An Empirical Study on the Fairness of Foundation Models for Multi-Organ Image Segmentation

0

Sign in to get full access
Overview
- This paper presents an empirical study on the fairness of foundation models, specifically the Segment Anything Model (SAM), for multi-organ image segmentation in medical imaging.
- The study focuses on evaluating the fairness and performance of SAM across different patient demographics, such as age, gender, and ethnicity, to understand its potential biases.
- The research aims to provide insights into the fairness and reliability of foundation models in the critical domain of medical image analysis.
Plain English Explanation
Medical image segmentation is a crucial task in healthcare, where computer algorithms are used to identify and outline different organs and structures within medical scans. Recent advancements in deep learning and foundation models have led to significant improvements in the accuracy and efficiency of these algorithms.
However, as these models become more widely adopted, it's important to ensure that they are fair and unbiased, treating all patients equally regardless of factors like age, gender, or ethnicity. This paper investigates the fairness of the Segment Anything Model (SAM), a powerful foundation model for medical image segmentation, across different patient demographics.
The researchers conducted a comprehensive evaluation of SAM's performance on a large dataset of medical images, looking at factors like segmentation accuracy, false positive rates, and other metrics to assess its fairness. They found that while SAM generally performed well, there were some disparities in its performance for certain patient subgroups.
These findings highlight the importance of carefully evaluating the fairness of AI models used in healthcare, especially as foundation models become more widely adopted. By understanding and addressing potential biases, researchers and clinicians can ensure that these powerful tools are used equitably and effectively to improve patient outcomes.
Technical Explanation
The paper presents a detailed empirical study on the fairness of the Segment Anything Model (SAM) for multi-organ image segmentation in the medical domain. The researchers used a large-scale dataset of medical images to evaluate the performance of SAM across different patient demographics, including age, gender, and ethnicity.
The experimental setup involved training and evaluating SAM on the FairSeg dataset, a comprehensive dataset designed to assess the fairness of medical image segmentation models. The researchers measured various fairness and performance metrics, such as segmentation accuracy, false positive rates, and Dice scores, to assess SAM's fairness and reliability across different patient subgroups.
The key findings of the study include:
- Overall Performance: SAM demonstrated strong overall performance on the FairSeg dataset, achieving high segmentation accuracy and Dice scores across multiple organs.
- Fairness Evaluation: The researchers identified some disparities in SAM's performance for certain patient subgroups, particularly related to age and ethnicity. These findings highlight the importance of comprehensive fairness evaluations for AI models used in healthcare.
- Potential Biases: The researchers discussed potential sources of bias in the training data and model architecture that may have contributed to the observed fairness issues, and provided recommendations for mitigating these biases in future model development.
The insights from this study contribute to the growing body of research on the fairness and reliability of foundation models for medical image analysis. The findings underscore the need for thorough fairness evaluations and the development of strategies to ensure that these powerful AI tools are deployed equitably and benefit all patients, regardless of their demographic characteristics.
Critical Analysis
The paper presents a comprehensive and well-designed study on the fairness of the Segment Anything Model (SAM) for multi-organ image segmentation. The researchers' use of the FairSeg dataset, a large-scale and diverse dataset specifically designed for fairness evaluation, is a key strength of the study. This allows for a more rigorous and meaningful assessment of the model's performance across different patient subgroups.
One potential limitation of the study is the reliance on a single foundation model, SAM, for the fairness evaluation. It would be valuable to expand the analysis to include other state-of-the-art foundation models for medical image segmentation, such as those discussed in this paper, to gain a broader understanding of the fairness landscape in this domain.
Additionally, while the paper provides insights into potential sources of bias in the model and dataset, more detailed investigations into the specific factors contributing to the observed fairness issues could further strengthen the analysis. Exploring the impact of training data composition and model architecture on fairness could yield valuable insights for future model development.
Overall, the study represents an important step in understanding the fairness of foundation models in medical image analysis. The findings highlight the need for continued research and development in this area to ensure that these powerful AI tools are deployed equitably and benefit all patients, regardless of their demographic characteristics.
Conclusion
This empirical study on the fairness of the Segment Anything Model (SAM) for multi-organ image segmentation provides valuable insights into the performance and reliability of foundation models in the critical domain of medical imaging. The researchers' comprehensive evaluation of SAM's fairness across different patient demographics, using the FairSeg dataset, reveals both the strengths and limitations of this powerful model.
The key takeaways from this study include the importance of thorough fairness evaluations for AI models used in healthcare, the need to address potential sources of bias in both training data and model architecture, and the ongoing challenge of ensuring that foundation models are deployed equitably to benefit all patients. As foundation models continue to transform medical image analysis, this research serves as a valuable roadmap for researchers and clinicians to navigate the complex landscape of fairness in AI-powered healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Empirical Study on the Fairness of Foundation Models for Multi-Organ Image Segmentation
Qin Li, Yizhe Zhang, Yan Li, Jun Lyu, Meng Liu, Longyu Sun, Mengting Sun, Qirong Li, Wenyue Mao, Xinran Wu, Yajing Zhang, Yinghua Chu, Shuo Wang, Chengyan Wang
The segmentation foundation model, e.g., Segment Anything Model (SAM), has attracted increasing interest in the medical image community. Early pioneering studies primarily concentrated on assessing and improving SAM's performance from the perspectives of overall accuracy and efficiency, yet little attention was given to the fairness considerations. This oversight raises questions about the potential for performance biases that could mirror those found in task-specific deep learning models like nnU-Net. In this paper, we explored the fairness dilemma concerning large segmentation foundation models. We prospectively curate a benchmark dataset of 3D MRI and CT scans of the organs including liver, kidney, spleen, lung and aorta from a total of 1056 healthy subjects with expert segmentations. Crucially, we document demographic details such as gender, age, and body mass index (BMI) for each subject to facilitate a nuanced fairness analysis. We test state-of-the-art foundation models for medical image segmentation, including the original SAM, medical SAM and SAT models, to evaluate segmentation efficacy across different demographic groups and identify disparities. Our comprehensive analysis, which accounts for various confounding factors, reveals significant fairness concerns within these foundational models. Moreover, our findings highlight not only disparities in overall segmentation metrics, such as the Dice Similarity Coefficient but also significant variations in the spatial distribution of segmentation errors, offering empirical evidence of the nuanced challenges in ensuring fairness in medical image segmentation.
Read more6/19/2024
🖼️
0
FairSeg: A Large-Scale Medical Image Segmentation Dataset for Fairness Learning Using Segment Anything Model with Fair Error-Bound Scaling
Yu Tian, Min Shi, Yan Luo, Ava Kouhana, Tobias Elze, Mengyu Wang
Fairness in artificial intelligence models has gained significantly more attention in recent years, especially in the area of medicine, as fairness in medical models is critical to people's well-being and lives. High-quality medical fairness datasets are needed to promote fairness learning research. Existing medical fairness datasets are all for classification tasks, and no fairness datasets are available for medical segmentation, while medical segmentation is an equally important clinical task as classifications, which can provide detailed spatial information on organ abnormalities ready to be assessed by clinicians. In this paper, we propose the first fairness dataset for medical segmentation named Harvard-FairSeg with 10,000 subject samples. In addition, we propose a fair error-bound scaling approach to reweight the loss function with the upper error-bound in each identity group, using the segment anything model (SAM). We anticipate that the segmentation performance equity can be improved by explicitly tackling the hard cases with high training errors in each identity group. To facilitate fair comparisons, we utilize a novel equity-scaled segmentation performance metric to compare segmentation metrics in the context of fairness, such as the equity-scaled Dice coefficient. Through comprehensive experiments, we demonstrate that our fair error-bound scaling approach either has superior or comparable fairness performance to the state-of-the-art fairness learning models. The dataset and code are publicly accessible via https://ophai.hms.harvard.edu/datasets/harvard-fairseg10k.
Read more5/2/2024

0
FairMedFM: Fairness Benchmarking for Medical Imaging Foundation Models
Ruinan Jin, Zikang Xu, Yuan Zhong, Qiongsong Yao, Qi Dou, S. Kevin Zhou, Xiaoxiao Li
The advent of foundation models (FMs) in healthcare offers unprecedented opportunities to enhance medical diagnostics through automated classification and segmentation tasks. However, these models also raise significant concerns about their fairness, especially when applied to diverse and underrepresented populations in healthcare applications. Currently, there is a lack of comprehensive benchmarks, standardized pipelines, and easily adaptable libraries to evaluate and understand the fairness performance of FMs in medical imaging, leading to considerable challenges in formulating and implementing solutions that ensure equitable outcomes across diverse patient populations. To fill this gap, we introduce FairMedFM, a fairness benchmark for FM research in medical imaging.FairMedFM integrates with 17 popular medical imaging datasets, encompassing different modalities, dimensionalities, and sensitive attributes. It explores 20 widely used FMs, with various usages such as zero-shot learning, linear probing, parameter-efficient fine-tuning, and prompting in various downstream tasks -- classification and segmentation. Our exhaustive analysis evaluates the fairness performance over different evaluation metrics from multiple perspectives, revealing the existence of bias, varied utility-fairness trade-offs on different FMs, consistent disparities on the same datasets regardless FMs, and limited effectiveness of existing unfairness mitigation methods. Checkout FairMedFM's project page and open-sourced codebase, which supports extendible functionalities and applications as well as inclusive for studies on FMs in medical imaging over the long term.
Read more7/4/2024
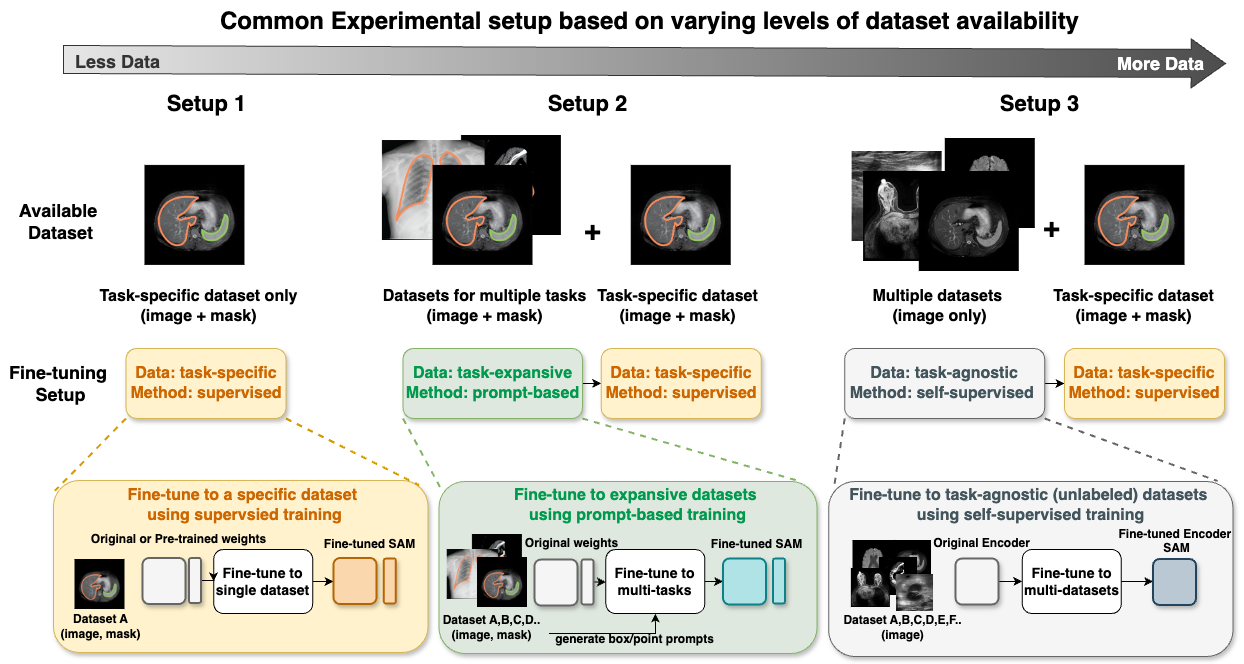
0
How to build the best medical image segmentation algorithm using foundation models: a comprehensive empirical study with Segment Anything Model
Hanxue Gu, Haoyu Dong, Jichen Yang, Maciej A. Mazurowski
Automated segmentation is a fundamental medical image analysis task, which enjoys significant advances due to the advent of deep learning. While foundation models have been useful in natural language processing and some vision tasks for some time, the foundation model developed with image segmentation in mind - Segment Anything Model (SAM) - has been developed only recently and has shown similar promise. However, there are still no systematic analyses or best-practice guidelines for optimal fine-tuning of SAM for medical image segmentation. This work summarizes existing fine-tuning strategies with various backbone architectures, model components, and fine-tuning algorithms across 18 combinations, and evaluates them on 17 datasets covering all common radiology modalities. Our study reveals that (1) fine-tuning SAM leads to slightly better performance than previous segmentation methods, (2) fine-tuning strategies that use parameter-efficient learning in both the encoder and decoder are superior to other strategies, (3) network architecture has a small impact on final performance, (4) further training SAM with self-supervised learning can improve final model performance. We also demonstrate the ineffectiveness of some methods popular in the literature and further expand our experiments into few-shot and prompt-based settings. Lastly, we released our code and MRI-specific fine-tuned weights, which consistently obtained superior performance over the original SAM, at https://github.com/mazurowski-lab/finetune-SAM.
Read more5/14/2024