Enabling High-Throughput Parallel I/O in Particle-in-Cell Monte Carlo Simulations with openPMD and Darshan I/O Monitoring

0
Sign in to get full access
Overview
- The paper discusses enabling high-throughput parallel I/O in particle-in-cell (PIC) Monte Carlo simulations using openPMD and Darshan I/O monitoring.
- PIC simulations are computationally intensive and generate massive amounts of data, requiring efficient I/O solutions to handle the data processing and storage.
- The researchers explore the use of openPMD, a unified data format, and Darshan, an I/O monitoring tool, to improve the performance and scalability of PIC simulations.
Plain English Explanation
Particle-in-cell (PIC) simulations are a type of computer simulation used to study the behavior of particles, such as electrons or ions, in a variety of scientific and engineering applications. These simulations generate vast amounts of data that need to be processed and stored efficiently.
The researchers in this paper have explored using two tools, openPMD and Darshan, to improve the performance and scalability of PIC simulations.
openPMD is a standardized data format that allows for the storage and exchange of simulation data in a unified way. This helps to simplify the data processing and makes it easier to work with the large datasets generated by PIC simulations.
Darshan is an I/O monitoring tool that provides detailed information about the I/O patterns and performance of applications running on high-performance computing systems. This information can be used to identify and address bottlenecks in the I/O process, improving the overall efficiency of the simulations.
By combining these two tools, the researchers were able to achieve significant performance improvements in their PIC simulations, allowing them to process and store large amounts of data more efficiently.
Technical Explanation
The paper describes the researchers' efforts to enable high-throughput parallel I/O in particle-in-cell (PIC) Monte Carlo simulations using openPMD and Darshan.
PIC simulations are computationally intensive and generate massive amounts of data, which can be challenging to process and store efficiently. The researchers chose to use openPMD, a standardized data format for particle-based simulations, to simplify the data management and enable efficient I/O operations.
To monitor and analyze the I/O performance of their PIC simulations, the researchers employed Darshan, a lightweight I/O monitoring tool that provides detailed information about the I/O patterns and performance of applications running on high-performance computing systems.
The researchers conducted experiments to evaluate the performance of their PIC simulations using openPMD and Darshan. They compared the I/O performance and scalability of their approach with traditional file-based I/O methods, demonstrating significant improvements in data throughput and reduced I/O bottlenecks.
Critical Analysis
The paper presents a promising approach to addressing the I/O challenges in large-scale PIC simulations, but it is important to consider some potential limitations and areas for further research:
- The study was conducted on a specific PIC simulation code and hardware configuration, so the generalizability of the findings to other PIC simulation codes or different computing environments may be limited.
- The paper does not provide a comprehensive comparison of openPMD and Darshan with other data formats and I/O monitoring tools, which could help to better understand the relative strengths and weaknesses of the approaches.
- The paper does not discuss the potential overhead or performance impact of using openPMD and Darshan, which could be an important consideration for some applications.
- The researchers could have explored the integration of openPMD and Darshan with other data processing and storage technologies, such as ADIOS2 or distributed storage systems, to further enhance the overall performance and scalability of the PIC simulations.
Conclusion
The paper demonstrates the potential of using openPMD and Darshan to enable high-throughput parallel I/O in particle-in-cell (PIC) Monte Carlo simulations. By standardizing the data format and providing detailed I/O monitoring, the researchers were able to achieve significant performance improvements and overcome the challenges of processing and storing the massive amounts of data generated by these simulations.
The findings of this study could have broader implications for other computationally intensive simulations and applications that require efficient data processing and storage solutions. Further research and development in this area could lead to even more advanced tools and techniques for addressing the I/O challenges in large-scale scientific computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enabling High-Throughput Parallel I/O in Particle-in-Cell Monte Carlo Simulations with openPMD and Darshan I/O Monitoring
Jeremy J. Williams, Daniel Medeiros, Stefan Costea, David Tskhakaya, Franz Poeschel, Ren'e Widera, Axel Huebl, Scott Klasky, Norbert Podhorszki, Leon Kos, Ales Podolnik, Jakub Hromadka, Tapish Narwal, Klaus Steiniger, Michael Bussmann, Erwin Laure, Stefano Markidis
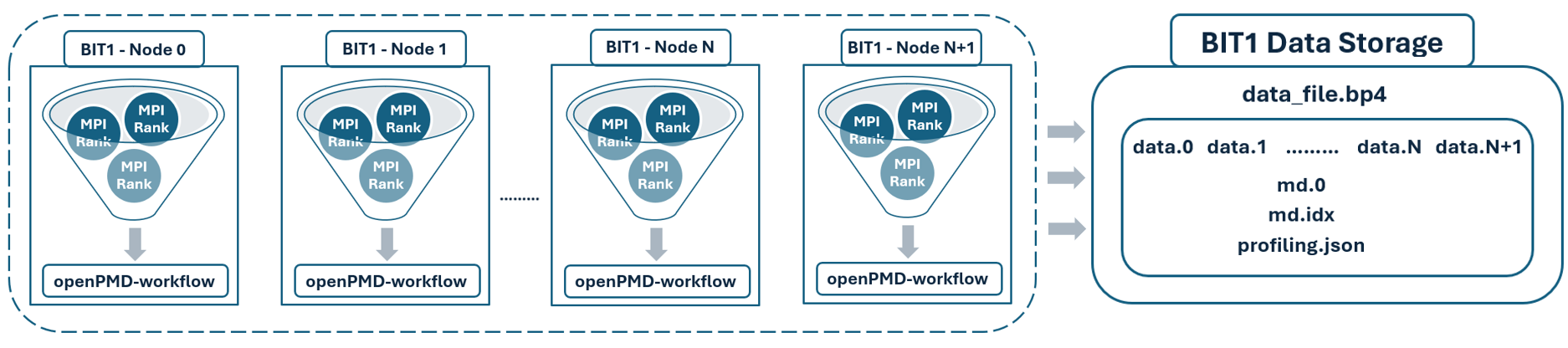
Large-scale HPC simulations of plasma dynamics in fusion devices require efficient parallel I/O to avoid slowing down the simulation and to enable the post-processing of critical information. Such complex simulations lacking parallel I/O capabilities may encounter performance bottlenecks, hindering their effectiveness in data-intensive computing tasks. In this work, we focus on introducing and enhancing the efficiency of parallel I/O operations in Particle-in-Cell Monte Carlo simulations. We first evaluate the scalability of BIT1, a massively-parallel electrostatic PIC MC code, determining its initial write throughput capabilities and performance bottlenecks using an HPC I/O performance monitoring tool, Darshan. We design and develop an adaptor to the openPMD I/O interface that allows us to stream PIC particle and field information to I/O using the BP4 backend, aggressively optimized for I/O efficiency, including the highly efficient ADIOS2 interface. Next, we explore advanced optimization techniques such as data compression, aggregation, and Lustre file striping, achieving write throughput improvements while enhancing data storage efficiency. Finally, we analyze the enhanced high-throughput parallel I/O and storage capabilities achieved through the integration of openPMD with rapid metadata extraction in BP4 format. Our study demonstrates that the integration of openPMD and advanced I/O optimizations significantly enhances BIT1's I/O performance and storage capabilities, successfully introducing high throughput parallel I/O and surpassing the capabilities of traditional file I/O.
Read more8/7/2024

0
Understanding the Impact of openPMD on BIT1, a Particle-in-Cell Monte Carlo Code, through Instrumentation, Monitoring, and In-Situ Analysis
Jeremy J. Williams, Stefan Costea, Allen D. Malony, David Tskhakaya, Leon Kos, Ales Podolnik, Jakub Hromadka, Kevin Huck, Erwin Laure, Stefano Markidis
Particle-in-Cell Monte Carlo simulations on large-scale systems play a fundamental role in understanding the complexities of plasma dynamics in fusion devices. Efficient handling and analysis of vast datasets are essential for advancing these simulations. Previously, we addressed this challenge by integrating openPMD with BIT1, a Particle-in-Cell Monte Carlo code, streamlining data streaming and storage. This integration not only enhanced data management but also improved write throughput and storage efficiency. In this work, we delve deeper into the impact of BIT1 openPMD BP4 instrumentation, monitoring, and in-situ analysis. Utilizing cutting-edge profiling and monitoring tools such as gprof, CrayPat, Cray Apprentice2, IPM, and Darshan, we dissect BIT1's performance post-integration, shedding light on computation, communication, and I/O operations. Fine-grained instrumentation offers insights into BIT1's runtime behavior, while immediate monitoring aids in understanding system dynamics and resource utilization patterns, facilitating proactive performance optimization. Advanced visualization techniques further enrich our understanding, enabling the optimization of BIT1 simulation workflows aimed at controlling plasma-material interfaces with improved data analysis and visualization at every checkpoint without causing any interruption to the simulation.
Read more9/6/2024

0
Optimizing BIT1, a Particle-in-Cell Monte Carlo Code, with OpenMP/OpenACC and GPU Acceleration
Jeremy J. Williams, Felix Liu, David Tskhakaya, Stefan Costea, Ales Podolnik, Stefano Markidis
On the path toward developing the first fusion energy devices, plasma simulations have become indispensable tools for supporting the design and development of fusion machines. Among these critical simulation tools, BIT1 is an advanced Particle-in-Cell code with Monte Carlo collisions, specifically designed for modeling plasma-material interaction and, in particular, analyzing the power load distribution on tokamak divertors. The current implementation of BIT1 relies exclusively on MPI for parallel communication and lacks support for GPUs. In this work, we address these limitations by designing and implementing a hybrid, shared-memory version of BIT1 capable of utilizing GPUs. For shared-memory parallelization, we rely on OpenMP and OpenACC, using a task-based approach to mitigate load-imbalance issues in the particle mover. On an HPE Cray EX computing node, we observe an initial performance improvement of approximately 42%, with scalable performance showing an enhancement of about 38% when using 8 MPI ranks. Still relying on OpenMP and OpenACC, we introduce the first version of BIT1 capable of using GPUs. We investigate two different data movement strategies: unified memory and explicit data movement. Overall, we report BIT1 data transfer findings during each PIC cycle. Among BIT1 GPU implementations, we demonstrate performance improvement through concurrent GPU utilization, especially when MPI ranks are assigned to dedicated GPUs. Finally, we analyze the performance of the first BIT1 GPU porting with the NVIDIA Nsight tools to further our understanding of BIT1 computational efficiency for large-scale plasma simulations, capable of exploiting current supercomputer infrastructures.
Read more9/9/2024

0
Towards a Scalable and Efficient PGAS-based Distributed OpenMP
Baodi Shan, Mauricio Araya-Polo, Barbara Chapman
MPI+X has been the de facto standard for distributed memory parallel programming. It is widely used primarily as an explicit two-sided communication model, which often leads to complex and error-prone code. Alternatively, PGAS model utilizes efficient one-sided communication and more intuitive communication primitives. In this paper, we present a novel approach that integrates PGAS concepts into the OpenMP programming model, leveraging the LLVM compiler infrastructure and the GASNet-EX communication library. Our model addresses the complexity associated with traditional MPI+OpenMP programming models while ensuring excellent performance and scalability. We evaluate our approach using a set of micro-benchmarks and application kernels on two distinct platforms: Ookami from Stony Brook University and NERSC Perlmutter. The results demonstrate that DiOMP achieves superior bandwidth and lower latency compared to MPI+OpenMP, up to 25% higher bandwidth and down to 45% on latency. DiOMP offers a promising alternative to the traditional MPI+OpenMP hybrid programming model, towards providing a more productive and efficient way to develop high-performance parallel applications for distributed memory systems.
Read more9/5/2024