Enhanced Creativity and Ideation through Stable Video Synthesis
2405.13357
0
0
🤔
Abstract
This paper explores the innovative application of Stable Video Diffusion (SVD), a diffusion model that revolutionizes the creation of dynamic video content from static images. As digital media and design industries accelerate, SVD emerges as a powerful generative tool that enhances productivity and introduces novel creative possibilities. The paper examines the technical underpinnings of diffusion models, their practical effectiveness, and potential future developments, particularly in the context of video generation. SVD operates on a probabilistic framework, employing a gradual denoising process to transform random noise into coherent video frames. It addresses the challenges of visual consistency, natural movement, and stylistic reflection in generated videos, showcasing high generalization capabilities. The integration of SVD in design tasks promises enhanced creativity, rapid prototyping, and significant time and cost efficiencies. It is particularly impactful in areas requiring frame-to-frame consistency, natural motion capture, and creative diversity, such as animation, visual effects, advertising, and educational content creation. The paper concludes that SVD is a catalyst for design innovation, offering a wide array of applications and a promising avenue for future research and development in the field of digital media and design.
Create account to get full access
Overview
- This paper explores a new diffusion model called Stable Video Diffusion (SVD) that can generate dynamic video content from static images.
- SVD is presented as a powerful generative tool that enhances productivity and introduces new creative possibilities in digital media and design industries.
- The paper examines the technical foundations of diffusion models, their practical effectiveness, and potential future developments, particularly in the context of video generation.
Plain English Explanation
Stable Video Diffusion (SVD) is an innovative technology that can turn regular images into moving videos. As the world of digital media and design continues to evolve rapidly, SVD emerges as a valuable tool that can boost productivity and unlock new creative avenues.
The underlying concept of SVD is based on "diffusion models," which are a type of machine learning approach. These models start with random noise and gradually transform it into coherent visual content through a probabilistic denoising process. SVD specifically tackles the challenges of ensuring visual consistency, natural movement, and stylistic reflection in the generated videos, showcasing its versatility and generalization capabilities.
By integrating SVD into various design workflows, professionals can experience enhanced creativity, faster prototyping, and significant time and cost savings. This technology is particularly impactful in areas that require consistent frames, realistic motion capture, and diverse creative outputs, such as animation, visual effects, advertising, and educational content creation.
Overall, the paper suggests that SVD is a catalyst for innovation in the digital media and design industries, offering a wide range of applications and a promising path for future research and development in this field.
Technical Explanation
The core of SVD is built upon diffusion models, a type of probabilistic machine learning approach that starts with random noise and gradually transforms it into coherent visual content. This process involves a series of denoising steps, where the model learns to progressively remove noise and generate more visually coherent frames.
Compared to traditional video generation techniques, SVD introduces several key advancements. It addresses the challenges of maintaining visual consistency, natural movement, and stylistic reflection in the generated videos. By leveraging a score-based approach, SVD demonstrates high generalization capabilities, enabling it to produce a diverse range of video content from static image inputs.
The integration of SVD into design workflows promises to enhance creativity, accelerate prototyping, and significantly improve time and cost efficiencies. This technology is particularly impactful in areas that require frame-to-frame consistency, natural motion capture, and creative diversity, such as animation, visual effects, advertising, and educational content creation.
Critical Analysis
While the paper presents SVD as a promising technology, it acknowledges some potential limitations and areas for further research. For example, the paper suggests that maintaining temporal coherence and ensuring long-range dependencies in generated videos remain ongoing challenges that require further exploration.
Additionally, the paper does not delve into the potential biases or ethical considerations that may arise from the widespread use of generative models like SVD. As these technologies become more prevalent, it will be crucial to address concerns about the responsible and transparent development and deployment of such systems.
Further research could also explore ways to enhance the interpretability and controllability of SVD, allowing designers and creators to have more fine-grained control over the generated video content. Integrating self-attention mechanisms could be a promising direction to address long-range dependencies and improve the overall coherence of the generated videos.
Conclusion
The paper presents Stable Video Diffusion (SVD) as a groundbreaking technology that has the potential to revolutionize the digital media and design industries. By leveraging the power of diffusion models, SVD can transform static images into dynamic video content, enhancing creativity, productivity, and cost-effectiveness across a wide range of applications.
The technical insights and practical implications discussed in the paper suggest that SVD is a catalyst for innovation, opening up new creative possibilities and serving as a promising avenue for future research and development in the field of digital media and design.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SF-V: Single Forward Video Generation Model
Zhixing Zhang, Yanyu Li, Yushu Wu, Yanwu Xu, Anil Kag, Ivan Skorokhodov, Willi Menapace, Aliaksandr Siarohin, Junli Cao, Dimitris Metaxas, Sergey Tulyakov, Jian Ren
0
0
Diffusion-based video generation models have demonstrated remarkable success in obtaining high-fidelity videos through the iterative denoising process. However, these models require multiple denoising steps during sampling, resulting in high computational costs. In this work, we propose a novel approach to obtain single-step video generation models by leveraging adversarial training to fine-tune pre-trained video diffusion models. We show that, through the adversarial training, the multi-steps video diffusion model, i.e., Stable Video Diffusion (SVD), can be trained to perform single forward pass to synthesize high-quality videos, capturing both temporal and spatial dependencies in the video data. Extensive experiments demonstrate that our method achieves competitive generation quality of synthesized videos with significantly reduced computational overhead for the denoising process (i.e., around $23times$ speedup compared with SVD and $6times$ speedup compared with existing works, with even better generation quality), paving the way for real-time video synthesis and editing. More visualization results are made publicly available at https://snap-research.github.io/SF-V.
6/7/2024

Streaming Video Diffusion: Online Video Editing with Diffusion Models
Feng Chen, Zhen Yang, Bohan Zhuang, Qi Wu
0
0
We present a novel task called online video editing, which is designed to edit textbf{streaming} frames while maintaining temporal consistency. Unlike existing offline video editing assuming all frames are pre-established and accessible, online video editing is tailored to real-life applications such as live streaming and online chat, requiring (1) fast continual step inference, (2) long-term temporal modeling, and (3) zero-shot video editing capability. To solve these issues, we propose Streaming Video Diffusion (SVDiff), which incorporates the compact spatial-aware temporal recurrence into off-the-shelf Stable Diffusion and is trained with the segment-level scheme on large-scale long videos. This simple yet effective setup allows us to obtain a single model that is capable of executing a broad range of videos and editing each streaming frame with temporal coherence. Our experiments indicate that our model can edit long, high-quality videos with remarkable results, achieving a real-time inference speed of 15.2 FPS at a resolution of 512x512.
5/31/2024
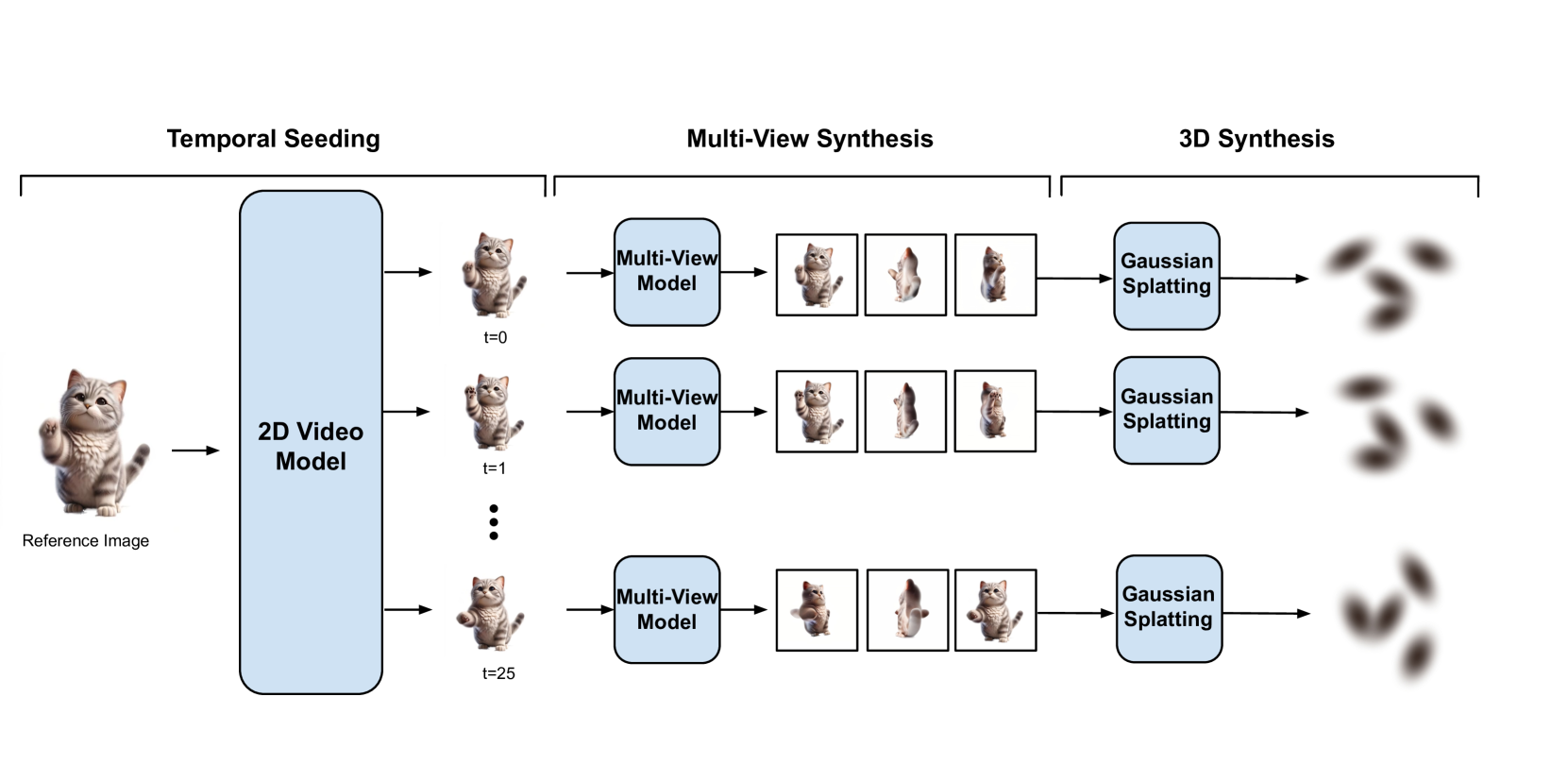
Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
Rishab Parthasarathy, Zack Ankner, Aaron Gokaslan
0
0
A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D seed of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.
6/18/2024

VividPose: Advancing Stable Video Diffusion for Realistic Human Image Animation
Qilin Wang, Zhengkai Jiang, Chengming Xu, Jiangning Zhang, Yabiao Wang, Xinyi Zhang, Yun Cao, Weijian Cao, Chengjie Wang, Yanwei Fu
0
0
Human image animation involves generating a video from a static image by following a specified pose sequence. Current approaches typically adopt a multi-stage pipeline that separately learns appearance and motion, which often leads to appearance degradation and temporal inconsistencies. To address these issues, we propose VividPose, an innovative end-to-end pipeline based on Stable Video Diffusion (SVD) that ensures superior temporal stability. To enhance the retention of human identity, we propose an identity-aware appearance controller that integrates additional facial information without compromising other appearance details such as clothing texture and background. This approach ensures that the generated videos maintain high fidelity to the identity of human subject, preserving key facial features across various poses. To accommodate diverse human body shapes and hand movements, we introduce a geometry-aware pose controller that utilizes both dense rendering maps from SMPL-X and sparse skeleton maps. This enables accurate alignment of pose and shape in the generated videos, providing a robust framework capable of handling a wide range of body shapes and dynamic hand movements. Extensive qualitative and quantitative experiments on the UBCFashion and TikTok benchmarks demonstrate that our method achieves state-of-the-art performance. Furthermore, VividPose exhibits superior generalization capabilities on our proposed in-the-wild dataset. Codes and models will be available.
5/29/2024