Enhanced Expressivity in Graph Neural Networks with Lanczos-Based Linear Constraints

0
🧠
Sign in to get full access
Overview
- This paper proposes a new approach to enhance the expressivity of graph neural networks (GNNs) using Lanczos-based linear constraints.
- The key idea is to incorporate additional linear constraints into the GNN architecture, which can capture more complex structural information in graph data.
- The authors demonstrate the effectiveness of their approach through experiments on node classification tasks.
Plain English Explanation
The paper focuses on improving the [object Object] of [object Object]. GNNs are a type of machine learning model used to analyze data that can be represented as a [object Object], where entities are nodes, and the relationships between them are edges.
The authors propose a new approach that adds [object Object] to the GNN architecture. These constraints are derived using a mathematical technique called the [object Object], which can capture more nuanced structural information in the graph data.
By incorporating these linear constraints, the GNN model can learn more complex patterns and relationships in the graph, potentially leading to better performance on tasks like [object Object], where the goal is to predict the class or category of each node in the graph.
Technical Explanation
The paper introduces a novel approach to enhance the expressivity of graph neural networks (GNNs) by incorporating Lanczos-based linear constraints into the GNN architecture.
The authors begin by providing a formal definition of GNNs and their limitations in capturing complex structural information. They then describe their proposed method, which involves:
- Deriving linear constraints using the Lanczos method, a numerical technique for approximating the eigenvectors and eigenvalues of a matrix.
- Integrating these linear constraints into the GNN model, such that the model learns to satisfy the constraints during training.
The key idea is that the Lanczos-based linear constraints can capture more nuanced structural properties of the graph, beyond what can be learned by standard GNN layers alone. The authors hypothesize that this enhanced expressivity will lead to improved performance on node classification tasks.
To validate their approach, the authors conduct experiments on several benchmark graph datasets, comparing their method to traditional GNN models as well as other state-of-the-art techniques. The results demonstrate the effectiveness of the proposed approach, with significant improvements in node classification accuracy.
Critical Analysis
The paper presents a novel and theoretically well-grounded approach to enhancing the expressivity of GNNs. The use of Lanczos-based linear constraints is a unique and potentially powerful idea, as it allows the model to learn more complex structural patterns in graph data.
However, the paper does not discuss the computational complexity and training overhead associated with the additional linear constraints. Incorporating these constraints may increase the model size and training time, which could be a limitation for real-world applications with large-scale graphs.
Additionally, the paper focuses solely on node classification tasks, and it would be interesting to see how the proposed method performs on other graph-related problems, such as link prediction or graph generation.
Furthermore, the generalization of the method to heterogeneous graphs or dynamic graphs is not addressed, and these would be valuable extensions to explore in future research.
Conclusion
This paper presents a novel approach to enhancing the expressivity of graph neural networks by incorporating Lanczos-based linear constraints into the model architecture. The authors demonstrate the effectiveness of their method on node classification tasks, suggesting that the additional structural information captured by the constraints can lead to improved performance.
While the paper makes a valuable contribution to the field of graph machine learning, there are some potential limitations and areas for further research, such as the computational complexity, the applicability to other graph problems, and the generalization to more complex graph scenarios. Overall, the work represents an interesting step forward in improving the representational power of GNNs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Enhanced Expressivity in Graph Neural Networks with Lanczos-Based Linear Constraints
Niloofar Azizi, Nils Kriege, Horst Bischof
Graph Neural Networks (GNNs) excel in handling graph-structured data but often underperform in link prediction tasks compared to classical methods, mainly due to the limitations of the commonly used Message Passing GNNs (MPNNs). Notably, their ability to distinguish non-isomorphic graphs is limited by the 1-dimensional Weisfeiler-Lehman test. Our study presents a novel method to enhance the expressivity of GNNs by embedding induced subgraphs into the graph Laplacian matrix's eigenbasis. We introduce a Learnable Lanczos algorithm with Linear Constraints (LLwLC), proposing two novel subgraph extraction strategies: encoding vertex-deleted subgraphs and applying Neumann eigenvalue constraints. For the former, we conjecture that LLwLC establishes a universal approximator, offering efficient time complexity. The latter focuses on link representations enabling differentiation between $k$-regular graphs and node automorphism, a vital aspect for link prediction tasks. Our approach results in an extremely lightweight architecture, reducing the need for extensive training datasets. Empirically, our method improves performance in challenging link prediction tasks across benchmark datasets, establishing its practical utility and supporting our theoretical findings. Notably, LLwLC achieves 20x and 10x speedup by only requiring 5% and 10% data from the PubMed and OGBL-Vessel datasets while comparing to the state-of-the-art.
Read more8/23/2024
0
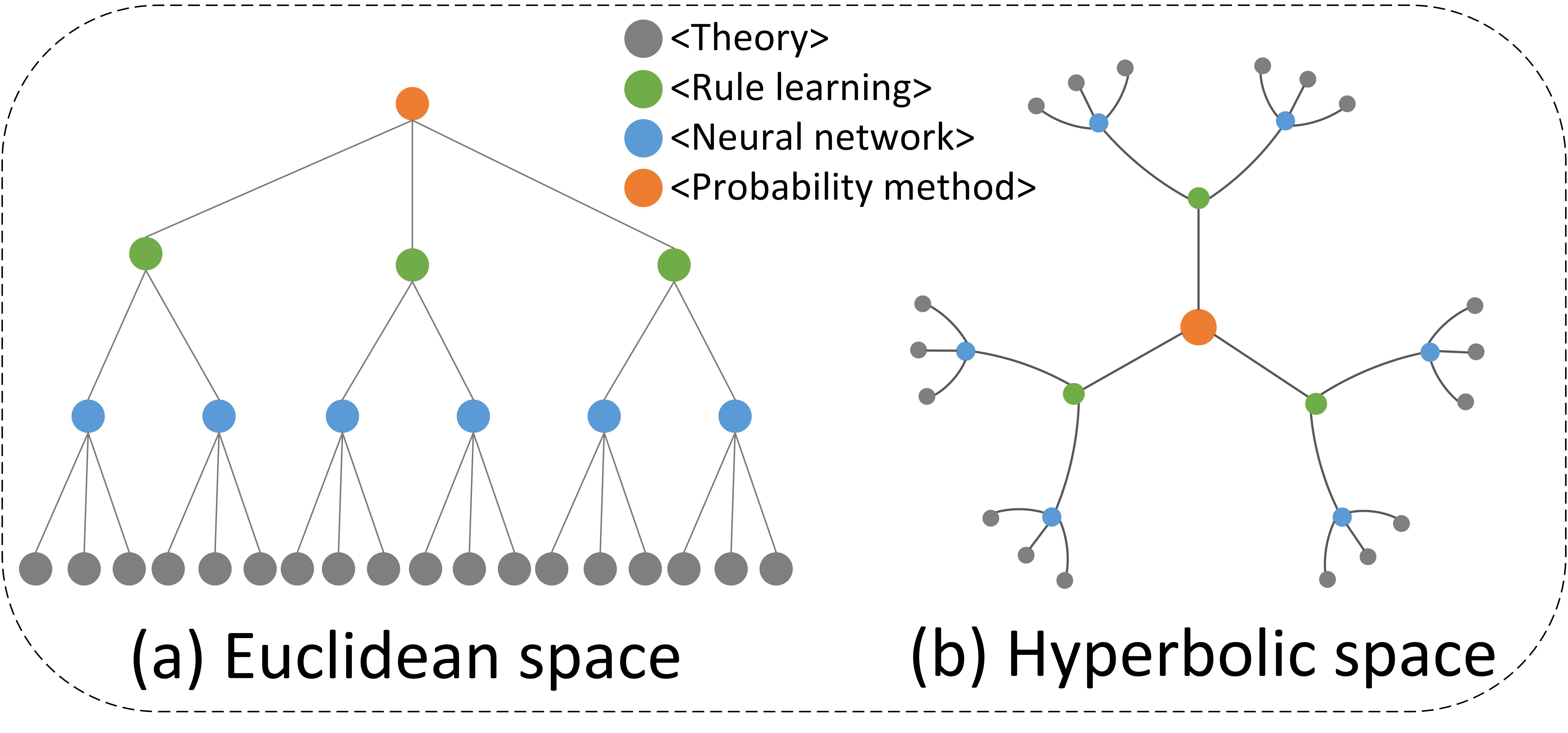
L$^2$GC: Lorentzian Linear Graph Convolutional Networks For Node Classification
Qiuyu Liang, Weihua Wang, Feilong Bao, Guanglai Gao
Linear Graph Convolutional Networks (GCNs) are used to classify the node in the graph data. However, we note that most existing linear GCN models perform neural network operations in Euclidean space, which do not explicitly capture the tree-like hierarchical structure exhibited in real-world datasets that modeled as graphs. In this paper, we attempt to introduce hyperbolic space into linear GCN and propose a novel framework for Lorentzian linear GCN. Specifically, we map the learned features of graph nodes into hyperbolic space, and then perform a Lorentzian linear feature transformation to capture the underlying tree-like structure of data. Experimental results on standard citation networks datasets with semi-supervised learning show that our approach yields new state-of-the-art results of accuracy 74.7$%$ on Citeseer and 81.3$%$ on PubMed datasets. Furthermore, we observe that our approach can be trained up to two orders of magnitude faster than other nonlinear GCN models on PubMed dataset. Our code is publicly available at https://github.com/llqy123/LLGC-master.
Read more6/17/2024

0
All Against Some: Efficient Integration of Large Language Models for Message Passing in Graph Neural Networks
Ajay Jaiswal, Nurendra Choudhary, Ravinarayana Adkathimar, Muthu P. Alagappan, Gaurush Hiranandani, Ying Ding, Zhangyang Wang, Edward W Huang, Karthik Subbian
Graph Neural Networks (GNNs) have attracted immense attention in the past decade due to their numerous real-world applications built around graph-structured data. On the other hand, Large Language Models (LLMs) with extensive pretrained knowledge and powerful semantic comprehension abilities have recently shown a remarkable ability to benefit applications using vision and text data. In this paper, we investigate how LLMs can be leveraged in a computationally efficient fashion to benefit rich graph-structured data, a modality relatively unexplored in LLM literature. Prior works in this area exploit LLMs to augment every node features in an ad-hoc fashion (not scalable for large graphs), use natural language to describe the complex structural information of graphs, or perform computationally expensive finetuning of LLMs in conjunction with GNNs. We propose E-LLaGNN (Efficient LLMs augmented GNNs), a framework with an on-demand LLM service that enriches message passing procedure of graph learning by enhancing a limited fraction of nodes from the graph. More specifically, E-LLaGNN relies on sampling high-quality neighborhoods using LLMs, followed by on-demand neighborhood feature enhancement using diverse prompts from our prompt catalog, and finally information aggregation using message passing from conventional GNN architectures. We explore several heuristics-based active node selection strategies to limit the computational and memory footprint of LLMs when handling millions of nodes. Through extensive experiments & ablation on popular graph benchmarks of varying scales (Cora, PubMed, ArXiv, & Products), we illustrate the effectiveness of our E-LLaGNN framework and reveal many interesting capabilities such as improved gradient flow in deep GNNs, LLM-free inference ability etc.
Read more7/23/2024
🔗
0
Dual-Channel Latent Factor Analysis Enhanced Graph Contrastive Learning for Recommendation
Junfeng Long, Hao Wu
Graph Neural Networks (GNNs) are powerful learning methods for recommender systems owing to their robustness in handling complicated user-item interactions. Recently, the integration of contrastive learning with GNNs has demonstrated remarkable performance in recommender systems to handle the issue of highly sparse user-item interaction data. Yet, some available graph contrastive learning (GCL) techniques employ stochastic augmentation, i.e., nodes or edges are randomly perturbed on the user-item bipartite graph to construct contrastive views. Such a stochastic augmentation strategy not only brings noise perturbation but also cannot utilize global collaborative signals effectively. To address it, this study proposes a latent factor analysis (LFA) enhanced GCL approach, named LFA-GCL. Our model exclusively incorporates LFA to implement the unconstrained structural refinement, thereby obtaining an augmented global collaborative graph accurately without introducing noise signals. Experiments on four public datasets show that the proposed LFA-GCL outperforms the state-of-the-art models.
Read more8/12/2024