Enhanced document retrieval with topic embeddings

0

Sign in to get full access
Overview
- The research paper proposes a method called "Enhanced Document Retrieval with Topic Embeddings" to improve the performance of document retrieval systems.
- The key idea is to leverage topic embeddings, which capture the semantic relationships between topics, to enhance the retrieval process.
- The authors conduct experiments on various datasets to demonstrate the effectiveness of their approach compared to traditional retrieval methods.
Plain English Explanation
When searching for information online, we often rely on document retrieval systems to find the most relevant documents. However, these systems can sometimes struggle to understand the nuanced relationships between different topics and concepts.
The researchers behind this paper recognized this challenge and developed a novel approach to address it. They created topic embeddings, which are mathematical representations of the semantic connections between different topics. By incorporating these topic embeddings into the document retrieval process, the system can better understand the context and meaning of the search query, leading to more accurate and relevant results.
Imagine you're searching for information on "climate change." A traditional retrieval system might simply look for documents that contain those exact words. But with topic embeddings, the system can also recognize that "global warming" and "greenhouse gas emissions" are closely related to the topic of climate change, and include those relevant documents in the search results as well.
The researchers tested their approach on several different datasets and found that it outperformed traditional retrieval methods. This suggests that incorporating topic knowledge into document retrieval can be a valuable way to enhance the accuracy and usefulness of search results.
Technical Explanation
The paper describes a document retrieval system that leverages topic embeddings to improve its performance. The key components of the system are:
-
Topic Embedding Model: The authors trained a topic embedding model using a large corpus of text data. This model learns to represent the semantic relationships between different topics as vectors in a high-dimensional space.
-
Retrieval Module: The retrieval module takes a user query as input and uses the topic embeddings to identify the most relevant documents from a database. This is done by first mapping the query to the topic embedding space, and then finding documents that have a high similarity to the query's topic representation.
-
Ranking and Scoring: The retrieved documents are then ranked and scored based on a combination of their topic similarity and other relevance factors, such as term frequency and inverse document frequency (TF-IDF).
The authors conducted experiments on several datasets, including newswire articles and scientific papers, and compared their approach to traditional retrieval methods. The results showed that the topic embedding-based system consistently outperformed the baselines, demonstrating the value of incorporating topic-level knowledge into the retrieval process.
Critical Analysis
The paper presents a compelling approach to enhancing document retrieval, but there are a few potential limitations and areas for further research:
-
Generalizability: The experiments were conducted on specific datasets, and it's unclear how well the topic embedding-based approach would generalize to other types of text data or retrieval tasks.
-
Computational Complexity: Training the topic embedding model and integrating it into the retrieval system may introduce additional computational overhead, which could impact the system's scalability and real-time performance.
-
Interpretability: While the topic embeddings can improve retrieval accuracy, they may also introduce some opacity in terms of understanding the reasoning behind the system's decisions. Providing more transparency and explainability could be beneficial.
-
User Evaluation: The paper focuses on automated metrics, but it would be valuable to also evaluate the system's performance from the perspective of human users, to ensure that the enhanced retrieval results are truly useful and relevant to their information needs.
Overall, the research represents an interesting and promising approach to improving document retrieval, with the potential to significantly impact the way people search for and access information online.
Conclusion
The paper presents a novel method for enhancing document retrieval by leveraging topic embeddings to better understand the semantic relationships between different concepts and topics. The experiments demonstrate the effectiveness of this approach, suggesting that it could lead to more accurate and relevant search results.
While there are some potential limitations and areas for further research, the overall significance of this work lies in its ability to improve the efficiency and accuracy of information retrieval, which is a fundamental aspect of how people access and consume information in the digital age. As the volume of available information continues to grow, tools like this that can help people find what they're looking for more effectively will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhanced document retrieval with topic embeddings
Kavsar Huseynova, Jafar Isbarov
Document retrieval systems have experienced a revitalized interest with the advent of retrieval-augmented generation (RAG). RAG architecture offers a lower hallucination rate than LLM-only applications. However, the accuracy of the retrieval mechanism is known to be a bottleneck in the efficiency of these applications. A particular case of subpar retrieval performance is observed in situations where multiple documents from several different but related topics are in the corpus. We have devised a new vectorization method that takes into account the topic information of the document. The paper introduces this new method for text vectorization and evaluates it in the context of RAG. Furthermore, we discuss the challenge of evaluating RAG systems, which pertains to the case at hand.
Read more8/21/2024
0
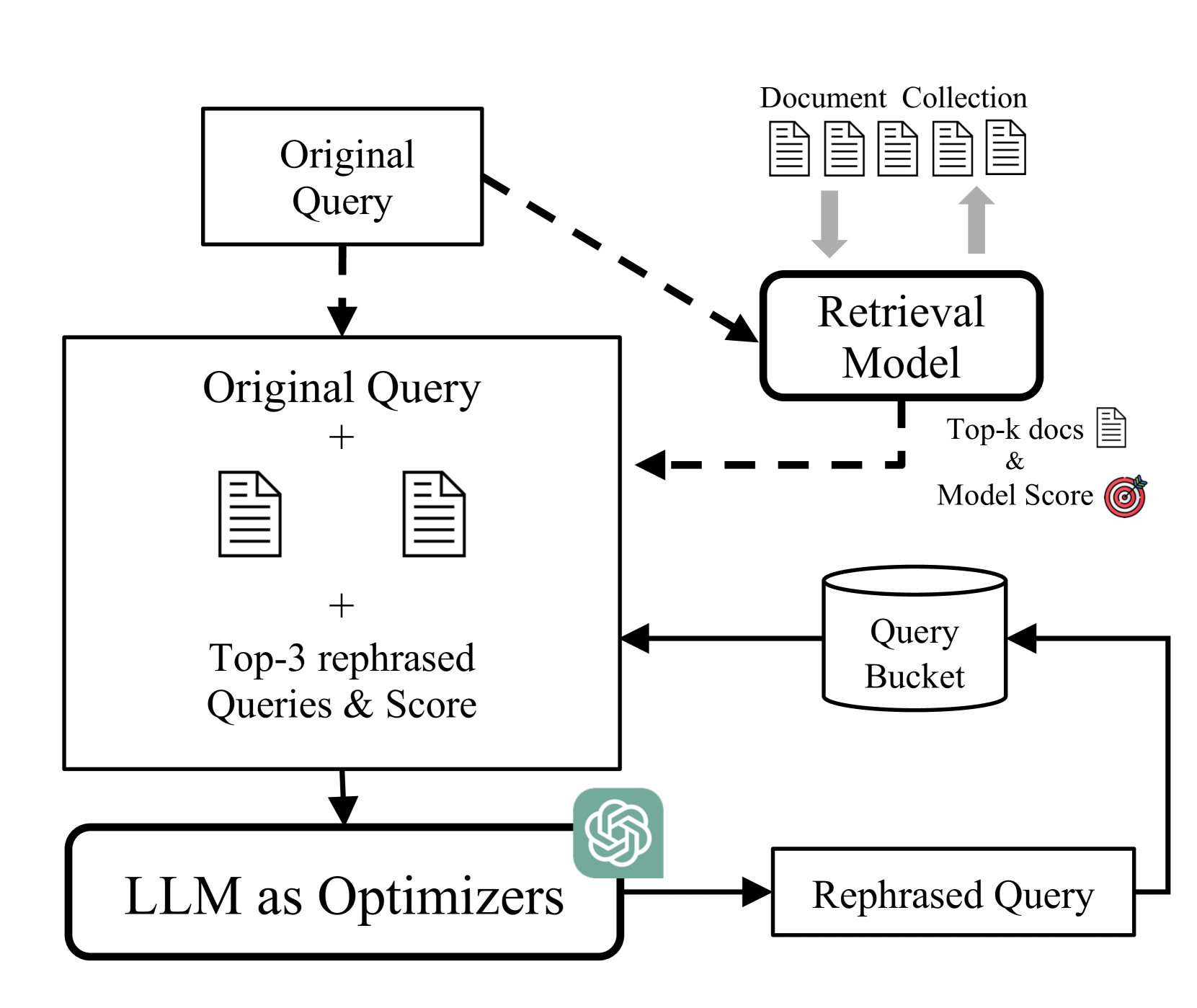
Optimizing Query Generation for Enhanced Document Retrieval in RAG
Hamin Koo, Minseon Kim, Sung Ju Hwang
Large Language Models (LLMs) excel in various language tasks but they often generate incorrect information, a phenomenon known as hallucinations. Retrieval-Augmented Generation (RAG) aims to mitigate this by using document retrieval for accurate responses. However, RAG still faces hallucinations due to vague queries. This study aims to improve RAG by optimizing query generation with a query-document alignment score, refining queries using LLMs for better precision and efficiency of document retrieval. Experiments have shown that our approach improves document retrieval, resulting in an average accuracy gain of 1.6%.
Read more7/18/2024
0
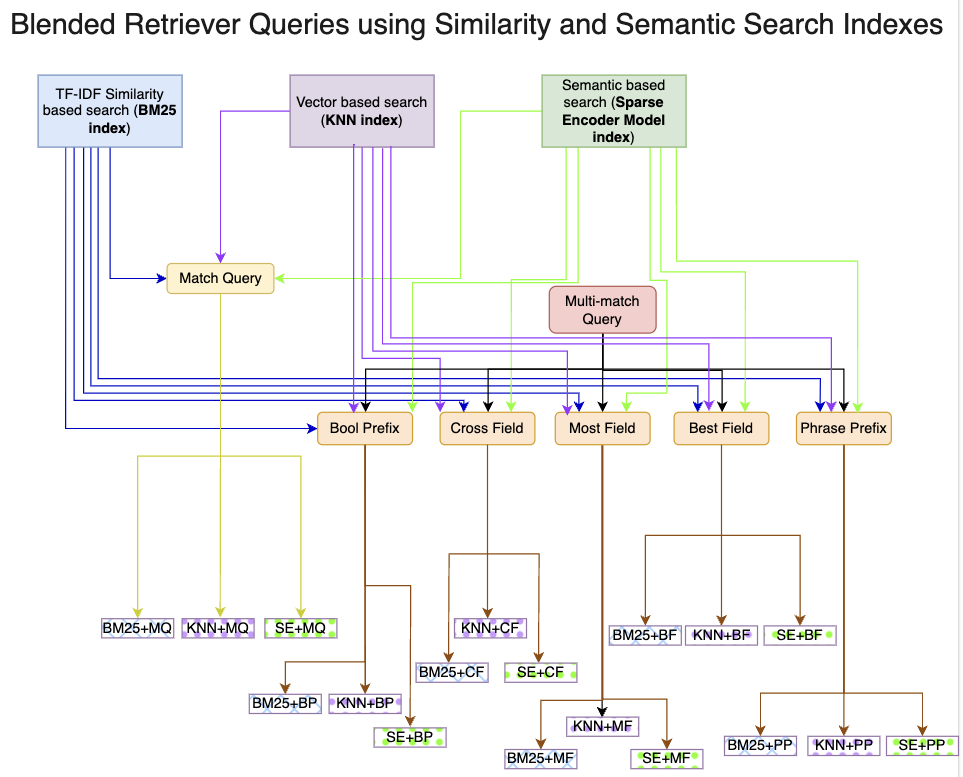
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
Read more4/12/2024
0
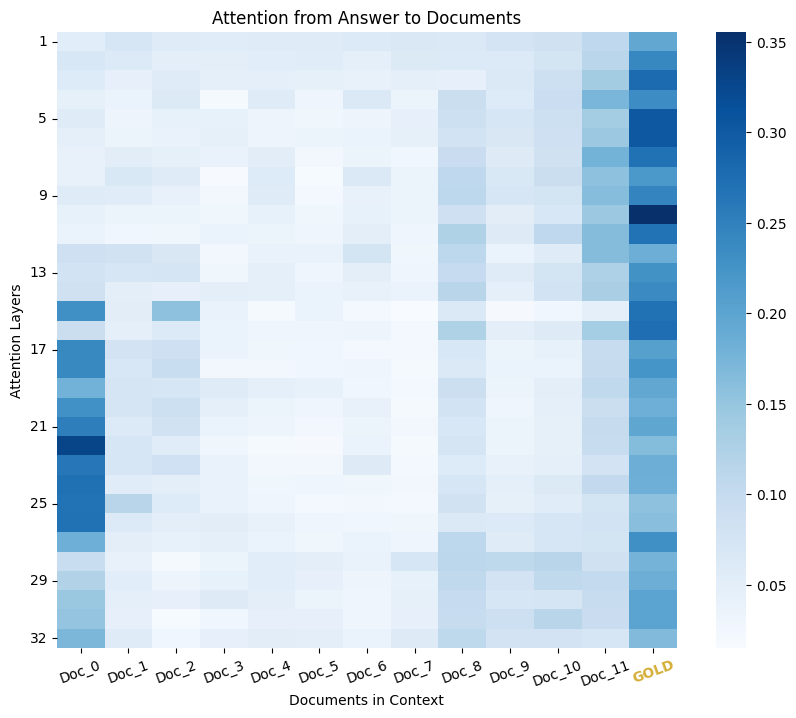
The Power of Noise: Redefining Retrieval for RAG Systems
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, Fabrizio Silvestri
Retrieval-Augmented Generation (RAG) has recently emerged as a method to extend beyond the pre-trained knowledge of Large Language Models by augmenting the original prompt with relevant passages or documents retrieved by an Information Retrieval (IR) system. RAG has become increasingly important for Generative AI solutions, especially in enterprise settings or in any domain in which knowledge is constantly refreshed and cannot be memorized in the LLM. We argue here that the retrieval component of RAG systems, be it dense or sparse, deserves increased attention from the research community, and accordingly, we conduct the first comprehensive and systematic examination of the retrieval strategy of RAG systems. We focus, in particular, on the type of passages IR systems within a RAG solution should retrieve. Our analysis considers multiple factors, such as the relevance of the passages included in the prompt context, their position, and their number. One counter-intuitive finding of this work is that the retriever's highest-scoring documents that are not directly relevant to the query (e.g., do not contain the answer) negatively impact the effectiveness of the LLM. Even more surprising, we discovered that adding random documents in the prompt improves the LLM accuracy by up to 35%. These results highlight the need to investigate the appropriate strategies when integrating retrieval with LLMs, thereby laying the groundwork for future research in this area.
Read more5/2/2024