EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning

0

Sign in to get full access
Overview
- EMO-LLaMA is a new model that enhances facial emotion understanding by incorporating instruction tuning.
- It builds upon the LLaMA language model to create a multimodal system capable of recognizing and reasoning about emotional expressions.
- The key innovations include adapting LLaMA to the facial emotion recognition task and leveraging instruction tuning to improve performance.
Plain English Explanation
EMO-LLaMA is a machine learning model that aims to better understand human emotions based on facial expressions. It takes the powerful LLaMA language model and customizes it to work with visual data, specifically images of faces.
The core idea is to teach the model not just to recognize different emotional states like happiness, sadness, or anger, but to also reason about the context and meaning behind those expressions. This is done through a technique called "instruction tuning," where the model is given specific prompts and training examples to help it learn the nuances of emotional interpretation.
By combining language understanding with visual perception, EMO-LLaMA can analyze facial cues in a more holistic and contextual way. This could have applications in areas like mental health monitoring, customer service, or human-robot interaction, where accurately reading and responding to emotions is important.
The researchers believe this multimodal approach represents an important step towards building AI systems that can communicate and interact with humans in a more natural, empathetic way.
Technical Explanation
The EMO-LLaMA model is built upon the LLaMA language model, which is then adapted and "instruction tuned" for the task of facial emotion recognition and reasoning.
The core architecture includes:
- A visual encoder that processes facial image inputs
- A language model (the adapted LLaMA) that reasons about the emotional context
- A fusion module that combines the visual and language representations
The key innovation is the instruction tuning process, where the model is trained on a diverse set of tasks and prompts related to emotional understanding. This includes classifying basic emotions, describing emotional states, and answering questions that require reasoning about the meaning behind facial expressions.
By exposing the model to this rich set of instructions and examples, EMO-LLaMA is able to learn more nuanced emotional perception skills beyond just simple classification. The experiments show this approach outperforms prior facial emotion recognition models on various benchmarks.
Critical Analysis
The EMO-LLaMA research represents an interesting step towards building more socially intelligent AI systems. The ability to understand emotions from facial cues, and reason about their context and implications, is an important capability for AI to develop.
However, the paper also acknowledges some limitations. The model was trained and evaluated on relatively constrained datasets, so its performance in real-world, unconstrained scenarios is still an open question. There are also concerns about potential biases in the training data and how that might affect the model's emotional understanding.
Additionally, the ethical implications of this type of technology merit careful consideration. Emotion recognition AI could be used for surveillance, manipulation, or other problematic applications if not developed and deployed responsibly. The authors briefly touch on these concerns but more in-depth discussion would be valuable.
Overall, the EMO-LLaMA research is a promising advance, but there remains significant work to be done to ensure these models are safe, unbiased, and beneficial to society.
Conclusion
EMO-LLaMA represents an innovative approach to enhancing facial emotion understanding through the use of instruction tuning and multimodal learning. By combining language comprehension with visual perception, the model can analyze emotional expressions in a more contextual and nuanced way.
This work has the potential to enable AI systems that can communicate and interact with humans more naturally and empathetically. However, the researchers also acknowledge important caveats and ethical considerations that must be addressed as this technology continues to develop.
Overall, EMO-LLaMA is an exciting step forward, but there remains much more work to be done to fully realize the promise of emotionally intelligent AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EMO-LLaMA: Enhancing Facial Emotion Understanding with Instruction Tuning
Bohao Xing, Zitong Yu, Xin Liu, Kaishen Yuan, Qilang Ye, Weicheng Xie, Huanjing Yue, Jingyu Yang, Heikki Kalviainen
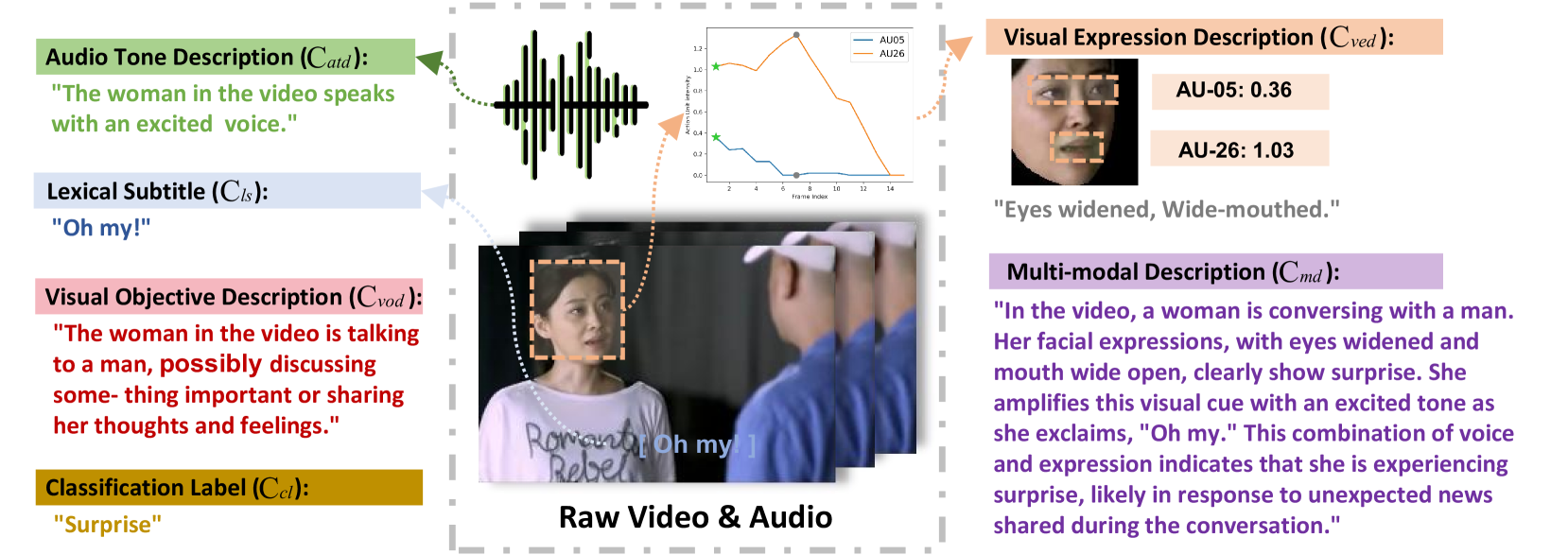
Facial expression recognition (FER) is an important research topic in emotional artificial intelligence. In recent decades, researchers have made remarkable progress. However, current FER paradigms face challenges in generalization, lack semantic information aligned with natural language, and struggle to process both images and videos within a unified framework, making their application in multimodal emotion understanding and human-computer interaction difficult. Multimodal Large Language Models (MLLMs) have recently achieved success, offering advantages in addressing these issues and potentially overcoming the limitations of current FER paradigms. However, directly applying pre-trained MLLMs to FER still faces several challenges. Our zero-shot evaluations of existing open-source MLLMs on FER indicate a significant performance gap compared to GPT-4V and current supervised state-of-the-art (SOTA) methods. In this paper, we aim to enhance MLLMs' capabilities in understanding facial expressions. We first generate instruction data for five FER datasets with Gemini. We then propose a novel MLLM, named EMO-LLaMA, which incorporates facial priors from a pretrained facial analysis network to enhance human facial information. Specifically, we design a Face Info Mining module to extract both global and local facial information. Additionally, we utilize a handcrafted prompt to introduce age-gender-race attributes, considering the emotional differences across different human groups. Extensive experiments show that EMO-LLaMA achieves SOTA-comparable or competitive results across both static and dynamic FER datasets. The instruction dataset and code are available at https://github.com/xxtars/EMO-LLaMA.
Read more8/22/2024
0
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
Read more6/18/2024

0
Facial Affective Behavior Analysis with Instruction Tuning
Yifan Li, Anh Dao, Wentao Bao, Zhen Tan, Tianlong Chen, Huan Liu, Yu Kong
Facial affective behavior analysis (FABA) is crucial for understanding human mental states from images. However, traditional approaches primarily deploy models to discriminate among discrete emotion categories, and lack the fine granularity and reasoning capability for complex facial behaviors. The advent of Multi-modal Large Language Models (MLLMs) has been proven successful in general visual understanding tasks. However, directly harnessing MLLMs for FABA is challenging due to the scarcity of datasets and benchmarks, neglecting facial prior knowledge, and low training efficiency. To address these challenges, we introduce (i) an instruction-following dataset for two FABA tasks, e.g., emotion and action unit recognition, (ii) a benchmark FABA-Bench with a new metric considering both recognition and generation ability, and (iii) a new MLLM EmoLA as a strong baseline to the community. Our initiative on the dataset and benchmarks reveal the nature and rationale of facial affective behaviors, i.e., fine-grained facial movement, interpretability, and reasoning. Moreover, to build an effective and efficient FABA MLLM, we introduce a facial prior expert module with face structure knowledge and a low-rank adaptation module into pre-trained MLLM. We conduct extensive experiments on FABA-Bench and four commonly-used FABA datasets. The results demonstrate that the proposed facial prior expert can boost the performance and EmoLA achieves the best results on our FABA-Bench. On commonly-used FABA datasets, EmoLA is competitive rivaling task-specific state-of-the-art models.
Read more7/15/2024
💬
0
EmoLLMs: A Series of Emotional Large Language Models and Annotation Tools for Comprehensive Affective Analysis
Zhiwei Liu, Kailai Yang, Tianlin Zhang, Qianqian Xie, Sophia Ananiadou
Sentiment analysis and emotion detection are important research topics in natural language processing (NLP) and benefit many downstream tasks. With the widespread application of LLMs, researchers have started exploring the application of LLMs based on instruction-tuning in the field of sentiment analysis. However, these models only focus on single aspects of affective classification tasks (e.g. sentimental polarity or categorical emotions), and overlook the regression tasks (e.g. sentiment strength or emotion intensity), which leads to poor performance in downstream tasks. The main reason is the lack of comprehensive affective instruction tuning datasets and evaluation benchmarks, which cover various affective classification and regression tasks. Moreover, although emotional information is useful for downstream tasks, existing downstream datasets lack high-quality and comprehensive affective annotations. In this paper, we propose EmoLLMs, the first series of open-sourced instruction-following LLMs for comprehensive affective analysis based on fine-tuning various LLMs with instruction data, the first multi-task affective analysis instruction dataset (AAID) with 234K data samples based on various classification and regression tasks to support LLM instruction tuning, and a comprehensive affective evaluation benchmark (AEB) with 14 tasks from various sources and domains to test the generalization ability of LLMs. We propose a series of EmoLLMs by fine-tuning LLMs with AAID to solve various affective instruction tasks. We compare our model with a variety of LLMs on AEB, where our models outperform all other open-sourced LLMs, and surpass ChatGPT and GPT-4 in most tasks, which shows that the series of EmoLLMs achieve the ChatGPT-level and GPT-4-level generalization capabilities on affective analysis tasks, and demonstrates our models can be used as affective annotation tools.
Read more6/19/2024