Enhancing Content-based Recommendation via Large Language Model

0

Sign in to get full access
Overview
- Enhances content-based recommendation using large language models
- Leverages contrastive learning to better capture user interests and item features
- Validates the approach on several datasets, showing improvements over baseline methods
Plain English Explanation
The paper explores how to enhance content-based recommendation systems by incorporating large language models. Content-based recommendation systems aim to suggest items to users based on the features of the items, rather than just the users' past interactions.
The key insight is that large language models, which are trained on vast amounts of text data, can capture rich semantic information about the content of items. By integrating this information into the recommendation model, the system can better understand the relationships between items and user preferences.
The researchers use a technique called contrastive learning to train the model. This involves learning representations that maximize the similarity between an item and the user's previous preferences, while minimizing the similarity to other irrelevant items. This helps the model learn a more nuanced understanding of user interests.
The approach is validated on several real-world datasets, where it is shown to outperform traditional content-based recommendation methods. This suggests that leveraging large language models can be a powerful way to enhance the performance of content-based recommender systems.
Technical Explanation
The paper proposes a content-based recommendation model that integrates large language models to better capture item features and user preferences.
The key components are:
- Item Encoder: A pre-trained large language model is used to encode the textual content of each item, generating a rich semantic representation.
- User Encoder: User preferences are modeled by encoding their past interacted items using the same language model.
- Contrastive Learning: The model is trained using a contrastive loss function, which encourages the user and positive item representations to be similar, while pushing negative (uninteracted) items to be dissimilar.
This architecture allows the model to leverage the broad knowledge captured by the large language model, while also learning personalized user representations through contrastive training. The experiments demonstrate that this approach outperforms traditional content-based and hybrid recommendation methods on several datasets.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the proposed approach. However, a few potential limitations and areas for future work are worth considering:
-
Computational Overhead: Integrating large language models can increase the computational complexity of the recommendation system, which may be a concern for real-world deployment. The authors could explore ways to reduce the model size or optimize the inference process.
-
Cold-start Problem: The paper does not address the cold-start problem, where the system needs to make recommendations for new users or items with limited interaction data. Exploring how the language model-based approach could be extended to handle cold-start scenarios would be valuable.
-
Interpretability: As with many deep learning-based models, the internal workings of the proposed system may be difficult to interpret. Providing more insights into how the language model representations are used and how the contrastive learning process impacts the final recommendations could enhance the model's transparency.
-
Generalization to Other Domains: The experiments are conducted on textual datasets, such as books and movies. It would be interesting to see how the approach performs on recommendation tasks involving other modalities, such as images or audio, to assess its broader applicability.
Conclusion
This paper presents a novel approach to enhance content-based recommendation systems by integrating large language models. The key innovation is the use of contrastive learning to better capture the relationships between user preferences and item features. The experimental results demonstrate the effectiveness of this approach, suggesting that leveraging the rich semantic knowledge of language models can be a promising direction for improving recommendation accuracy.
The work highlights the potential of combining advanced machine learning techniques, such as contrastive learning, with the powerful capabilities of large language models. As these models continue to evolve and become more accessible, we can expect to see further advancements in personalized recommendation systems that better understand user interests and deliver more relevant and engaging content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Content-based Recommendation via Large Language Model
Wentao Xu, Qianqian Xie, Shuo Yang, Jiangxia Cao, Shuchao Pang
In real-world applications, users express different behaviors when they interact with different items, including implicit click/like interactions, and explicit comments/reviews interactions. Nevertheless, almost all recommender works are focused on how to describe user preferences by the implicit click/like interactions, to find the synergy of people. For the content-based explicit comments/reviews interactions, some works attempt to utilize them to mine the semantic knowledge to enhance recommender models. However, they still neglect the following two points: (1) The content semantic is a universal world knowledge; how do we extract the multi-aspect semantic information to empower different domains? (2) The user/item ID feature is a fundamental element for recommender models; how do we align the ID and content semantic feature space? In this paper, we propose a `plugin' semantic knowledge transferring method textbf{LoID}, which includes two major components: (1) LoRA-based large language model pretraining to extract multi-aspect semantic information; (2) ID-based contrastive objective to align their feature spaces. We conduct extensive experiments with SOTA baselines on real-world datasets, the detailed results demonstrating significant improvements of our method LoID.
Read more7/30/2024
💬
0
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
Jian Jia, Yipei Wang, Yan Li, Honggang Chen, Xuehan Bai, Zhaocheng Liu, Jian Liang, Quan Chen, Han Li, Peng Jiang, Kun Gai
Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
Read more5/8/2024
💬
0
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
Read more4/22/2024
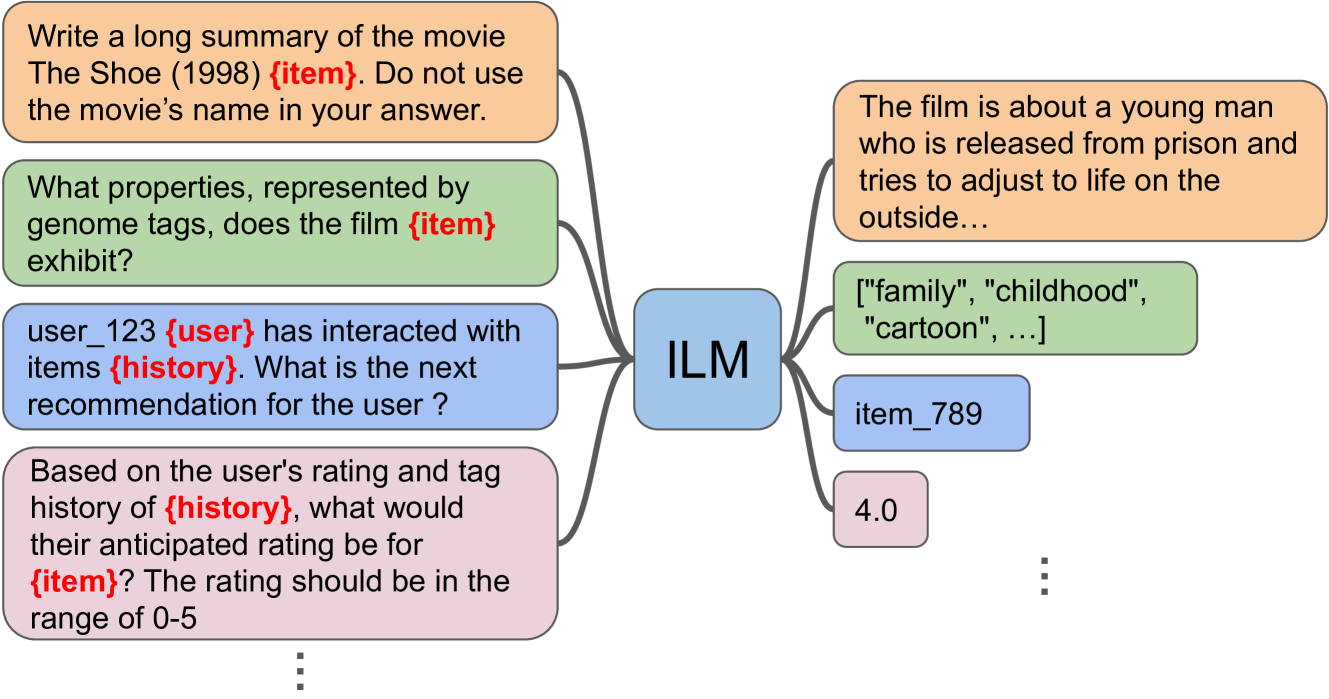
0
Item-Language Model for Conversational Recommendation
Li Yang, Anushya Subbiah, Hardik Patel, Judith Yue Li, Yanwei Song, Reza Mirghaderi, Vikram Aggarwal
Large-language Models (LLMs) have been extremely successful at tasks like complex dialogue understanding, reasoning and coding due to their emergent abilities. These emergent abilities have been extended with multi-modality to include image, audio, and video capabilities. Recommender systems, on the other hand, have been critical for information seeking and item discovery needs. Recently, there have been attempts to apply LLMs for recommendations. One difficulty of current attempts is that the underlying LLM is usually not trained on the recommender system data, which largely contains user interaction signals and is often not publicly available. Another difficulty is user interaction signals often have a different pattern from natural language text, and it is currently unclear if the LLM training setup can learn more non-trivial knowledge from interaction signals compared with traditional recommender system methods. Finally, it is difficult to train multiple LLMs for different use-cases, and to retain the original language and reasoning abilities when learning from recommender system data. To address these three limitations, we propose an Item-Language Model (ILM), which is composed of an item encoder to produce text-aligned item representations that encode user interaction signals, and a frozen LLM that can understand those item representations with preserved pretrained knowledge. We conduct extensive experiments which demonstrate both the importance of the language-alignment and of user interaction knowledge in the item encoder.
Read more6/6/2024