at a time, one neuron at a time, leading to predictors that aren't needlessly complex for a given task.
6/11/2024