Enhancing Regression Models for Complex Systems Using Evolutionary Techniques for Feature Engineering

0
↗️
Sign in to get full access
Overview
- Proposes an automatic methodology for modeling complex systems
- Combines Grammatical Evolution and classical regression to obtain optimal feature set for a linear and convex model
- Provides Feature Engineering and Symbolic Regression to infer accurate models without designer expertise
- Focuses on power consumption modeling for cloud data centers, a complex challenge not yet satisfied by analytical approaches
Plain English Explanation
This research presents a new way to automatically create models for complex systems. It combines two techniques - Grammatical Evolution and classical regression - to find the best set of features that can be used in a simple, straightforward model.
The key innovation is that this approach can do the feature engineering and symbolic regression automatically, without needing a human expert to design the model. This is important because accurately modeling the power consumption of cloud data centers is a difficult problem, but having an automated system can help solve it.
Cloud data centers use 10-100 times more power per square foot than typical office buildings, so understanding their power usage is crucial for developing energy-efficient policies. However, accurately and quickly modeling the power of high-end servers has been a complex challenge that current analytical methods haven't fully addressed.
This new automated approach aims to provide a better solution by minimizing the error in power prediction. The researchers tested it on real cloud applications and achieved an average error of just 3.98% in power estimation. This demonstrates the potential for this technique to enable more energy-efficient policies for cloud data centers and potentially other computing environments with similar characteristics.
Technical Explanation
The researchers' methodology is based on combining Grammatical Evolution and classical regression techniques. Grammatical Evolution is used to automatically generate an optimal set of features that can be used in a linear and convex model. This provides both feature engineering and symbolic regression capabilities to infer accurate models without requiring expert input.
The researchers focused their case study on modeling the power consumption of cloud data centers, as these facilities have drastically higher power usage per square foot compared to typical office buildings. Accurately and rapidly modeling the power consumption of high-end servers in cloud environments is a complex challenge that existing analytical approaches have not fully solved.
Through testing on real cloud applications, the researchers' automated methodology achieved an average error in power prediction of just 3.98%. This demonstrates the potential for this technique to enable the development of more energy-efficient policies for cloud data centers and potentially other computing environments with similar characteristics.
Critical Analysis
The paper provides a detailed explanation of the researchers' automated modeling methodology and its application to the challenging problem of power consumption modeling for cloud data centers. However, the authors do not extensively discuss any caveats or limitations of their approach.
One potential area of concern is the generalizability of the technique. While the researchers achieved impressive results on their specific cloud applications, it is unclear how well the methodology would perform on a broader range of complex systems or computing environments. Further research may be needed to assess the robustness and adaptability of the approach.
Additionally, the paper does not deeply explore potential issues or biases that could arise from the automated feature engineering and symbolic regression process. It would be valuable to understand how the researchers ensure the interpretability and reliability of the final models produced by their methodology.
Overall, this work represents an innovative step towards more automated and accurate modeling of complex systems. However, further investigation into the limitations and edge cases of the technique could help strengthen the research and guide future development.
Conclusion
This research proposes an automated methodology that combines Grammatical Evolution and classical regression to model complex systems, with a focus on power consumption in cloud data centers. By automating both feature engineering and symbolic regression, the approach can generate accurate models without requiring expert input, which is a significant advantage for complex problems like high-end server power usage.
The researchers demonstrated the effectiveness of their technique by achieving an average error of just 3.98% in power prediction on real cloud applications. This suggests the potential for this methodology to enable the development of more energy-efficient policies for cloud data centers and potentially other computing environments with similar characteristics.
While the paper provides a thorough technical explanation of the approach, further research may be needed to assess its generalizability and address potential issues around model interpretability and reliability. Nevertheless, this work represents an important step forward in the quest for more automated and accurate modeling of complex systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
0
Enhancing Regression Models for Complex Systems Using Evolutionary Techniques for Feature Engineering
Patricia Arroba, Jos'e L. Risco-Mart'in, Marina Zapater, Jos'e M. Moya, Jos'e L. Ayala
This work proposes an automatic methodology for modeling complex systems. Our methodology is based on the combination of Grammatical Evolution and classical regression to obtain an optimal set of features that take part of a linear and convex model. This technique provides both Feature Engineering and Symbolic Regression in order to infer accurate models with no effort or designer's expertise requirements. As advanced Cloud services are becoming mainstream, the contribution of data centers in the overall power consumption of modern cities is growing dramatically. These facilities consume from 10 to 100 times more power per square foot than typical office buildings. Modeling the power consumption for these infrastructures is crucial to anticipate the effects of aggressive optimization policies, but accurate and fast power modeling is a complex challenge for high-end servers not yet satisfied by analytical approaches. For this case study, our methodology minimizes error in power prediction. This work has been tested using real Cloud applications resulting on an average error in power estimation of 3.98%. Our work improves the possibilities of deriving Cloud energy efficient policies in Cloud data centers being applicable to other computing environments with similar characteristics.
Read more7/2/2024
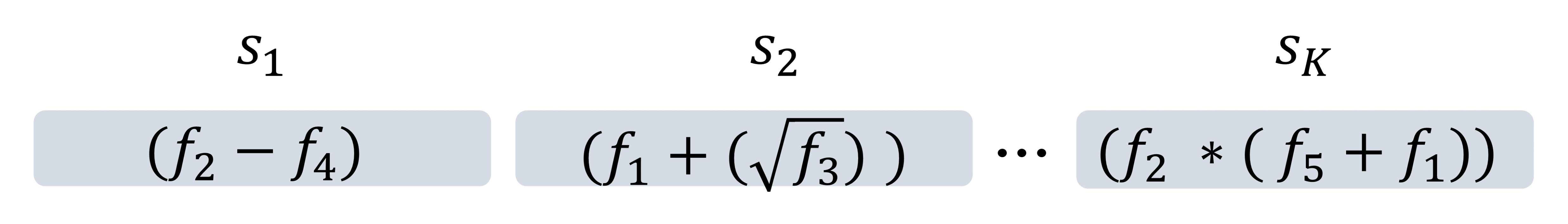
0
Evolutionary Large Language Model for Automated Feature Transformation
Nanxu Gong, Chandan K. Reddy, Wangyang Ying, Yanjie Fu
Feature transformation aims to reconstruct the feature space of raw features to enhance the performance of downstream models. However, the exponential growth in the combinations of features and operations poses a challenge, making it difficult for existing methods to efficiently explore a wide space. Additionally, their optimization is solely driven by the accuracy of downstream models in specific domains, neglecting the acquisition of general feature knowledge. To fill this research gap, we propose an evolutionary LLM framework for automated feature transformation. This framework consists of two parts: 1) constructing a multi-population database through an RL data collector while utilizing evolutionary algorithm strategies for database maintenance, and 2) utilizing the ability of Large Language Model (LLM) in sequence understanding, we employ few-shot prompts to guide LLM in generating superior samples based on feature transformation sequence distinction. Leveraging the multi-population database initially provides a wide search scope to discover excellent populations. Through culling and evolution, the high-quality populations are afforded greater opportunities, thereby furthering the pursuit of optimal individuals. Through the integration of LLMs with evolutionary algorithms, we achieve efficient exploration within a vast space, while harnessing feature knowledge to propel optimization, thus realizing a more adaptable search paradigm. Finally, we empirically demonstrate the effectiveness and generality of our proposed method.
Read more5/28/2024

0
Accelerating evolutionary exploration through language model-based transfer learning
Maximilian Reissmann, Yuan Fang, Andrew S. H. Ooi, Richard D. Sandberg
Gene expression programming is an evolutionary optimization algorithm with the potential to generate interpretable and easily implementable equations for regression problems. Despite knowledge gained from previous optimizations being potentially available, the initial candidate solutions are typically generated randomly at the beginning and often only include features or terms based on preliminary user assumptions. This random initial guess, which lacks constraints on the search space, typically results in higher computational costs in the search for an optimal solution. Meanwhile, transfer learning, a technique to reuse parts of trained models, has been successfully applied to neural networks. However, no generalized strategy for its use exists for symbolic regression in the context of evolutionary algorithms. In this work, we propose an approach for integrating transfer learning with gene expression programming applied to symbolic regression. The constructed framework integrates Natural Language Processing techniques to discern correlations and recurring patterns from equations explored during previous optimizations. This integration facilitates the transfer of acquired knowledge from similar tasks to new ones. Through empirical evaluation of the extended framework across a range of univariate problems from an open database and from the field of computational fluid dynamics, our results affirm that initial solutions derived via a transfer learning mechanism enhance the algorithm's convergence rate towards improved solutions.
Read more6/11/2024
0
Sharpness-Aware Minimization for Evolutionary Feature Construction in Regression
Hengzhe Zhang, Qi Chen, Bing Xue, Wolfgang Banzhaf, Mengjie Zhang
In recent years, genetic programming (GP)-based evolutionary feature construction has achieved significant success. However, a primary challenge with evolutionary feature construction is its tendency to overfit the training data, resulting in poor generalization on unseen data. In this research, we draw inspiration from PAC-Bayesian theory and propose using sharpness-aware minimization in function space to discover symbolic features that exhibit robust performance within a smooth loss landscape in the semantic space. By optimizing sharpness in conjunction with cross-validation loss, as well as designing a sharpness reduction layer, the proposed method effectively mitigates the overfitting problem of GP, especially when dealing with a limited number of instances or in the presence of label noise. Experimental results on 58 real-world regression datasets show that our approach outperforms standard GP as well as six state-of-the-art complexity measurement methods for GP in controlling overfitting. Furthermore, the ensemble version of GP with sharpness-aware minimization demonstrates superior performance compared to nine fine-tuned machine learning and symbolic regression algorithms, including XGBoost and LightGBM.
Read more5/14/2024