Emergent Abilities in Reduced-Scale Generative Language Models
2404.02204
0
0
Abstract
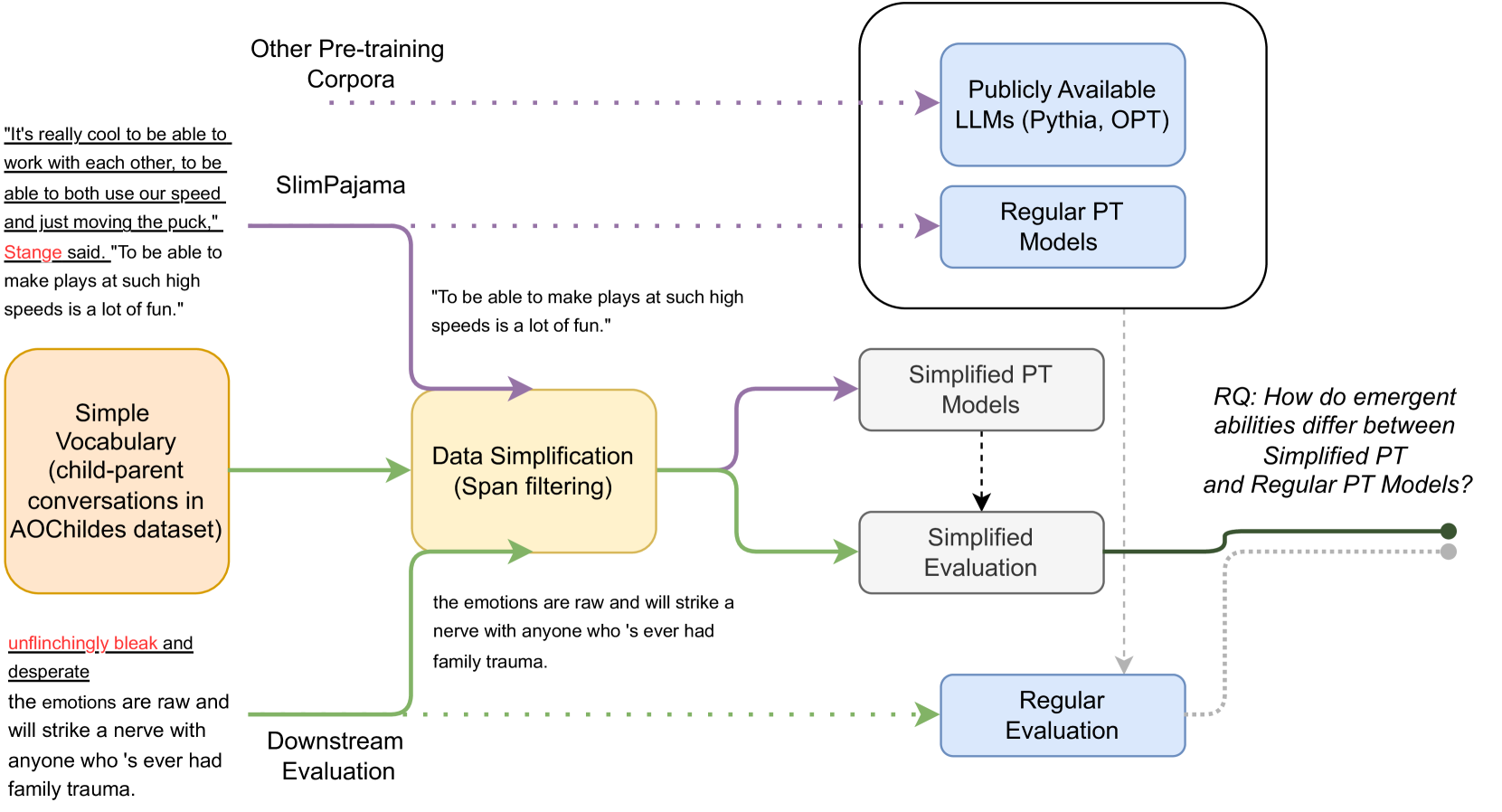
Large language models can solve new tasks without task-specific fine-tuning. This ability, also known as in-context learning (ICL), is considered an emergent ability and is primarily seen in large language models with billions of parameters. This study investigates if such emergent properties are strictly tied to model size or can be demonstrated by smaller models trained on reduced-scale data. To explore this, we simplify pre-training data and pre-train 36 causal language models with parameters varying from 1 million to 165 million parameters. We show that models trained on this simplified pre-training data demonstrate enhanced zero-shot capabilities across various tasks in simplified language, achieving performance comparable to that of pre-trained models six times larger on unrestricted language. This suggests that downscaling the language allows zero-shot learning capabilities to emerge in models with limited size. Additionally, we find that these smaller models pre-trained on simplified data demonstrate a power law relationship between the evaluation loss and the three scaling factors: compute, dataset size, and model size.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Examines the emergence of various abilities in reduced-scale generative language models
- Investigates whether smaller models can exhibit similar capabilities to larger, more complex models
- Findings suggest that even compact language models can develop unexpected skills through training
Plain English Explanation
This research explores whether smaller, more compact language models can develop unexpected capabilities similar to their larger, more complex counterparts. The researchers wanted to see if slimming down the size of a language model would limit its abilities or if it could still exhibit a range of emergent skills.
Language models are AI systems trained on vast amounts of text data to generate human-like language. Typically, the largest and most advanced models tend to display the most sophisticated abilities. However, this study indicates that even reduced-scale models can unexpectedly acquire a variety of skills through training, without needing to be as massive or intricate.
The findings suggest that the development of certain language skills may not be as reliant on model size or complexity as previously thought. Even relatively compact models can surprise researchers by demonstrating unexpected capabilities that go beyond their original purpose. This has implications for making language AI more accessible and efficient, as smaller models could potentially be leveraged for a wider range of applications.
Technical Explanation
The paper examines the emergence of various abilities in reduced-scale generative language models. The researchers trained a series of compact Transformer-based models with varying parameter counts and evaluated their performance across a diverse set of tasks.
The experiment involved training models ranging from 117 million to 1.5 billion parameters on a large corpus of text data. These models were then assessed on a battery of benchmarks, including natural language inference, question answering, code generation, and few-shot learning.
The results indicate that even the smallest 117 million parameter model was able to exhibit a range of unexpected capabilities, matching or exceeding the performance of much larger models on certain tasks. This suggests that the development of certain skills in language models may not be as closely tied to model scale as previously assumed.
The researchers hypothesize that the emergence of these abilities is driven by the models' ability to extract and leverage high-level representations from the training data, rather than simply scaling up model complexity. This points to the potential for compact, efficient language models to deliver sophisticated performance across a variety of applications.
Critical Analysis
The paper provides compelling evidence that reduced-scale language models can develop a surprisingly broad range of skills through training. However, it is worth noting that the study does not delve deeply into the mechanisms underlying this phenomenon or the generalizability of the findings.
For instance, the paper does not explore the extent to which the emergent abilities of the smaller models may be influenced by the specific tasks and benchmarks used in the evaluation. It's possible that the models excel on the selected tasks but may not display the same level of versatility on a more diverse set of challenges.
Additionally, the research does not address potential limitations or caveats of using compact language models in real-world applications. Issues such as robustness, interpretability, and safety considerations are not discussed, which would be important factors to consider before deploying these models in practical settings.
Further research is needed to better understand the factors driving the emergence of capabilities in reduced-scale models and to explore the broader implications for the development of efficient, high-performing language AI systems.
Conclusion
This study presents intriguing findings on the unexpected abilities that can arise in compact generative language models. The results challenge the prevailing notion that model scale and complexity are the primary drivers of sophisticated language skills, suggesting that even slimmed-down models can develop a range of unexpected capabilities through training.
These insights have the potential to inform the development of more efficient and accessible language AI systems, as smaller models could be leveraged for a wider variety of applications. However, further research is needed to fully understand the mechanisms underlying this phenomenon and to explore the practical implications and limitations of using reduced-scale language models in real-world settings.
Overall, this work highlights the importance of continued exploration and experimentation in the field of language AI, as even seemingly modest models may harbor hidden potential waiting to be unveiled.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
An exactly solvable model for emergence and scaling laws
Yoonsoo Nam, Nayara Fonseca, Seok Hyeong Lee, Ard Louis
0
0
Deep learning models can exhibit what appears to be a sudden ability to solve a new problem as training time ($T$), training data ($D$), or model size ($N$) increases, a phenomenon known as emergence. In this paper, we present a framework where each new ability (a skill) is represented as a basis function. We solve a simple multi-linear model in this skill-basis, finding analytic expressions for the emergence of new skills, as well as for scaling laws of the loss with training time, data size, model size, and optimal compute ($C$). We compare our detailed calculations to direct simulations of a two-layer neural network trained on multitask sparse parity, where the tasks in the dataset are distributed according to a power-law. Our simple model captures, using a single fit parameter, the sigmoidal emergence of multiple new skills as training time, data size or model size increases in the neural network.
4/29/2024
Scaling Properties of Speech Language Models
Santiago Cuervo, Ricard Marxer
0
0
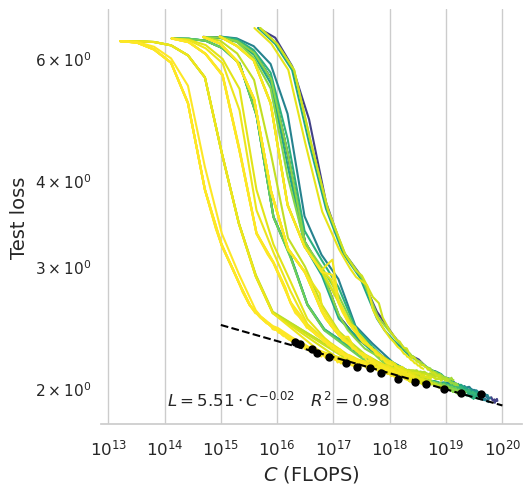
Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
4/17/2024
Collapse of Self-trained Language Models
David Herel, Tomas Mikolov
0
0
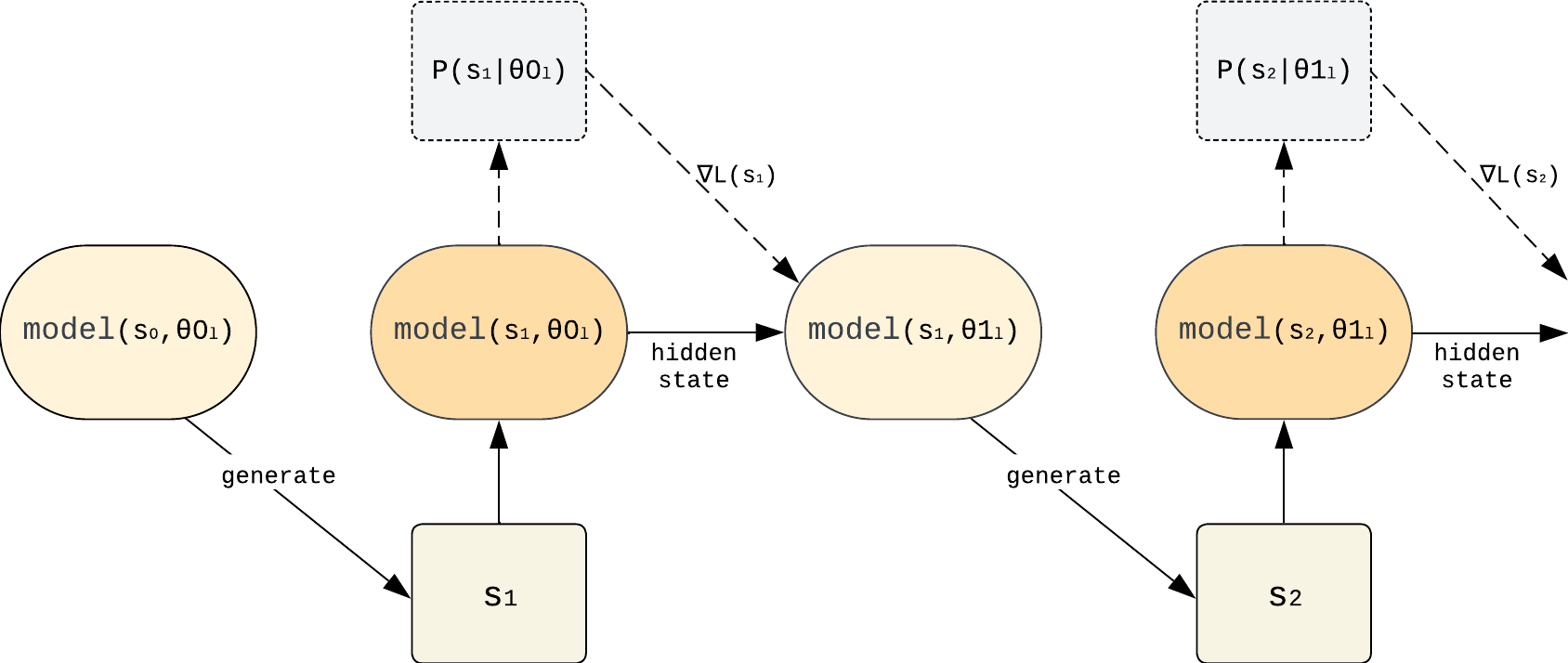
In various fields of knowledge creation, including science, new ideas often build on pre-existing information. In this work, we explore this concept within the context of language models. Specifically, we explore the potential of self-training models on their own outputs, akin to how humans learn and build on their previous thoughts and actions. While this approach is intuitively appealing, our research reveals its practical limitations. We find that extended self-training of the GPT-2 model leads to a significant degradation in performance, resulting in repetitive and collapsed token output.
4/4/2024
Auxiliary task demands mask the capabilities of smaller language models
Jennifer Hu, Michael C. Frank
0
0
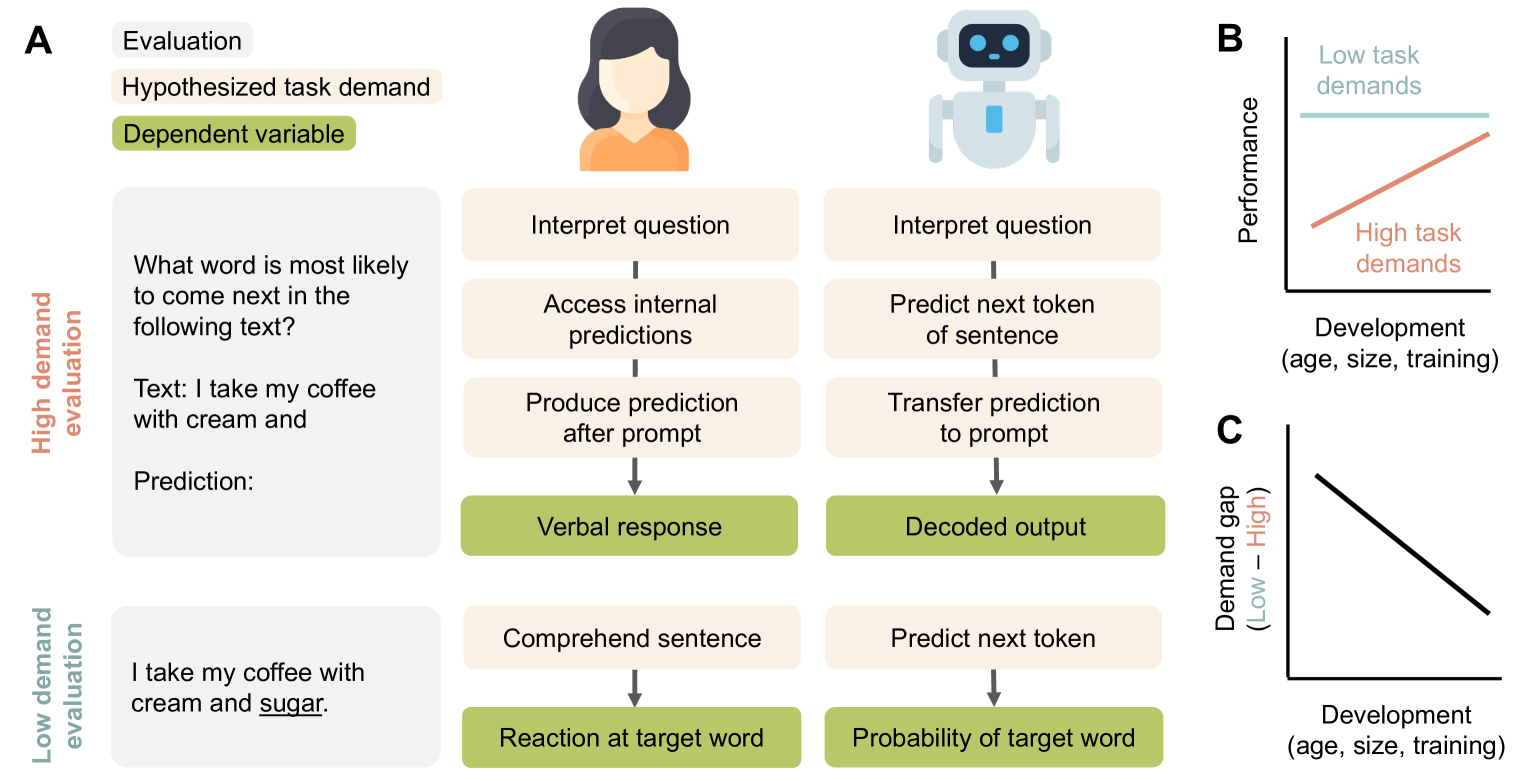
Developmental psychologists have argued about when cognitive capacities such as language understanding or theory of mind emerge. These debates often hinge on the concept of task demands -- the auxiliary challenges associated with performing a particular evaluation -- that may mask the child's underlying ability. The same issues arise when measuring the capacities of language models (LMs): performance on a task is a function of the model's underlying competence, combined with the model's ability to interpret and perform the task given its available resources. Here, we show that for analogical reasoning, reflective reasoning, word prediction, and grammaticality judgments, evaluation methods with greater task demands yield lower performance than evaluations with reduced demands. This demand gap is most pronounced for models with fewer parameters and less training data. Our results illustrate that LM performance should not be interpreted as a direct indication of intelligence (or lack thereof), but as a reflection of capacities seen through the lens of researchers' design choices.
4/4/2024